图片缓存:
ImageLoader的知识点讲的比较老,暂不总结(题外话:推荐Glide或者Fresco,但是一定要进行二次封装,否则谁知道哪天心血来潮,想着换个框架试试呢)
图片加载利器Fresco:
配置文件配置:
<uses-permissionandroid:name="android.permission.INTERNET"/>
在application中进行初始化:
Fresco.initialize(context);
将程序中显示图片的ImageView替换为SimpleDraweeView,并添加fresco命名空间:
<!-- 其他元素 -->
<LinearLayout
xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:fresco="http://schemas.android.com/apk/res-auto">
加入SimpleDraweeView:
<com.facebook.drawee.view.SimpleDraweeView
android:id="@+id/my_image_view"
android:layout_width="20dp"
android:layout_height="20dp"
fresco:placeholderImage="@drawable/my_drawable"
/>
在activity或者fragment里面加载网络图片:
Uri uri =Uri.parse("https://raw.githubusercontent.com/facebook/fresco/gh-pages/static/fresco-logo.png");
SimpleDraweeView draweeView =(SimpleDraweeView) findViewById(R.id.my_image_view);
draweeView.setImageURI(uri);
Image pipeline工作流:
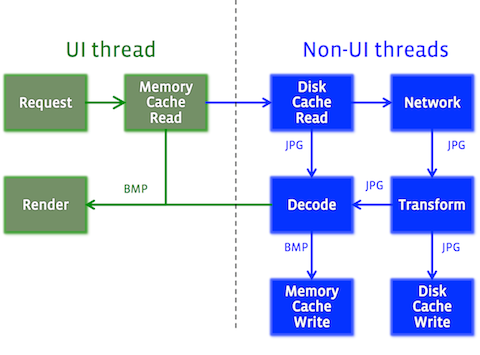
Freso三层缓存概念:
bitmap缓存:5.0,bitmap缓存在heap堆中。
4.0及以下:bitmap位于ashmem中,而不是java的heap中,不会因为图片创建,回收引发过多gc,当App切换到后台,会清空bitmap缓存。
内存缓存:存储图片原始压缩格式,从内存中取出来并解码,切换后台,清理内存缓存。
磁盘缓存:存储在本地,不会丢失。
网上fresco中文文档可以看下:http://fresco-cn.org/docs/index.html#_
网络流量优化:
- 数据进行压缩处理进行传输,使用Gzip
- 传输格式使用json或者protobuffer
- 尽可能将一个页面的多个数据请求进行合并处理
- 使用长连接代替http请求
- 离开页面,取消请求(这方面比如我以前用的volley,现在用的okhttp都有提供方法来取消,一般将取消操作统一封装在基类的onDestory()里面)。
- 建立重试机制。一般设置重试三次的操作,只针对get,post要防止重试。
图片流量优化:
- 客户端可以通过传递宽高,来让服务器端对图片进行裁剪,并获取符合当前显示控件的的图片,相对应的对服务器端的压力比较大。
- 针对2G以及3G用户降低图片的质量,从而减少图片占据的流量。
- 其实如果应用对图片的要求不是很高的话,可以控制应用在2G,3G的网络环境不加载图片,而在wifi的情况下加载,当然最好在应用里面设置个可选项供用户选择。
城市列表数据:
城市列表信息,一般包括以下内容:
cityid 城市id
cityname 城市名称
pinyin 城市拼音
jianpin 城市简拼音
(题外话,一般项目中有两种方式来获取城市列表信息:
1,直接db文件或者json文件,
2,每次从服务器端获取,但是序列化本地,读取的时候从缓存文件里面读取
)
对于2的问题,其实还是有个问题存在的,就是你每次都去序列化这些内容吗,或者说每次都从服务器端获取缓存数据库或者文件里面吗,很明显是不明智的。
书里面针对上面的问题,其实在json结构设计的时候进行比较合适的方式来进行解决:
{
"citys" : {},
"isMatch" : false,
"version" : 1
}
isMatch:表示是否本地version和服务器端城市列表信息的version一致。
version:城市列表数据的版本信息。
citys:城市列表数据。
给城市列表的json数据加上version字段,如果version字段不变化,第二次就不去更新这些内容,当version字段发生变化额时候,再对数据进行递增。
App这边的策略:
- 本地存储发版前最新的城市列表信息,包含版本信息;
- 获取城市列表的时候,将本地城市信息列表里面版本信息带到接口里面,根据返回的时候,isMatch的字段来判断是否和服务器端一致,如果一致,读取客户端缓存数据,不一致解析并缓存最新的城市列表数据。
- 接口调用失败,读本地缓存城市列表数据。
- 开gzip压缩,确保传输数据量最少。
- 无论是解析还是读取本地缓存的城市信息,一定要异步处理,否则很容易卡顿。
城市列表信息增量更新:
分为2种情况:
- 原有的表数据要进行修改。
- 有新增的城市列表数据。
接下来的方案也是针对这两种情况进行处理的:
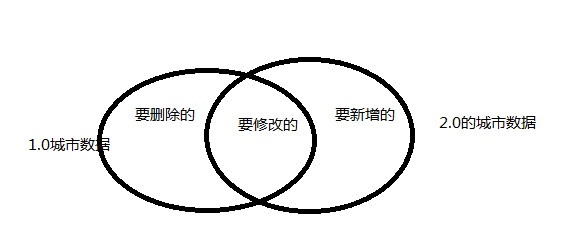
存在对城市信息的操作由三种:
- 增加新城市信息;
- 删除无效的城市信息;
- 更新已有的城市数据;
解决方法:
给城市信息加上type类型:
{
"isMatch":false;
"version":1,
"citys":{
{
"cityid":1,
"cityName":"西安",
"pinyin":"xian",
"jianpin":"xa",
"type":"delete"
},
{
"cityid":2,
"cityName":"北京",
"pinyin":"beijing",
"jianpin":"bj",
"type":"update"
},
{
"cityid":3,
"cityName":"南京",
"pinyin":"nanjing",
"jianpin":"nj",
"type":"add"
}
}
}
delete 删除 删除指定cityid的城市信息
update 更新 更新某cityid的城市信息
add 增加 增加新的城市信息
App与html5的交互:
代码地址:https://github.com/icodeu/AppProgrammingSource/tree/master/3.4%20App%E4%B8%8EHtml5%E4%BA%A4%E4%BA%92
html5和native直接灵活切换:
两套界面 native html5各一套,通过接口里面字段控制是展示native还是html5界面。
策略:
- 后台根据版本配置决定页面是通过native还是htm5页面进行展示和交互。
- 在app启动的时候,获取页面是html5还是native页面。
- 页面跳转实现松耦合,设计个NavigatorManager类,来控制项目里面所有页面跳转操作。
消灭全局变量:
当app切换到后台,之前存放的全局变量会很容易回收,如果切换回前台,可能会因为使用某个全局变量,但这时变量为null而崩溃。
解决办法:
序列化。
使用intent来进行数据传递(缺点,不能携带数据量大的数据)。
将数据序列化到本地,如果内存中的变量回收,就从本地去获取。
上面方案的问题:
- 强制执行序列化操作,容易ANR。
- 序列化生成的文件,会因为内存不足丢失。
- JsonObject ,JsonArray不支持序列化,HashMap<String, Object>不一定支持序列化,ArrayList<HashMap<String, Object>>不一定支持序列化。
2的临时解决方案:
使用完,清空,然后强制序列化到本地,确保本地文件体积减少。
3的解决方案:以字符串序列化到本地;HashMap<String, Object>,ArrayList<HashMap<String, Object>>建议Object转为String,否则就要遍历将Object转换为String。
如果Activity也被销毁了呢?
onSaveInstanceState()
onRestoreInstanceState()
User是唯一的全局变量(指的是用户信息,登录后获取到的,客户端是应该长期缓存的,除非注销登录)。





