几天前我发过一篇《AMD EPYC服务器OS兼容注意事项》,正好又看到份资料,引发了我的一些思考。由规格参数倒推CPU的设计不见得是种高效的方式,但分享给大家可能也是个有意思的过程,如果我哪里猜的不对也欢迎朋友们指出。
下图是动笔写之前临时加进来的,看完本文您应该会发现,我要讨论的内容与具体哪家服务器的关系并不大。

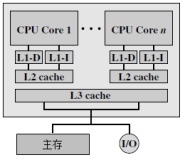
很早就听朋友说EPYC是MCM“胶水封装”,AMD这款处理器使用了4个基于Ryzen的SoC/Die,具体点说就是每个Die都相当于SoC,都带有内存和PCIe控制器。
Socket/Die/Channel:解读三种NUMA设置

上图示意出了4个Die(每Die最多8核)与内存通道、IO之间的对应关系,这里的IO没有区分用于PCIe还是CPU之间互连。

对服务器BIOS里NUMA设置熟悉的朋友,应该都见过Interleave(交错)这个选项。按照传统设计的CPU,“Node Interleave”就意味着关闭NUMA优化(玩数据库的一些朋友熟悉这个吧),而到了AMD EPYC我们看到了3个不同的Interleave选项。
Socket Interleave——相当于Intel Xeon的Node Interleave,也就是NUMA彻底关闭。在单插槽AMD EPYC配置下该选项不可用,而在双CPU时选择这一项就意味着系统只有1个NUMA节点。
Die Interleave——由于前面提到的设计,AMD EPYC片上多Die连接的内存有就近和局部访问优化的关系,所以就多出了一级NUMA设置。如果选择这一项,就意味着(部分)启用插槽间的NUMA优化,但在每颗CPU上的4个Die之间关闭NUMA。
Channel Interleave——这是只在每个Die的2个内存通道间交错存取,多个Die、插槽间全部启用NUMA优化。此时对于单颗AMD EPYC相当于4个NUMA Node,两颗CPU这个数字就是8。
Fabric互连速率、位宽与功耗之间的关系

上面这个表我一开始没看太明白,后来才发现它讲的是内存总线速度与Infinity Fabric Speed之间的对应关系,类似于固定的“倍频”。那么为什么同一颗CPU上Die之间的互连速率,要比插槽间互连的的速率慢一倍呢?
看看《AMD EPYC官方资料乌龙?谈服务器CPU互连效率》一文中的两张图,我来试着给大家解释下:

上面写的每条Die间互连42GB/s双向带宽(单个方向为一半),除以5.3GT/s不难算出MCM link的信道宽度是32bit。如此每个Die共有96对(192)引脚用于片上互连。

至于插槽间的互连,在每2个Die之间是38GB/s的双向总带宽,这里似乎我拿9.6GT/s才能整除,可计算出该link的信道宽度是16bit。这样4个Die总和64 lane正好等于从128 lane PCIe控制器“挪用”过来的一半。
那么既然跨插槽能做到10.6GT/s,为什么不把跨Die连接也设为这个速率来加快片上通信呢?我觉得是为了平衡功耗,跨插槽互连的能耗比为9pj/bit,而片上跨Die只有2pj/bit。
我们不妨广义地理解AMDEPYC的每个Die有4个32bit Fabric I/O接口,其中3个用于Die间互连;只有一个用于PCIe,或者再分出一半给插槽间互连。Die间有相对充足的信道宽度,所以选择了降低频率以控制整个MCM封装的功耗。
服务器BIOS示例、PCIe插槽NUMA亲和

上图以Dell PowerEdgeR7425双路服务器为例,经过前面的介绍大家应该知道“Channel Interleaving”选项在这里的含义,即最大(8 Node)NUMA优化。

注:当选择在服务器后侧增加3.5英寸磁盘位,PCIe插槽的数量会受到影响。
上表是另外一款R7415单路服务器PCIe插槽,与CPU Die/NUMA Node、内存插槽之间的对应关系。由于该机型最多支持24个U.2 NVMe SSD,所以AMDEPYC PCIe控制器中应该有一部分被预留给了驱动器背板。
在软件设计上,如果想要发挥NUMA最大的效率,比如Embedded LOM网卡直接连在CPU Die 2上,它访问同一NUMA Node所属的内存插槽(A7,A8,A15,A16)延时就是最低的。

上图是不带后侧热插拔驱动器位的R7415,此时除了贴近主板的LOM网卡之外,还有2个全高PCIe和2个半高PCIe扩展槽位。
参考资料:《Directfrom Development – PowerEdge NUMA Configurations with AMD EPYC Processors》
http://en.community.dell.com/techcenter/extras/m/white_papers/20444763/