实时计算 Flink SQL 核心功能解密
Flink SQL 是于2017年7月开始面向集团开放流计算服务的。虽然是一个非常年轻的产品,但是到双11期间已经支撑了数千个作业,在双11期间,Blink 作业的处理峰值达到了5+亿每秒,而其中仅 Flink SQL 作业的处理总峰值就达到了3亿/秒。Flink SQL 在这么短的时间内支撑了如此多的业务,与其稳定的内核、完善的功能、强大的生态是分不开的。
本文会带着大家一起来揭开 Flink SQL 核心功能的面纱(API上我们将尽可能的和Flink社区保持一致,这样才能够更好的融入开源的生态,所以我们将API叫做Flink SQL,而不是Blink SQL。事实上flink社区的SQL绝大部分是我们阿里的工程师贡献的:3个 Flink Committer,10+ Contributor,贡献 80% 的SQL 功能,近200个 commit,近十万行的代码)。
为什么是 SQL?
Blink 将 SQL 定位为其最核心的 API。为什么是 SQL 而不是 DataStream API 呢?因为 SQL 具有以下几个优点:

- 声明式。用户只需要表达我想要什么,至于怎么计算那是系统的事情,用户不用关心。
- 自动调优。查询优化器可以为用户的 SQL 生成最有的执行计划。用户不需要了解它,就能自动享受优化器带来的性能提升。
- 易于理解。很多不同行业不同领域的人都懂 SQL,SQL 的学习门槛很低,用 SQL 作为跨团队的开发语言可以很大地提高效率。
- 稳定。SQL 是一个拥有几十年历史的语言,是一个非常稳定的语言,很少有变动。所以当我们升级引擎的版本时,甚至替换成另一个引擎,都可以做到兼容地、平滑地升级。
- 流与批的统一。Blink 底层 runtime 本身就是一个流与批统一的引擎。而 SQL 可以做到 API 层的流与批统一。
我们认为这 5 点对于用户的易用性是非常重要的,而以上 5 点却是 DataStream API 所不具备的。所以 Blink 将 SQL 定位为最核心的 API,而不是 DataStream API。
关于流与批的统一是现在业界非常火热的一个话题,Flink SQL 的流与批统一总结起来就一句话:One Query, One Result。在很多场景,我们既需要批处理,又需要流处理。比如,使用批处理一天跑一个全量,同时使用流处理来做实时的增量更新。在以前经常需要维护两套引擎,写两个 Job,两个 Job 之间还要维护逻辑的一致性,这增加了很多的工作量。如果使用 SQL 的话,我们可以让一份 SQL 代码既跑在批模式下,又跑在流模式下,这样用户只需要维护一份 SQL 代码,这是 One Query。而 One Result 是说,同一份 SQL 代码,在流模式下和批模式下跑出来的结果是一样的,也就是保证了流式 SQL 的语义正确性。
我们注意到 SQL 是为传统批处理设计的,不是为流处理设计的。比如说传统 SQL处理的数据是有限的,而且SQL查询只返回一个结果并结束。但是流上的查询,处理的数据是无限的,不断产生结果且不会结束。所以说传统 SQL 标准中很多定义无法直接映射到流计算中。那么如何在流上定义 SQL 呢?这里需要引出 Flink SQL 的核心概念:流与表的二象性。
Flink SQL 核心概念
动态表 & 流表二象性
传统的 SQL 是定义在表上的,为了能在流上定义 SQL,我们也需要有一个表的概念。这里就需要引入一个非常重要的概念:动态表(Dynamic Table)。所谓动态表,就是数据会随着时间变化的表,可以想象成就是数据库中一张被不断更新的表。我们发现流与表有非常紧密的关系,流可以看做动态表,动态表可以看做流。我们称之为流表二象性(duality)。
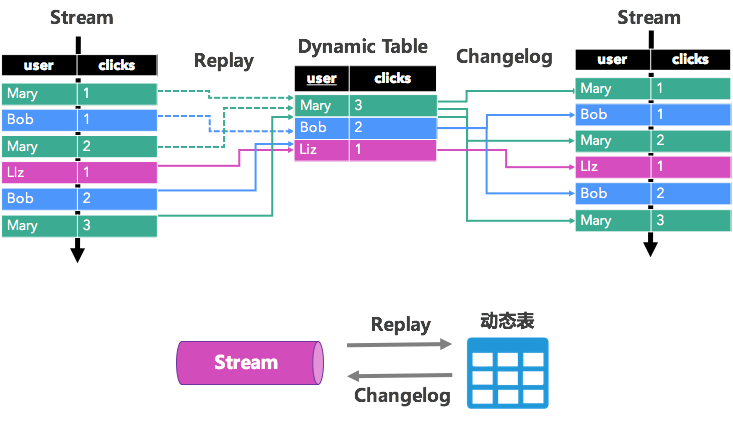
如上图所示,一个流可以看做对表的一系列更新操作(changelog),将流从头开始重放就可以构造成一个动态表。而动态表的每次更新操作都会记录下 changelog,通过抽取出动态表的 changelog 可以很轻松地得到原始的数据流(类似的思想也被应用于数据库同步中,如集团的DRC产品)。因此流可以转换成动态表,动态表又能转成流,他们之间的转换不会丢失任何信息,且保留了一致的 schema。流是动态表的另一种表现形式,动态表也是流的另一种表现形式,所以说流与表是一种二象性的关系。
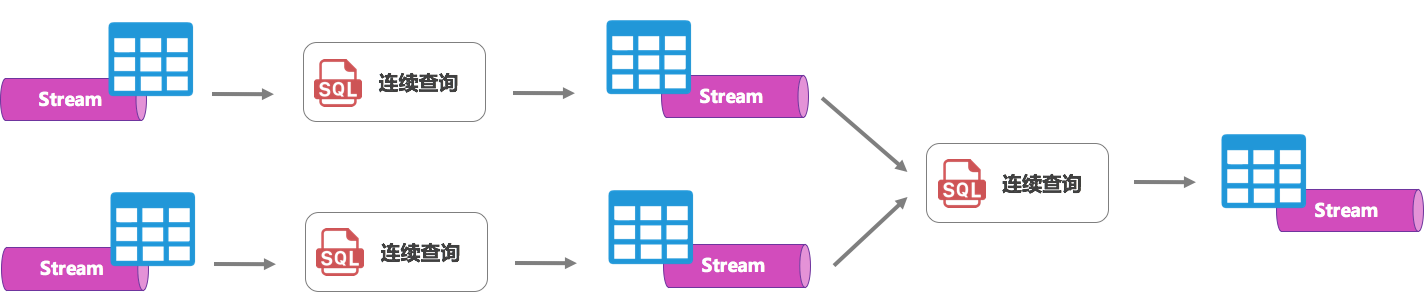
连续查询
上文说到动态表是流的另一种表现形式,有了动态表后,我们就可以在流上定义 SQL 了。流式 SQL 可以想象成连续查询(Continuous Query)。传统的查询是只运行一次 SQL,产生一个结果就结束了。连续查询会一直运行在那里,当每个数据到来,都会持续增量地更新计算结果,从而产生另一个动态表。而这个结果动态表(也就是流)会作为另一个 SQL(连续查询)的输入接着计算,从而串起整个数据流图。
Flink SQL 核心功能
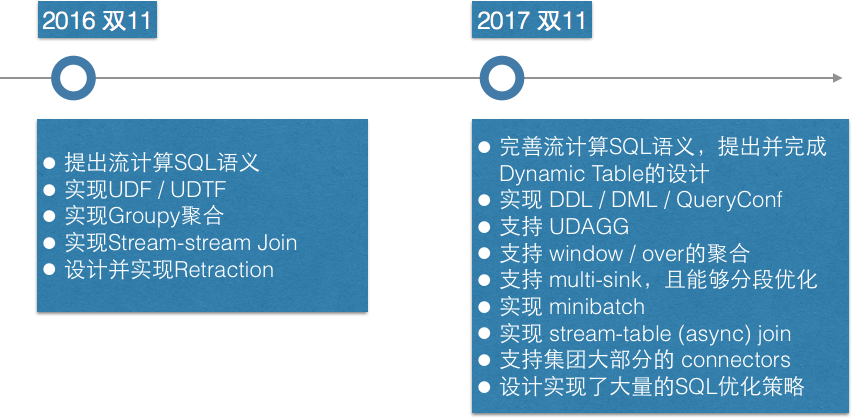
从 2016 年到 2017 年,Flink SQL 从无到有,迅速发展,解决多个 Stream SQL 领域的难点痛点,快速支持业务的需求。终于在今年的双11,Flink SQL 支撑了大量的双11业务,这与其丰富的上下游系统、完善的功能是离不开的,包括双流 JOIN,维表 JOIN,TopN,Window,多路输出等等。
打通集团上下游系统
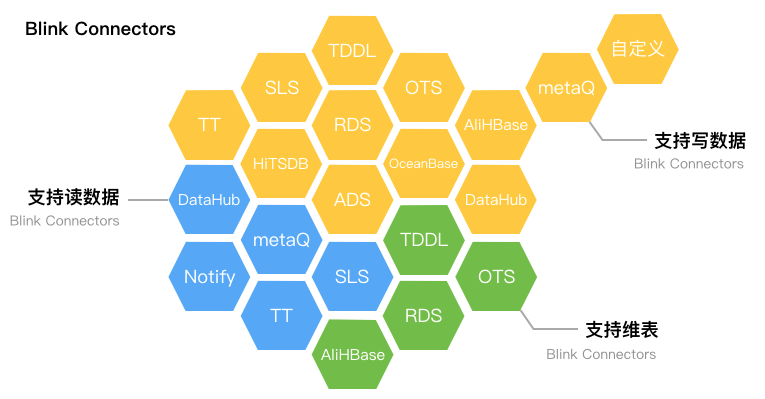
Flink SQL 接入了集团内常见的十多种上下游系统,包括了11种结果表插件、5种源表插件、4种维表插件。只需要声明对接系统的类型,就能完成上下游系统的连接,将你从阿里云存储五花八门的 SDK 中解放出来。详见《Flink SQL 功能解密系列 —— 阿里云流计算/Blink支持的connectors》
高级功能
-
双流 JOIN
双流 JOIN 功能是将两条流进行关联,用来补齐流上的字段。双流 JOIN 又分为无限流的双流 JOIN 和带窗口的双流 JOIN。
-
维表 JOIN
维表 JOIN 功能是流与表的关联,也是用来为数据流补齐字段,只是补齐的维度字段是在外部存储的维表中的。我们为维表 JOIN 做了诸如 Async、cache、multi-join-merge 等优化,使得维表 JOIN 的性能非常优异。具体原理分析和最佳实践可以阅读《Flink SQL 功能解密系列 —— 维表 JOIN 与异步优化》
-
TopN
TopN 是统计报表和大屏非常常见的功能,主要用来实时计算排行榜。除了全局 TopN 功能外,我们还提供了分组 TopN 的功能。流上的 TopN 有非常多的挑战。具体原理分析和实践推荐阅读《Flink SQL 功能解密系列 —— 流式 TopN 的挑战与实现》
-
Window
Flink SQL 简单易用的一大特色就是支持开箱即用的 Window 功能。支持滚动窗口(Tumble)、滑动窗口(Hop)、会话窗口(Session)以及传统数据库中的OVER窗口。具体使用方式可以阅读《Window 文档》
-
多路输入、多路输出
Flink SQL 利用分段优化支持了多路输出,并且多路输出的共享节点做到了资源的复用,使得不会计算多次。基于多路输入、多路输出的功能,可以将 Flink SQL 作为一个非常简单易用的画数据流的工具,可以很容易地构造出一个有流合并、流拆分的复杂 DAG 作业。
-
MiniBatch 优化
除此之外,我们还在 SQL 上做了很多的优化。其中 MiniBatch 就是核心优化之一。对于有状态的算子来说,每个进入算子的元素都需要对状态做序列化/反序列化的操作,频繁的状态序列化/反序列化操作占了性能开销的大半。MiniBatch 的核心思想是,对进入算子的元素进行攒批,一批数据只需要对状态序列化/反序列化一次即可,极大地提升了性能。详细的原理实现推荐阅读《Flink SQL 功能解密系列 —— 解决热点问题的大杀器 MiniBatch》
-
Retraction 撤回机制
撤回机制是 Flink SQL 中一个非常重要的基石,它解决了 early-fire 导致的结果正确性问题(所有的 GroupBy 都是 early-fire 的)。而利用好撤回机制有时候能够很巧妙地帮助业务解决一些特殊需求。详细的业务应用分析推荐阅读《Flink SQL 功能解密系列 —— 流计算“撤回(Retraction)”案例分析》
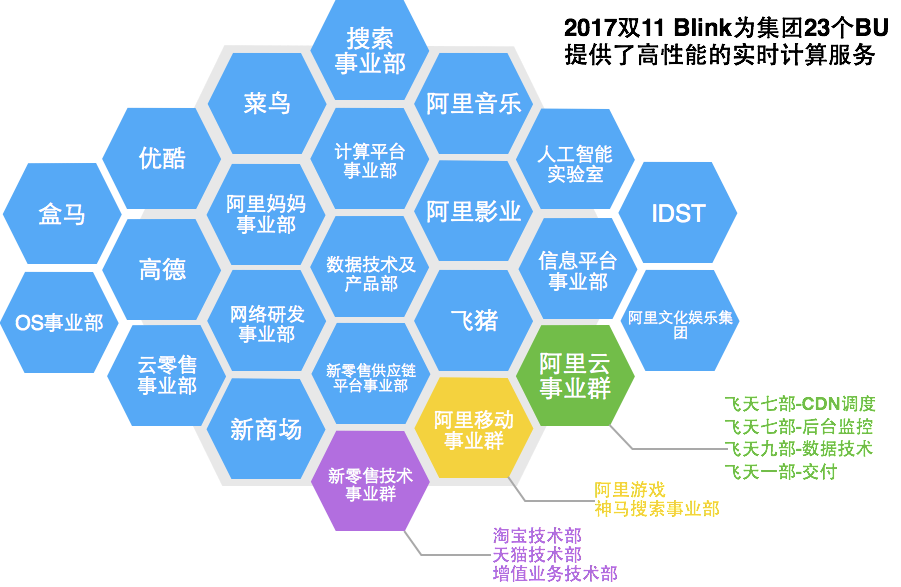
业务支持情况
借助于阿里云一站式开发平台,用户可以高效地开发 Flink SQL 作业,是业务上线与业务迁移的加速器。目前 Flink SQL 在集团内部已经服务于 双11回血红包、聚划算、飞猪、菜鸟、盒马、云零售、反作弊等数十个业务场景,二十多个 BU,并成功经历双11大促的考验。在双11当天,Flink SQL 的作业更是创下了每秒2.9亿条的处理高峰。为各个业务取得了非常好的效果提供了非常坚实的保障。