ResNet论文笔记
一、论文简介
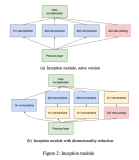
先从Kaiming He的那篇paper说起吧,paper主要解决的还是神经网络的深度和准确率之间的关系,当神经网络的层数增加,出现了degradation,trainging error和test error都会增加,针对这种退化问题,作者提出了Residual block的结构:
下面这段话对这个block进行了理论解释:
In this paper, we address the degradation problem by introducing a deep residual learning framework. Instead of hoping each few stacked layers directly fit a desired underlying mapping, we explicitly let these layers fit a residual mapping. Formally, denoting the desired underlying mapping as H(x), we let the stacked nonlinear layers fit another mapping of F(x) := H(x)−x. The original mapping is recast into F(x)+x. We hypothesize that it is easier to optimize the residual mapping than to optimize the original, unreferenced mapping. To the extreme, if an identity mapping were optimal, it would be easier to push the residual to zero than to fit an identity mapping by a stack of nonlinear layers.
理解一下就是,先对比较难以拟合的目标映射H(x),我们去fit一个F(x)=H(x)-x(此时H(x)=F(x)+x),作者假设这个映射更容易拟合,考虑一下极限情况,对一个恒等映射,我们只需要把F(x)push到0,就可以得到我们的H(x),而不用靠非线性神经网络去拟合原本的恒等映射。
接下来,为了实现F(x)+x,我们用一个shortcut connection,将恒等映射x直接加到神经网络的output,然后再用SGD进行训练。
二、实验
接下来作者在ImageNet和Cifar10上做了一系列的对比实验,将plain network和residual network在不同层数进行对比。我这里出于硬件的限制,只在Cifar10上做了几个实验,epochs也远远比不上paper里的64k,不过总体还算符合了论文的结果。
我的结果:Resnet20:88.41%的test acc,比paper91.25低了不少,对比了一下和原作的差距,按重要性我总结了三个原因:1、data augmentation上原作对所有的图片进行了size2的zero padding,然后在镜像或者原图随机取了32×32,我这里用的是mxnet,在api里没找到对image进行zero padding的函数,就直接crop了28×28,test set 也都crop了28×28,对结果影响还是蛮大的,最后的overfitttng比较严重也侧面说明了data augmentation还是比较影响了结果的。2、epochs的差距,我这里只训练了200个epochs,分别在1/2和3/4的地方将lr乘了0.1。3、在卷积过程中会遇到dimension increase,paper里提供了两个选择去解决这个问题,一个是他采用的zero padding多余的维度,第二种就是我采用的用1×1的卷积核去进行维度的增加操作。原文是这么写的: When the dimensions increase (dotted line shortcuts in Fig. 3), we consider two options: (A) The shortcut still performs identity mapping, with extra zero entries padded for increasing dimensions. This option introduces no extra parameter; (B) The projection shortcut in Eqn.(2) is used to match dimensions (done by 1×1 convolutions). For both options, when the shortcuts go across feature maps of two sizes, they are performed with a stride of 2.
当然除了这三个,我还注意到了bn层的位置的问题,原文里是这么说的:We adopt batch normalization (BN) [16] right after each convolution and before activation, following [16].
[16] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML, 2015.这里写了在每次卷积之后,激活之前。那么我们这里可以得到了卷积,bn,激活三个层的顺序,但是由于residual block里加入了一个与恒等映射相加的操作,那么等于是要在卷积,bn,激活三层中插入,问题来了,到底放在哪儿呢,作者后来又发了一篇paper专门讲这个问题:Identity Mappings in Deep Residual Networks,做了实验进行对比,得到了下面这张图:
里面效果最好的还是e:full pre-acticvation,也就是把identity mapping放在了最后。
下面讲一下我自己做实验遇到的问题以及是如何解决的吧,首先参数都是按照paper里设置的:We use a weight decay of 0.0001 and momentum of 0.9, and adopt the weight initialization in [13] and BN [16] but with no dropout. These models are trained with a minibatch size of 128 on two GPUs. We start with a learning rate of 0.1, divide it by 10 at 32k and 48k iterations, and terminate training at 64k iterations, which is determined on a 45k/5k train/val split.当然这里的64k的epochs我换成了自己设置的,这也导致了问题的产生。
这是第一次的图片,y轴label是test_acc开始打错了。。。图中可以看到效果是44>32>56>20,当时有预感应该是epochs太少了,所以又做了一次epochs200的,如下图,可以看到效果好了点:
这里我对比了一下两张图,感觉在epochs到1/2处学习率可能还是太大了,如果动一下应该能弥补一下epochs太少的问题,为了验证我的猜想,我在原参数的0.1,0.1×0.1,0.1×0.1×0.1修改了一下变成0.1,0.1×0.05.0.1×0.05×0.05,并跑了一次epochs=100看了一下效果:
事实证明效果好了很多,因此我直接令epochs=256分别在plain net和residual net上跑了一下进行了对比,基本达到了paper里的效果,也就是对于ResNet,层数越多,效果越好,对于plain net,层数越多,效果越差。