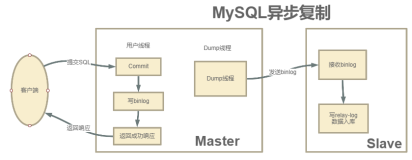
主从复制不一致的情况解决:
Start slave until MASTER_LOG_FILE=’’, MASTER_LOG_POS=;
直到sql_thread线程为NO,这之间的同步报错一律跳过即可
操作前,最好先备份。对于主从结构来讲,它只需要在master上操作即可(无论是 使用的选项是 –reolicate 还是 –sync-to-master)这种方式往往是重新让master和slave保持同步的最安全的方式,直接修改replica可能会带来很多问题。
--print 如何具体解决主从的不一致的。
对于主主复制的形式,要相当谨慎。
当表含有外键,并且是 on delete 或 on update 约束的情况下,建议暂时不用,可能对子表造成意外的破坏。
部分bug。 --lock-and-rename 对于小于MySQL 5.5 版本的DB是不起作用的(考虑用 pt-online-schema-change 代替?)。
先介绍三个概念: --replicate , find differences , specifying
if DSN has a t part, sync only that table: if 1 DSN: if --sync-to-master: The DSN is a slave. Connect to its master and sync. if more than 1 DSN: The first DSN is the source. Sync each DSN in turn. else if --replicate: if --sync-to-master: The DSN is a slave. Connect to its master, find records of differences, and fix. else: The DSN is the master. Find slaves and connect to each, find records of differences, and fix. else: if only 1 DSN and --sync-to-master: The DSN is a slave. Connect to its master, find tables and filter with --databases etc, and sync each table to the master. else: find tables, filtering with --databases etc, and sync each DSN to the first
默认情况下, 没有—replicate 选项(该选项使用 几种算法自动发现master和slave之间的不同),另外该选项还能利用 pt-table-checksum 已经检查查来的问题。严格来讲,我们不需要使用 –replicate 选项,因为它可以自动发现表之间数据的不一致。 但人们结合两个工具的原因是: pt-table-checksum 定期的对表数据进行校验,当发现不一致时再用 pt-table-sync进行修复。
如何确定数据同步的方向; 使用 –sync-to-master 或者省略。该选项值需要一个 slave DSN 参数.自动发现该slave的master,并开始于master进行同步。实现的方式 是在 master端 做出改变,通过MySQL 的复制机制让slave与master 重新同步。 注意事项: 如果只有一台slave的 那没有问题,多台slave的话,可能也会受到同样的数据变更。
如果不使用 –sync-to-master 的话,第一个DSN参数则必须是 source host(有且只有一个),,没有 –replicate选项的话,我们必须在写一个 DSN参数作为 destination host. 可以有多个 destination host。 Source 和 destination 必须是独立的,不能在同一个复制结构里面。 如果pt-table-sync 检测到目标host是一个同一个复制拓扑里面的slave,工具会报错。因为对数据所做的一些改变是直接写入到 目的 host的,(将修改数据直接写入一个slave ,如果在引用binlog 日志的话,可能会报错。) 或者如果 我们使用 –replicate 选项的话, pt-table-sync 会期望 DSN参数是 master,这样改工具就可以一次性的发现该master所有的slave,并让slave都重新和master进行同步。(--sync-to-master 只更新一个slave)
该工具的 第一个DSN参数 想对于其他的DSN 提供一些默认参数,比如DB 和table,我们可以手动全部写上,或者让工具自动发现。
比如:pt-table-sync --execute h=host1,u=msandbox,p=msandbox h=host2
Host 2 的 DSN参数 继承了 来自 host1 的 u 和 p 的属性。 使用 –explain-hosts 选项可以看到 pt-table-sync 是如何翻译 命令行上的参数的。
使用 –verbose 的情况,会显示出对每个操作表所做处理的详细信息:
# Syncing h=host1,D=test,t=test1
# DELETE REPLACE INSERT UPDATE ALGORITHM START END EXIT DATABASE.TABLE
# 0 0 3 0 Chunk 13:00:00 13:00:17 2 test.test1
Host1 上的 test db 中的test1 表被插入3条记录。并且使用的算法是 chunk, 时间从13:00:00开始持续了17秒。因为发现master和slave之间的不同,所以退出状态时2 。
复制 安全
一般情况下,最安全的方式是只在master端做出变更,利用mysql的复制机制来达到同步的目的。 前提是 在master端执行的是replace语句,而且表中必须有unique index . 否则的话,只是 原始的 insert 语句,可能有的slave 会出现重复信息。
如果表含有unique keys, 我们可以很轻松的 使用 –sync-to-master 或者 –replicate 选项,如果没有的话,我们只能在slave端进行操作。and pt-table-sync will detect that you’re trying to do so. It will complain and die unless you specify --no-check-slave (see --[no]check-slave).
如果在双主模式下的表中没有主键或者unique key,我们必须在目的主机进行操作。 所以呢,我们需要使用 –no-bin-log 选项。
在双主模式下,一般使用—sync –to-master 参数, You will also need to specify --no-check-slave to keep pt-table-sync from complaining that it is changing data on a slave.
有一个多种算法来发现数据差异的框架,该工具自动选择最合适的算法,依据是表的索引,字段类型和算法的偏好设置。
找到一个索引上升指数在固定大小的半字节 - chunk-size行,使用non-backtracking算法,它和chunk算法很类似,但是它不是跟觉表中索引的基数来确定chunk size的大小,而是使用LIMIT定义每个半字节的上限,和之前半字节的上限定义的下限。
1、不适用于 复制架构,只能同步到一台独立的server
至少使用以下选项: --print , --execute, 或者 –dry-run
--where 和 –replicate 是互相排斥的。
--buffer-in-mysql 该选项对于使用 GroupBy 和 Stream算法的时候,即 表没有primary key或 unique key 的时候特别有效。它开启MySQL SQL_BUFFER_RESULT 选项,
Perl 程序使用太多的语言。但是由于MySQL的缓存的查询结果,也不会节省太多内存
--[no]buffer-to-client 默认 :yes 对于MySQLrow记录时 是一条一条对比。
该选项开启了MySQL mysql_use_result 选项,当该工具从MySQL获取到该数据的时候,MySQL将不在持有该数据。如果禁用该选项的话,MySQL会一次性发送所有的rows,所以呢,对于大表来说,你可能会禁用改选项
--[no]check-master 默认是 yes, 当使用 –sync-to-master 检测master是否是真正的master
--chunk-index 根据指定的索引 对表进行chunk
--execute 具体的去修改表数据。 结合-verbose 选项,我们可以看到执行过程。默认是在安静模式下进行的。
如果 使用—replicate 或者 –sync-to-master 参数时,slave端 是不会锁表的。
锁表的时候使用的是 lock tables ,但是如果使用 –transaction 的话,就是在事务开始到提交这一段,开始锁表。
解决有pt-table-checksum 产生所有slave 对master的 differ结果
Pt-table-sync --execute h=master1,D=db,t=tb1 master2
本文转自 位鹏飞 51CTO博客,原文链接:http://blog.51cto.com/weipengfei/1073340,如需转载请自行联系原作者