热门
让你的文档从静态展示到一键部署可操作验证
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
子域名和主域名的区别
云计算中的弹性是什么?
ECS体验
ECS使用体验
编程之路上的飞跃:那些让我技能显著提升的关键概念与技术
事件驱动架构在云时代的再度流行
内存
什么是 NLP (自然语言处理)?
默认值
Linux权限管理
成员变量
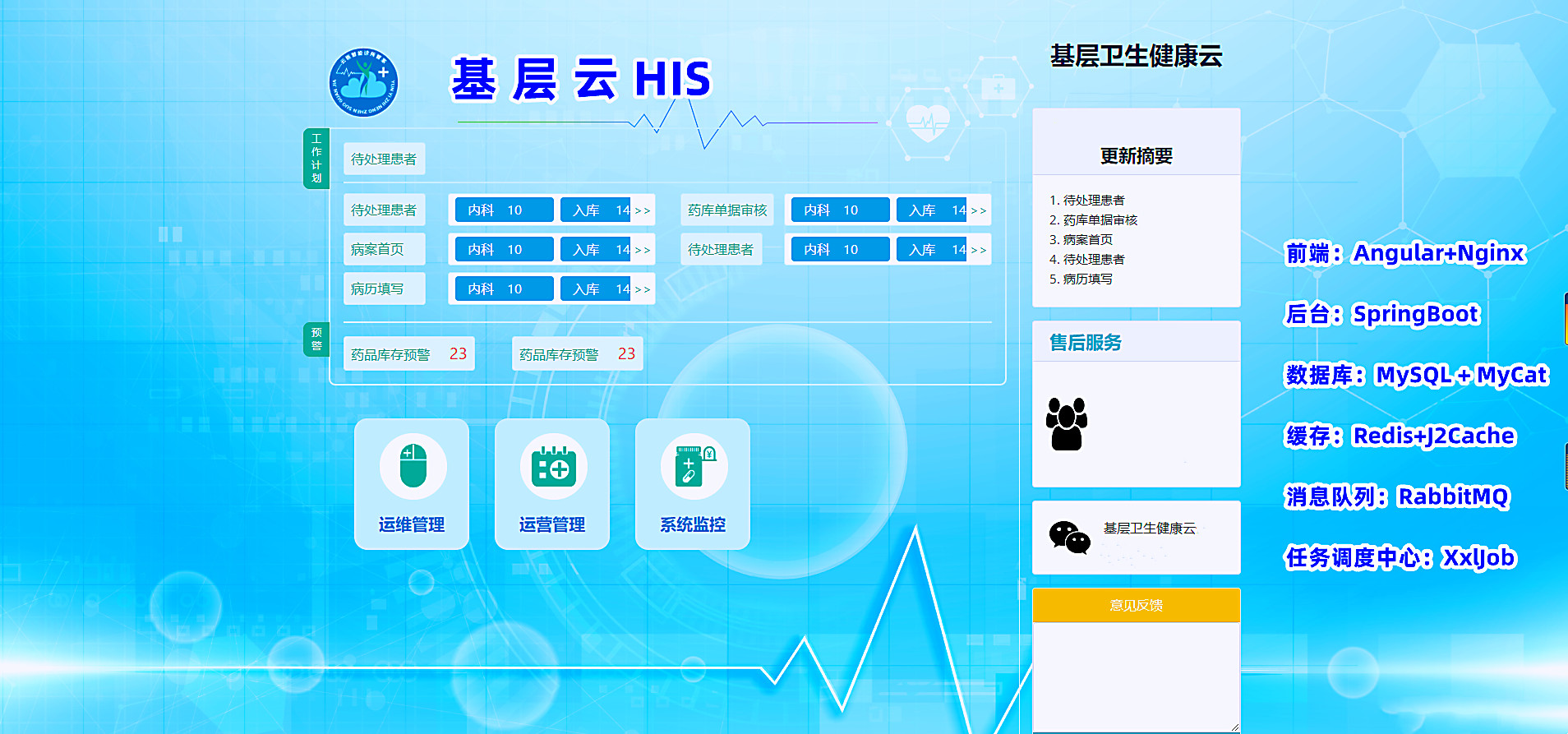
Java版HIS系统 云HIS系统 云HIS源码 结构简洁、代码规范易阅读
css样式
Python中的装饰器:提升代码灵活性与可维护性
使用Python构建简单的图像识别应用
Python中的装饰器:优雅地增强函数功能
Kafka【部署 03】Zookeeper与Kafka自动部署脚本
ZooKeeper【基础知识 04】控制权限ACL(原生的 Shell 命令)
ZooKeeper【基础 03】Java 客户端 Apache Curator 基础 API 使用举例(含源代码)
优化Python代码的五大技巧
探索Python中的异步编程:从回调到async/await
Servlet 教程 之 Servlet 服务器 HTTP 响应 1
Servlet 教程 之 Servlet 客户端 HTTP 请求 3
《Python中的装饰器:提升代码可读性与复用性》
Servlet 教程 之 Servlet 客户端 HTTP 请求 2
深入理解自动化测试框架Selenium的设计与实现
css的类型
css元素
css基本结构
使用Python实现时间序列预测模型
JavaScript的数据类型主要分为两大类:基本数据类型和引用数据类型
JavaScript的基本语法是编程的基础
js的基本属性
C#编程入门:从零开始的旅程
探索 C#编程的奥秘与魅力
掌握 C#编程:关键技术与实践
深入了解 C#编程的核心概念
C#编程实战:项目案例分析
2023年上半年信息系统项目管理师___综合知识真题与答案解释(2)
提升 C#编程效率的技巧与方法
Java基础教程(11)-Java中的集合类
C#编程中的错误处理与调试
优化 C#编程性能的策略
C#编程与数据库交互的实现
.waitKey(0)
中文路径优化
cvtColor
如何使用Python的Plotly库创建交互式图表?