热门
让你的文档从静态展示到一键部署可操作验证
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
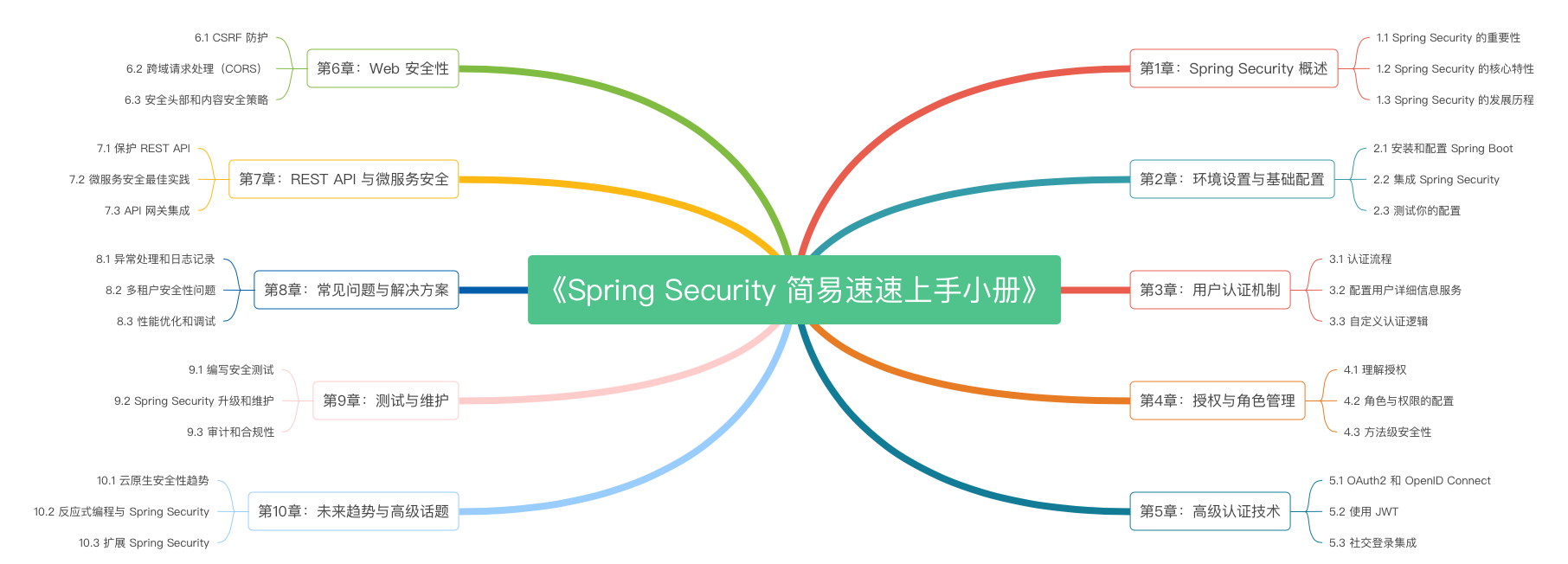
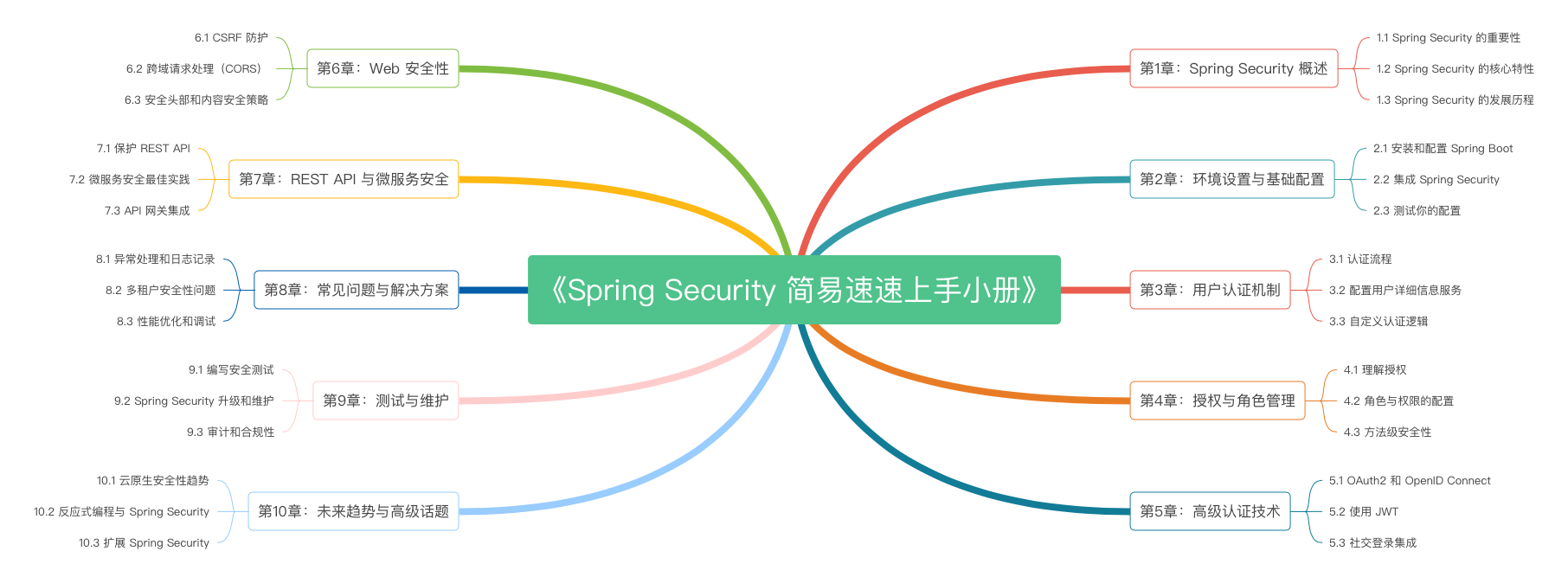
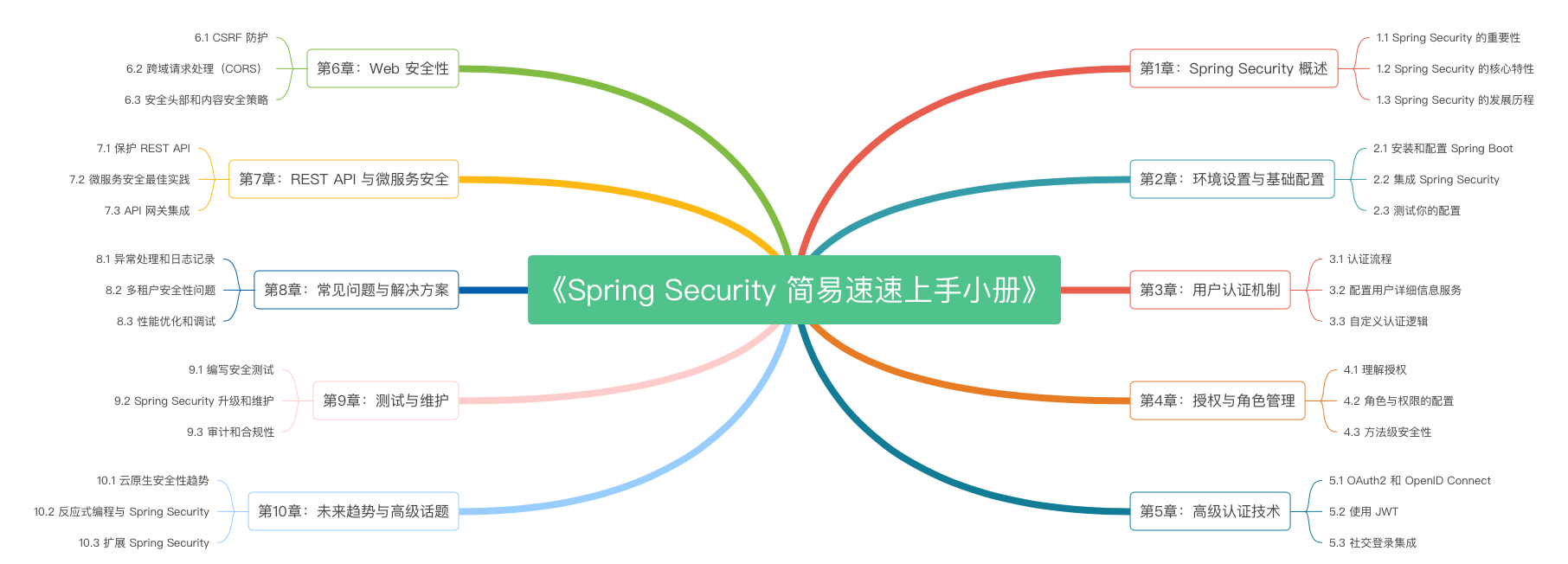
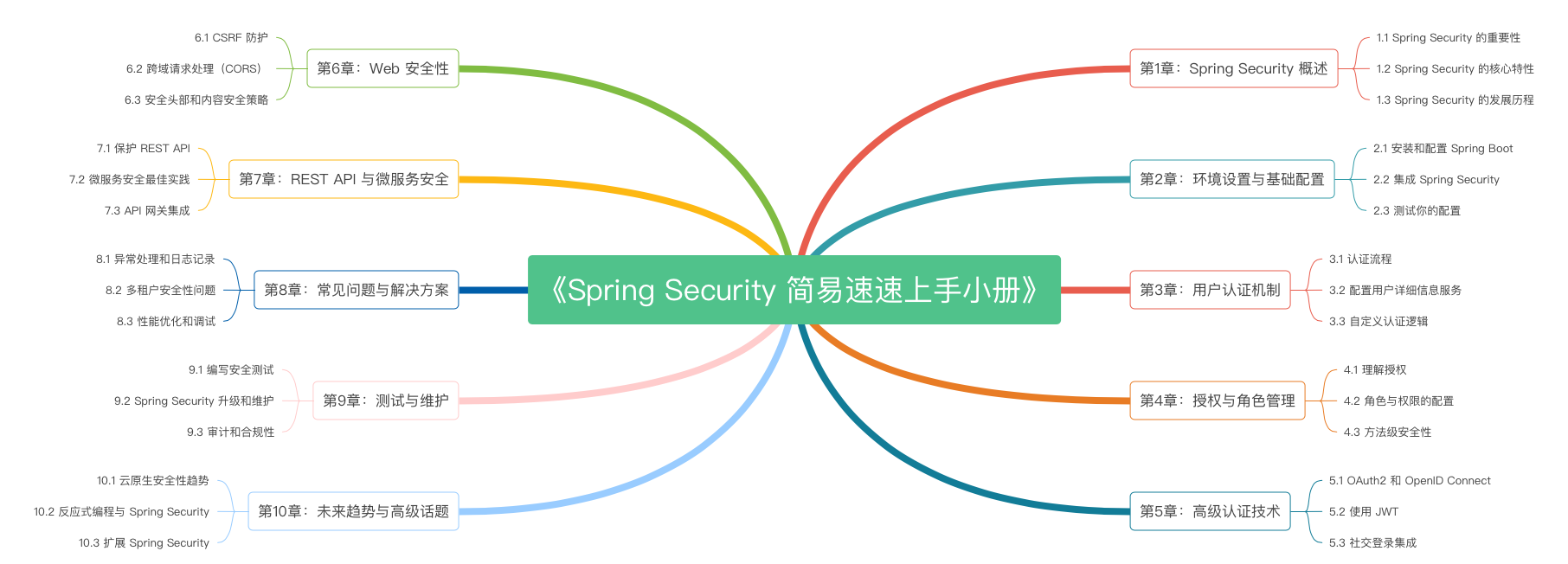
第5章 Spring Security 的高级认证技术(2024 最新版)(下)
第5章 Spring Security 的高级认证技术(2024 最新版)(上)
第4章 Spring Security 的授权与角色管理(2024 最新版)(下)
第3章 Spring Security 的用户认证机制(2024 最新版)(下)
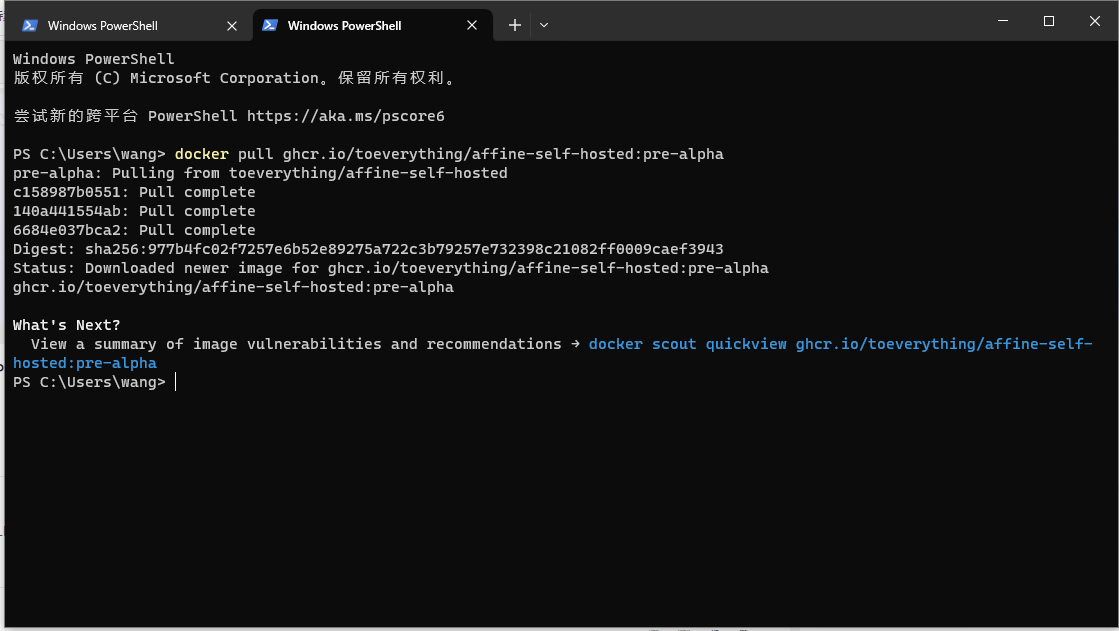
Notion平替工具AFFINE知识库如何本地部署与公网远程访问
第3章 Spring Security 的用户认证机制(2024 最新版)(上)
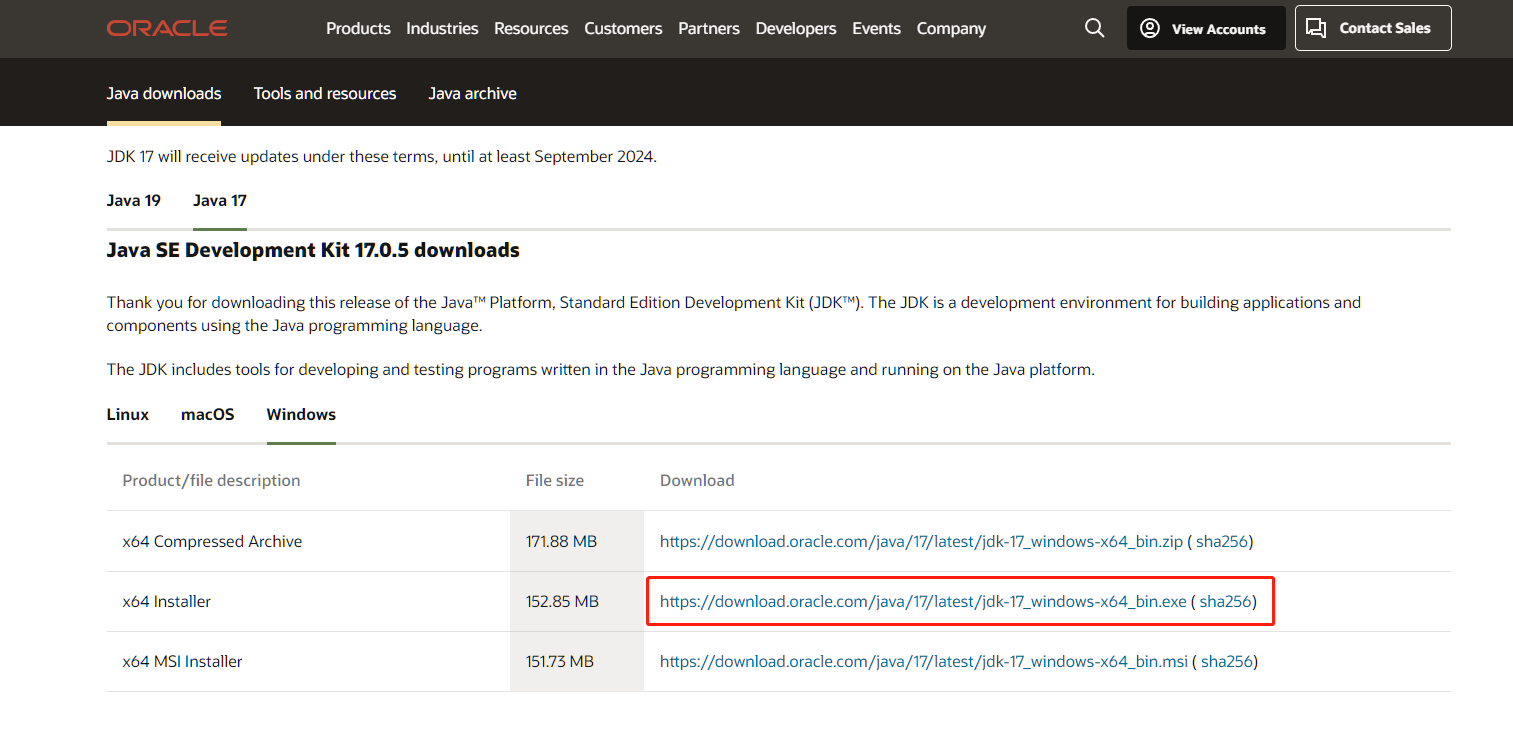
第2章 Spring Security 的环境设置与基础配置(2024 最新版)(下)
第2章 Spring Security 的环境设置与基础配置(2024 最新版)(上)
第1章 Spring Security 概述(2024 最新版)(下)
在Ubuntu系统上部署Inis博客,并使用内网穿透将博客网站发布到公共互联网上
第1章 Spring Security 概述(2024 最新版)(上)
《数据治理简易速速上手小册》第10章 未来数据治理的趋势与挑战(2024 最新版)
《数据治理简易速速上手小册》第9章 数据治理中的人与流程(2024 最新版)
打造个人的Minecraft服务器:Java+cpolar实现我的世界联机游戏
《数据治理简易速速上手小册》第8章 数据生命周期管理(2024 最新版)
《数据治理简易速速上手小册》第7章 元数据管理(2024 最新版)
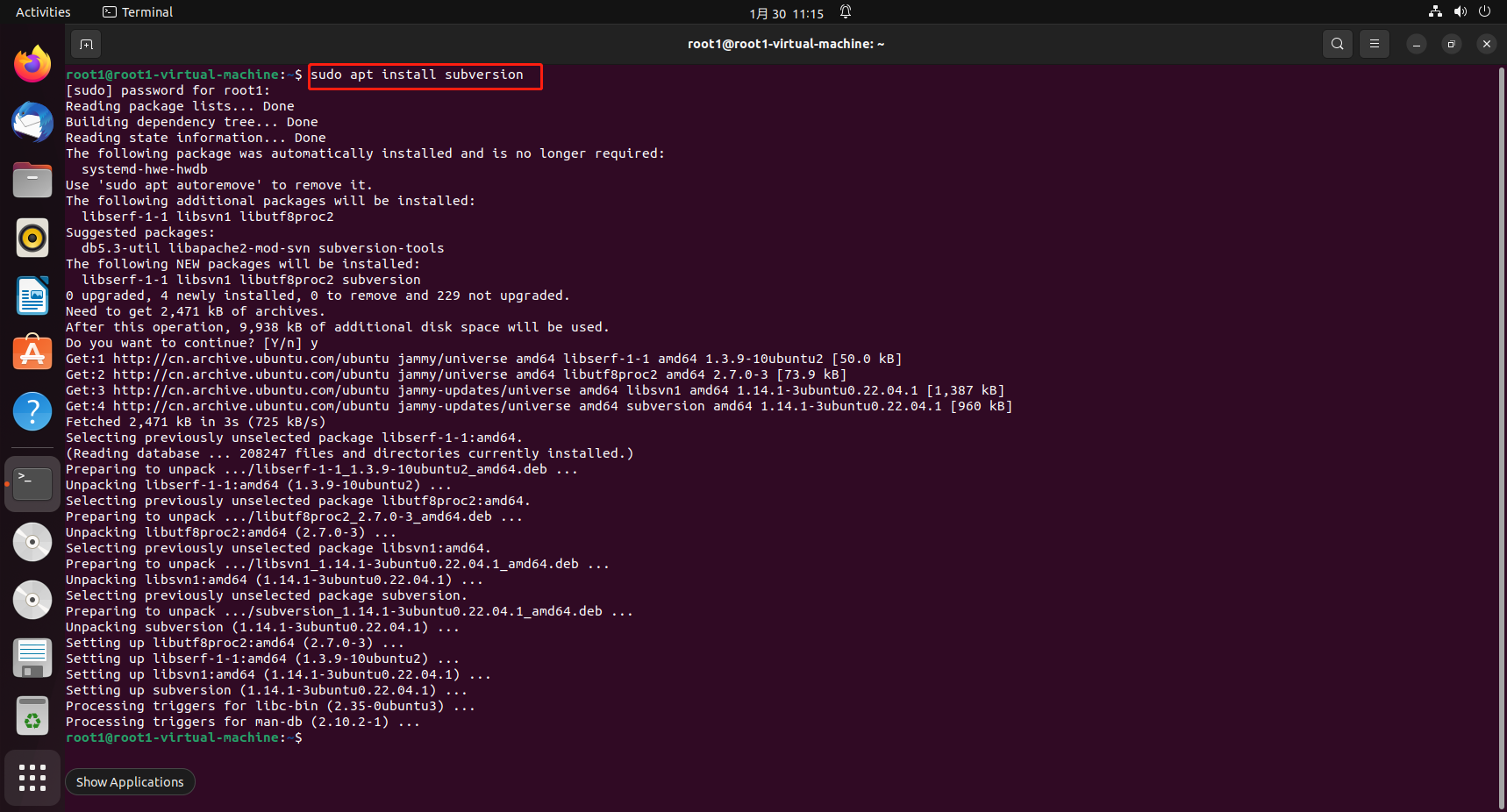
如何使用内网穿透远程访问Linux SVN服务?
《数据治理简易速速上手小册》第6章 数据访问与共享(2024 最新版)
《数据治理简易速速上手小册》第5章 数据整合与存储(2024 最新版)
《数据治理简易速速上手小册》第4章 数据安全与合规性(2024 最新版)
《数据治理简易速速上手小册》第3章 数据质量管理(2024 最新版)
如何公网远程访问本地WebSocket服务端
《数据治理简易速速上手小册》第2章 数据治理框架的建立(2024 最新版)
内存
默认值
《数据治理简易速速上手小册》第1章 数据治理概述(2024 最新版)
Linux权限管理
成员变量
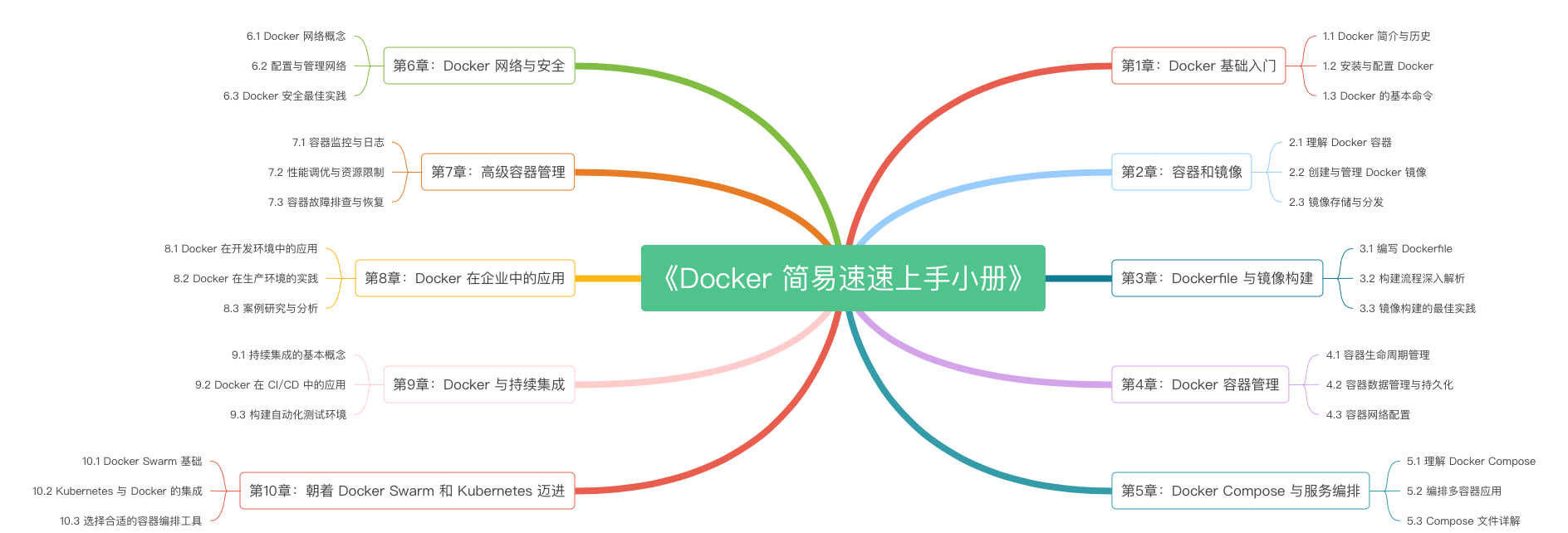
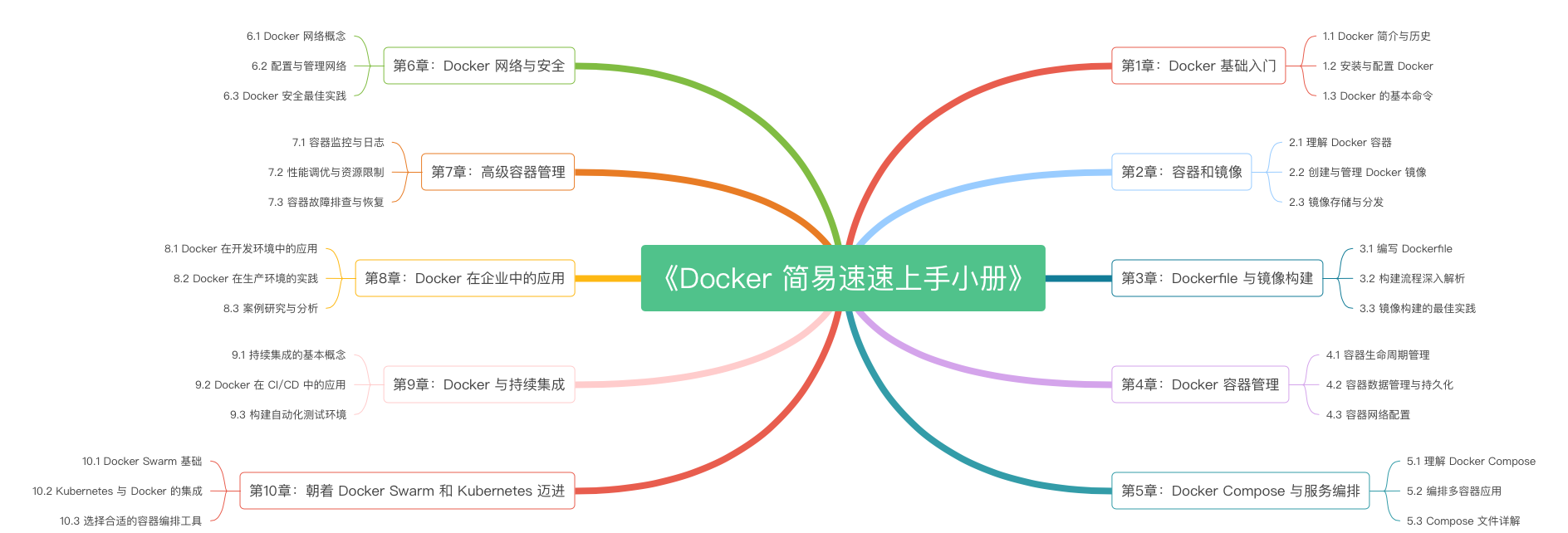
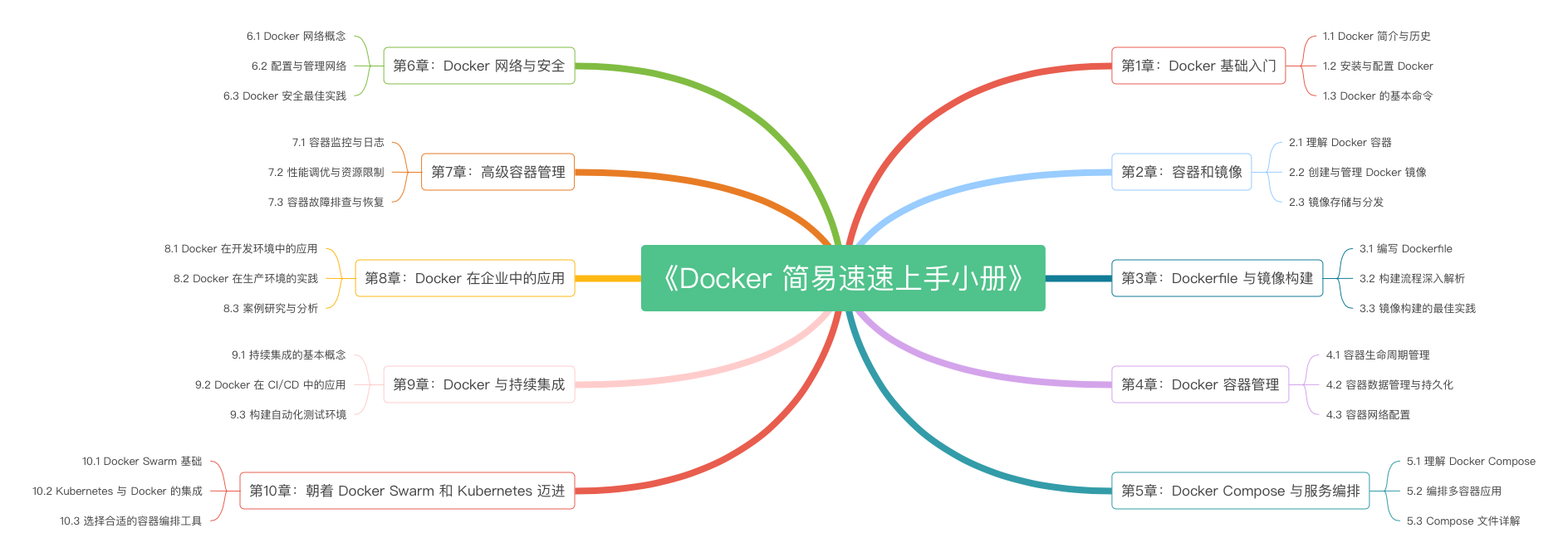
《Docker 简易速速上手小册》第10章 朝着 Docker Swarm 和 Kubernetes 迈进(2024 最新版)
《Docker 简易速速上手小册》第9章 Docker 与持续集成(2024 最新版)
《Docker 简易速速上手小册》第8章 Docker 在企业中的应用(2024 最新版)
《Docker 简易速速上手小册》第7章 高级容器管理(2024 最新版)
如何在Android Termux上安装MySQL并实现公网远程访问?
《Docker 简易速速上手小册》第6章 Docker 网络与安全(2024 最新版)
《Docker 简易速速上手小册》第5章 Docker Compose 与服务编排(2024 最新版)
《Docker 简易速速上手小册》第4章 Docker 容器管理(2024 最新版)
《Docker 简易速速上手小册》第3章 Dockerfile 与镜像构建(2024 最新版)
提高工作效率的有效途径:五分钟快速学会搭建悟空CRM内网穿透
《Docker 简易速速上手小册》第2章 容器和镜像(2024 最新版)
《Docker 简易速速上手小册》第1章 Docker 基础入门(2024 最新版)
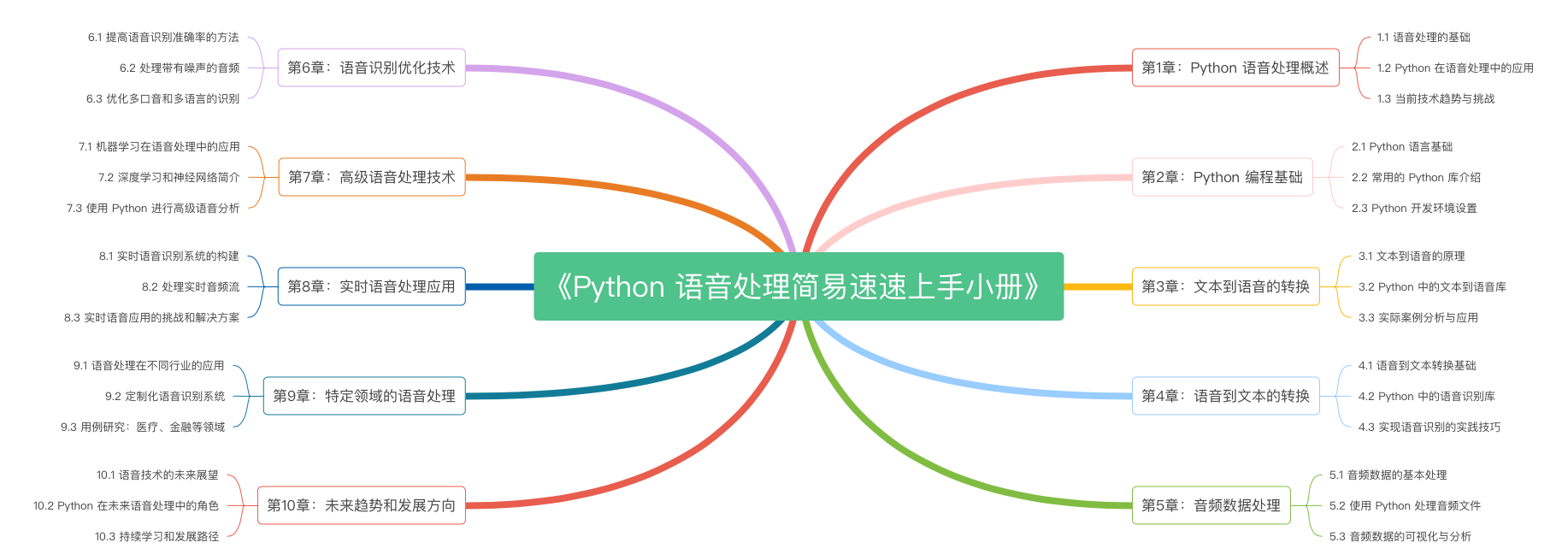
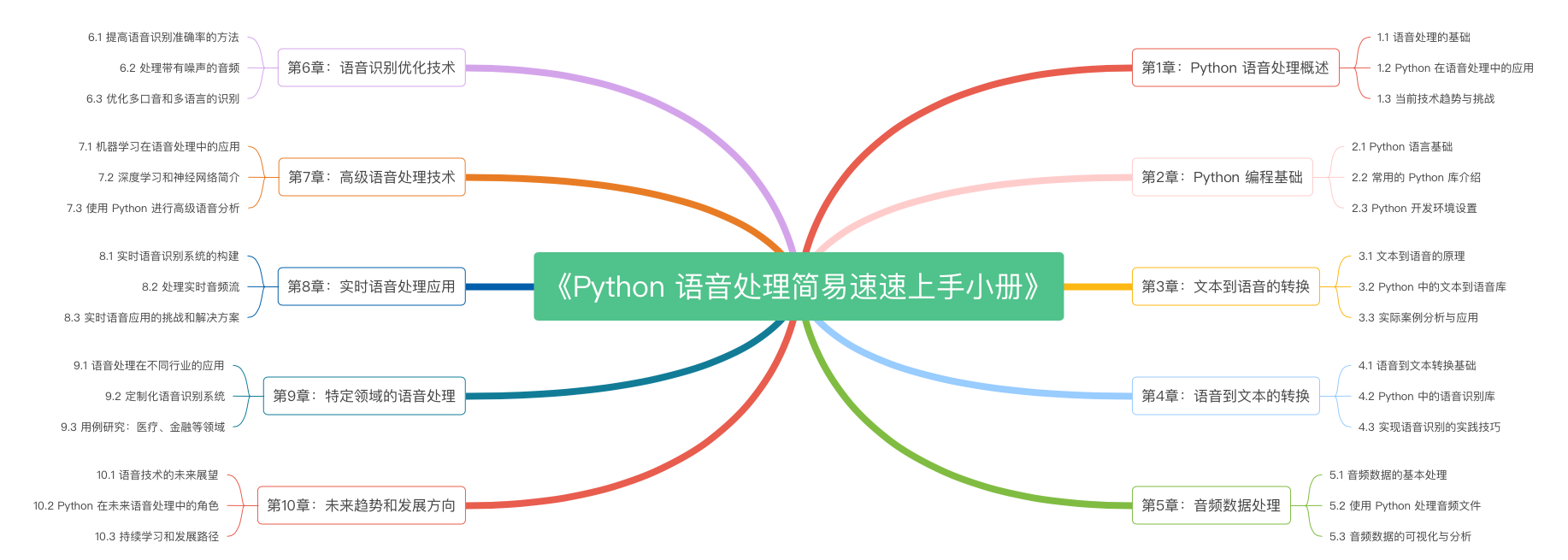
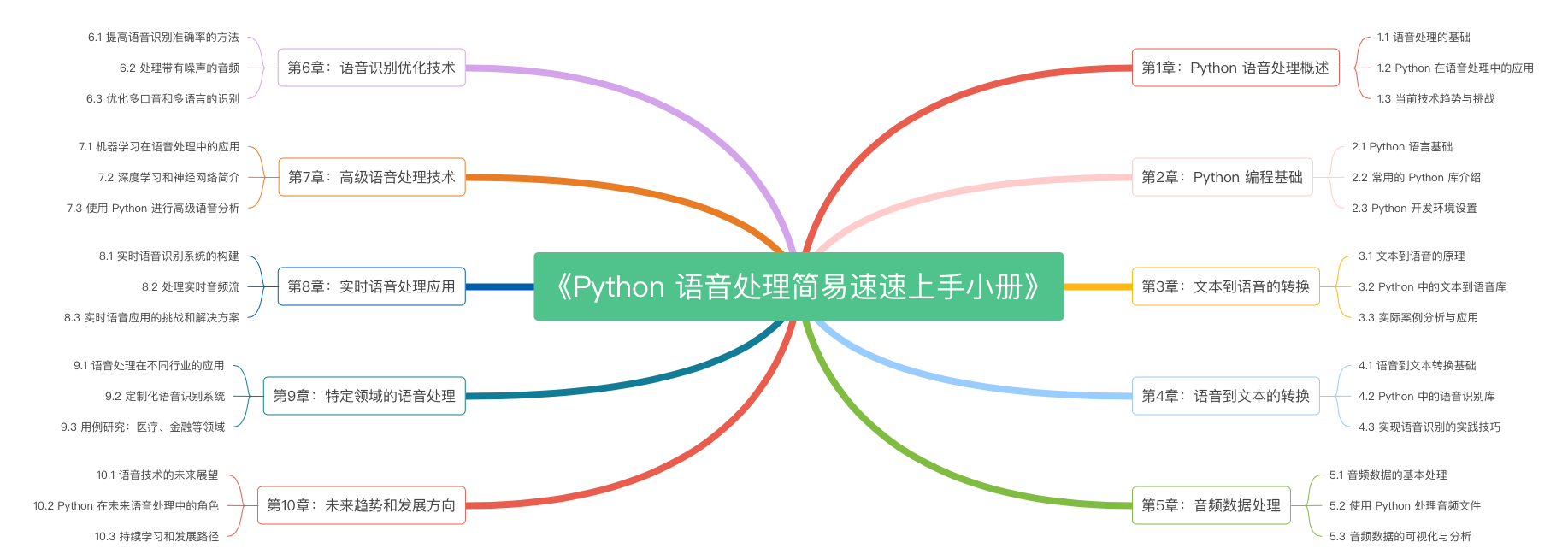
《Python 语音转换简易速速上手小册》第10章 未来趋势和发展方向(2024 最新版)
《Python 语音转换简易速速上手小册》第9章 特定领域的语音处理(2024 最新版)
《Python 语音转换简易速速上手小册》第8章 实时语音处理应用(2024 最新版)
如何部署WampServer并结合cpolar内网穿透工具实现公网访问本地服务?
《Python 语音转换简易速速上手小册》第7章 高级语音处理技术(2024 最新版)
《VitePress 简易速速上手小册》第10章 维护与更新(2024 最新版)
《VitePress 简易速速上手小册》第9章 VitePress 的扩展与插件(2024 最新版)
《VitePress 简易速速上手小册》第8章 安全性与部署(2024 最新版)