这篇文章打算教你使用强化学习中的Q-learning算法,让电脑精通一个简单的游戏。文中代码所用语言是Ruby。
为了展示算法内部的工作机制,我们将会教它去玩一个非常简单的一维游戏。当然这个算法也可以被应用于更复杂的游戏中。
游戏介绍
我们的游戏叫做“抓住芝士”,玩家P需要移动到芝士C那里(抓住它!),同时不能落入陷阱O中。
每抓到一块芝士,玩家就会得一分,而每次落入陷阱,玩家就会减一分。当玩家得分达到5分或者-5分时游戏结束。下面的动画展示的是一个人类玩家玩游戏的过程。
请注意,为了简化这个游戏,所有的陷阱O和芝士C的位置都是不变的。你可以从这里找到关于游戏的Ruby源代码以及相应Q-learning算法的实现过程:
https://github.com/daugaard/q-learning-simple-game
Q-learning算法
Q-learning是一种强化学习算法。强化学习是指受到行为心理学启发的一系列机器学习方法,它的前提是你可以通过奖励或惩罚行为来教会算法在之前经验的基础上采取特定的行动。这跟用食物奖励教会狗狗坐好是一个道理。
Q-learning算法通过在表格中记录游戏中所有可能的状态,和这些状态下玩家可能的行为来运作。对于每个游戏状态S和玩家行为A,表格中记录的数值Q代表着在S状态下采取行为A可能获得的奖励。这意味着为了能够得到最大奖励,在特定状态下,只需要依据表格采取拥有最大潜在奖励的行为。
现在我们来看一下上面描述的那个游戏。
根据玩家所处的位置,这个游戏一共有12种可能的状态(重申一下:陷阱和芝士的位置是不变的),在每个状态下玩家可以采取的行动就是向左或者向右。
Q值表格看起来像是下面这样,注意这只是我们这个问题下Q表格一种可能的形式,其中的数值可能跟实际有出入。
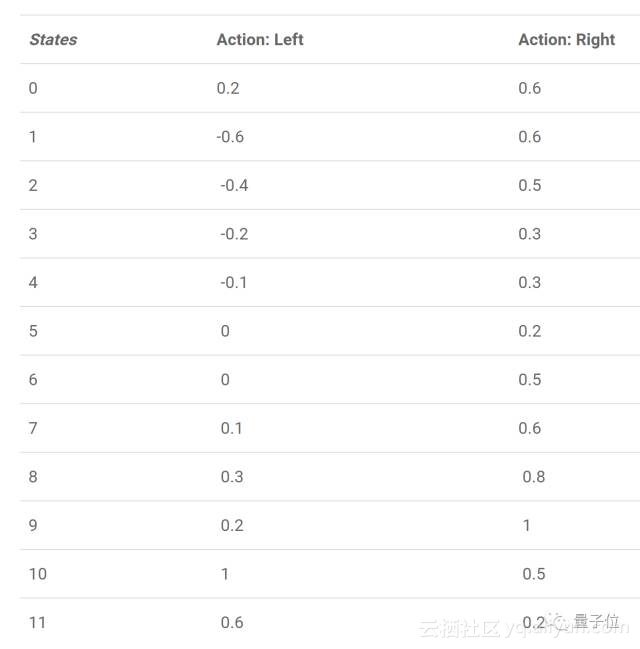
你可以从Q值表格中看出,当里在采取向左的行为、靠近陷阱时,玩家会得到负面的奖励;而向右走、靠近芝士时,玩家可能会得到正面的奖励。
Q值表格的初始化就是指将表格中所有的Q值随机赋值,这象征着在初始阶段AI对游戏没有任何了解。为了让它学会如何玩这个游戏,我们必须设计出一个能够根据经验不断更新Q值表格的算法。
我们采取的步骤如下:
第1步:初始化Q值表格,随机赋值
第2步:在游戏进行中反复执行以下操作:
2a) 从0到1中生成一个随机数 — 如果数字大于阈值e,选择随机行为,否则就依据Q值表格选择当前状态下奖励最大的行动。
2b) 采取2a中选择的行动
2c) 在行动完成后得到奖励r
2d) 结合下式和奖励r更新Q值表格

可以看出,更新Q值表格的过程中将会使用新得到的当前状态和行为的奖励信息,以及未来可能采取的行为的相关信息,但这不需要遍历未来所有的可能得到,只需Q表格就能完成。这使得Q-learning成为一个相当快速的学习算法,但同时也意味着算法一开始会采取一些随机的行为,所以在玩过几局游戏之前,不要对你的AI有任何指望。
搭建一个Q-learning AI player class
我们游戏通常使用human player class(人类玩家)作为玩家。human player class的搭建过程如下所示,class通过两个函数运行:构造器函数(constructor)和get_input函数。
get_input函数在游戏进行中的每一次迭代中都会被调用,然后依据键盘上的输入返回玩家行动的方向。

为了构造Q-learning AI player class,我们将会使用一个新的class,包括Q值表格和基于上述算法的get_input函数。
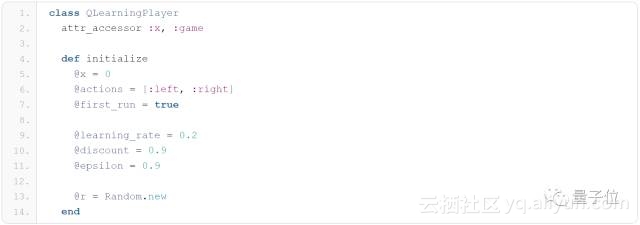
如下所示,我们定义了这个新class和它的构造器。注意这里我们新定义了一个attribute/特性: game。这被用来在Q-learning算法中记录游戏得分,从而更新Q值表格。
此外,在构造器中我们为每个在上述算法中列出的学习参量定义了attribute,然后初始化我们的随机数生成器。
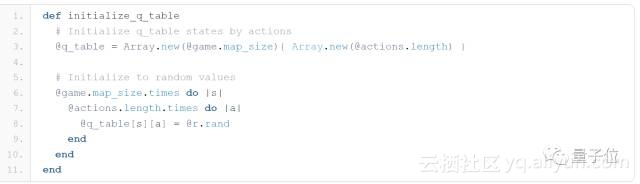
下一步,我们将定义一个函数负责用随机数初始化Q值表格。状态的数量用游戏的map_size表示,每个状态即对应着一个玩家的位置。
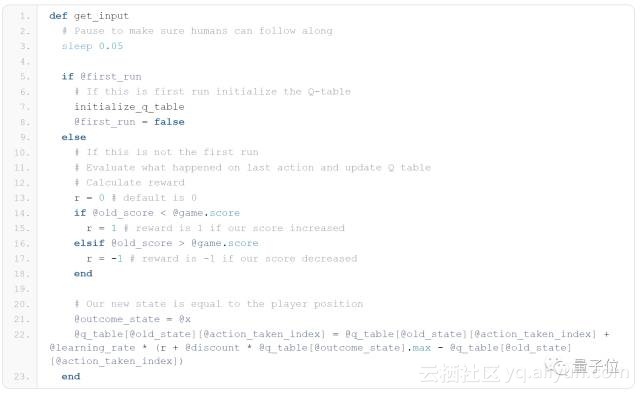
最终,我们采用了如下所示的get_input函数。首先,停顿0.05秒,保证我们能够看清AI玩家移动的步骤。
随后我们将会检查这是否是程序第一次运行,如果是的话就对Q值表格进行初始化。(步骤1)
如果不是第一次运行,那么我们就对游戏进行评估,因为从上一次游戏的结果中就能得到Q-learning算法所需要的输入——奖励r。如果游戏的得分增加了,那么得到的奖励为1;如果得分减少了,得到的奖励为-1;得分不变奖励为0.(步骤2c)
接着我们把结果状态设置为游戏的当前状态(在我们的例子中即为移动玩家),然后使用下式更新我们的Q值表格。(步骤2d)

在上述最后一步更新过Q值表格后,我们为下一次运行保留之前的分数和状态。
然后我们依据阈值e,从随机或者基于Q值表格选择出一个行为(步骤2a),函数返回这个行为(步骤2b)。

这就完成了我们Q-learning算法的实现,你可以从上文中的github地址里看到有关算法和游戏的所有源码。
算法的运行
我们让Q-learning玩家进行了10次游戏,结果如下:
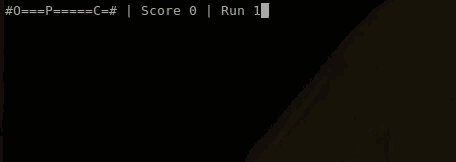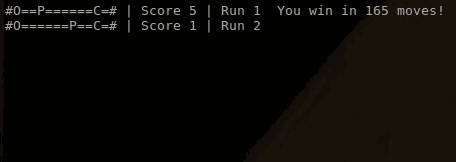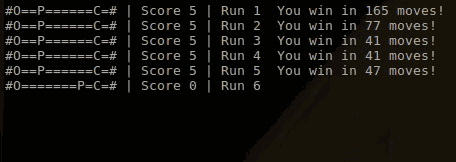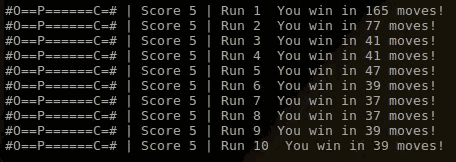
你可以看出在第1次游戏中,玩家还在不断尝试,包括漫无目的地左右移动。这是由于Q值表格的随机初始化导致的。然而当玩家得到一些分数、落入一些陷阱后,它很快就学会了如何避免陷阱,径直走向芝士。
在第7次和第8次游戏运行中,玩家事实上采取了最优的获胜方案,在37步移动中得到了5次芝士。
然后在第9次和第10次游戏中,获胜经历的总步数又变成了39步。这是由阈值e影响的,它的存在会使得算法有时候会采取随机移动,而不是采用优化的移动。这种随机性的设置会非常有必要的,它能够保证算法能够正确地探索整个游戏,而不被局域最优值卡住。
接下来…
这篇推送展示了如何将使用Q-learning来教会AI去玩“抓住芝士”这个简单的游戏。你可以想象,随着游戏复杂的提升,Q制表格的大小将会呈现爆炸式增长。一种避免这种情况发生的方法就是把Q值表格替换为一个神经网络。
DeepMind的研究者们探索了这种方法,发表了相关的论文。这这篇文章中,他们成功使用了神经网络通过Q-learning来训练AI去玩Atari出品的2600种游戏。
论文:
Playing Atari with Deep Reinforcement Learning
地址:
https://www.cs.toronto.edu/~vmnih/docs/dqn.pdf
— 完 —
