Infobright的基本特征:
优点:
查询性能高:百万、千万、亿级记录数条件下,同等的SELECT查询语句,速度比MyISAM、InnoDB等普通的MySQL存储引擎快5~60倍
存储数据量大:TB级数据大小,几十亿条记录
高压缩比:在我们的项目中为18:1,极大地节省了数据存储空间
基于列存储:无需建索引,无需分区
适合复杂的分析性SQL查询:SUM, COUNT, AVG, GROUP BY
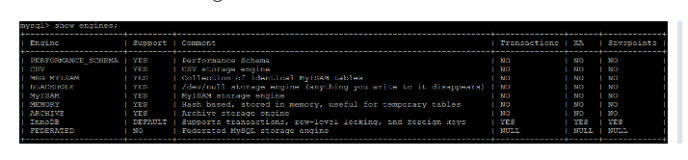
支持事务(但不支持 savepoint)
限制:
不支持数据更新:社区版Infobright只能使用“LOAD DATA INFILE”的方式导入数据,不支持INSERT、UPDATE、DELETE
不支持高并发:只能支持10多个并发查询;
ICE版本不对于infobright引擎不能使用主从结构;
Infobright 和 MySQL
Server层采用MySQL,存储引擎层采用Infobright,由于是列式存储引擎,Infobright 不能作为MySQL的插件存在,MySQL 也不能使用 infobright的 Knowledge Grid特性;仍可使用 MyISAM 和 CSV MEMORY 存储引擎;
整体架构图:

MySQL 与 infobright 各自分工:
MySQL: connect,tools,resources;验证;服务管理,各种集成工具
Infobright: load 、compress data; 列式存储引擎, Knowledge Grid 元数据统计信息;
优化/执行
对于ICE版本,如果想要使用Innodb 这样的引擎的话,最后借助federated 远程连接存储引擎;
架构分析:
Infobright通过三层来组织数据,分别是DP(Data Pack)、DPN(Data Pack Node)、KN(Knowledge Node)。而在这三层之上就是无比强大的知识网络(Knowledge Grid)。
数据块(DP)是存储的最低层,列中每64K个单元组成一个DP。DP比列更小,具有更好的压缩比率;又比单个数据单元更大,具有更好的查询性能。
数据块节点(DPN),DPN和DP之间是一对一的关系。DPN记录着每一个DP里面存储和压缩的一些统计数据,包括最大值、最小值、null的个数、单元总数count、sum等等。
KN里面存储着指向DP之间或者列之间关系的一些元数据集合,比如值发生的范围(MIin_Max)、列数据之间的关联。大部分的KN数据是装载数据的时候产生的,另外一些事是查询的时候产生。
Knowledge Grid构架是Infobright高性能的重要原因。
Knowledge Grid可分为四部分,DPN、Histogram、CMAP、Pack/Pack
Histogram用来提高数字类型(比如date,time,decimal)的查询的性能。是装载数据的时候就产生的;
DPN中有mix、max,Histogram中把Min-Max分成1024段,如果Mix_Max范围小于1024的话,每一段就是就是一个单独的值。
Histogram的作用就是快速判断当前DP是否满足查询条件。
CMAP是针对于文本类型的查询,也是装载数据的时候就产生的。用数值记录某个字符串是否出现;0表示没有出现,1表示出现过。查询中文本的比较归根究底还是按照字节进行比较,所以根据CMAP能够很好地提高文本查询的性能。
Pack-To-Pack是Join操作的时候产生的,它是表示join的两个DP中操作的两个列之间关系的位图,也就是二进制表示的矩阵。
Brighthouse.ini 内存推荐配置:

注意:infobright 可使用bhload 导入数据;
从infobright导出含有null的数据的时候,不会显示,所以在导入到其他MySQL时候,会造成 column不对应;
压缩比率指的是数据库中的原始数据大小/压缩后的数据大小,而不是文本文件的物理数据大小/压缩后的数据大小。
查询优化部分:
对于字符串列的属性 添加Comment Lookup可以减少存储空间,提高压缩率,采用comment lookup可以提高查询效率。Comment Lookup实现机制很像位图索引,实现上利用简短的数值类型替代char字段已取得更好的查询性能和压缩比率;CommentLookup 一般要求数据类别的总数小于10000并且当前列的单元数量/类别数量大于10。Comment Lookup比较适合年龄,性别,省份这一类型的字段;
尽量不适用or,可以采用in或者union取而代之;
尽量使用独立的子查询和join操作代替非独立的子查询;
不在where里面使用MySQL函数和类型转换符;
尽量避免会使用MySQL优化器的查询操作;
避免使用跨越Infobright表和MySQL表的查询操作;
select里面尽量剔除不要的字段。
本文转自 位鹏飞 51CTO博客,原文链接:http://blog.51cto.com/weipengfei/1255762,如需转载请自行联系原作者