Facet属于Solr的高级查询部分,之所以在还没有讲解普通Query之前,就开始更新Facet查询,是因为看到很多小伙伴都在为Facet而困扰,其实根本原因还是对Facet不理解。Facet英文单词本意是方面的意思,但在solr中Facet一般翻译为维度的意思,举个例子,学生可以按班级来分类,可以按性别来分类,可以身高来分类,可以按年龄来分类,可以按考试分数来分类,可以按兴趣爱好分类,可以按出生地址分类等等,上面所说的班级,性别,身高,年龄,考试分数,兴趣爱好,出生地址等等这些都是把学生进行归类分组的一个个维度。可能有些骚年就要发问了,这TM不就是分组吗?他跟分组有什么区别?嗯,如果你能有这个疑问,起码你有在思考,如果你连这个疑问都没有,那你根本没上心。乍看貌似跟Group是一个概念,其实Facet跟Group还是有点区别的,比如,按考试分数统计,我们一般不会说统计60分有几人,61分有几人,62分有几人,63分有几人……一直到100分,实际我们一般会这样统计:60分以下有几人,60-70分有几人,70-80分有几人,80-90分有几人,90-100分有几人。这里说的60分以下,60-70分,70-80,80-90,90-100这表示是分数段,即数字范围,这不是简简单单的按照某个域进行分组的,甚至会有更复杂的维度统计,比如,我要你统计各个分数段男生多少人,女生多少人,这其实就是多个查询条件组合成一个维度,说到这儿,我想大家应该都豁然开朗了,Facet即维度不仅仅是建立在某个域上,它还可以建立在某个查询条件上,该查询条件你可以任意组合,这是Group分组所办不到的,如果你仅仅是对某个域进行Facet统计,那就跟Group类似了。你可以把Facet理解为Group的火力升级版,功能更强大更威猛!!!
学习Facet之前需要解决的另一个问题就是Facet一般用来解决什么问题?我还是用图说话吧!
上图中的品牌,颜色,网络,大家说,价格,热点,屏幕尺寸,系统,机身颜色,购买方式这些都是对手机进行分类的一个个维度,有些维度是手机自身所包含的属性,比如品牌,颜色,网络,系统等,而像价格,屏幕尺寸这就是区间范围了。
对于Facet域建议最好是只创建索引不进行分词不进行存储,因为Facet域的值只是用来显示给用户看的,根据域值进行统计总数,那如果你想要对品牌进行普通查询,你可能需要对品牌域进行分词且你需要在页面上显示品牌的域值,这似乎跟Facet的设计初衷自相矛盾了,其实你可以使用Solr里的copyField来解决,对于普通查询,你可以直接对品牌域使用TextField进行索引分词,而对于Facet统计,你可以使用CopyField且指定域类型为solr.StringField即不进行分词即可。
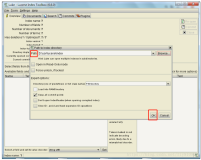
下面我们就拿上回做MySQL数据增量更新示例里使用的测试数据来做我们的Facet测试,启动你的Tomcat,打开Query界面,如图:
勾选了Facet即表示开启了Facet高级查询功能,不过遗憾的是,Solr Web UI的Query表单查询界面里支持的Facet配置参数太少了,就3个,所以通过这个UI界面进行Facet测试会受到限制,所以我建议大家还是通过直接在浏览器里输入请求URL来进行测试吧,只要保证你的Tomcat是处于正常启动状态即可。把Facet勾选后,在facet.field栏里填写你要对哪个域创建一个维度,如图:
查询结果如图:
实际请求URL为:
http://localhost:8080/solr/core2/select?wt=json&indent=true&q=*:*&facet=true&facet.field=brand
你可能要问了,那如果我想对两个域进行facet呢,对不起,通过Solr的Web UI无法实现,只能通过在浏览器地址栏里敲请求URL方式来进行测试,
上面URL表示同时对brand和color这两个域进行Facet统计查询,返回结果如下:
为了照顾一些小白,这里我需要对URL里的一些请求参数做下说明,indent=true即表示需要对返回的数据进行格式化缩进,否则返回的数据将会显示为一整行,不利于你阅读,
wt即write type表示数据输出类型,如图json.xml,html等等,你懂的。还有一些其他的参数,如下:
这部分内容我曾在群里贴过,这里我还是再次分享出来,因为这些参数名称大都是缩写形式,有些小白会不懂这些参数的含义看到后就蒙B了,url里要添加什么参数直接就这样写就行了:&参数名=参数值
Facet.prefix:用来过滤那些Facet维度会被返回,即符合指定前缀字符串的维度才会显示,具体看示例:
返回结果如图:
你会发现brand维度里只有小米这一个维度了,这个很好理解,而color这个维度里返回为空,因为color维度里没有以小字开头的。
facet.sort:表示按照什么来排序,默认值是count即按照每个维度的统计数字降序进行排序的,另一个可选值是index,表示按照维度名称的ASCII值进行升序排序,测试如下:
返回结果如下:
直接facet.field这样设置是对所有维度有效的,如果你只想对单个维度进行排序设置,你可以这样,
返回结果如下:
facet.limit:表示每个维度最多返回几组,默认是全部返回,测试如下:
返回结果如下:
如果你只想对某一个维度进行限制,那你可以这样:
返回结果如下:
注意f.brand.facet.limit写法的含义,前面的f即field的缩写,后面的我想你懂的,不要只知道f.域名称.facet.limit这样写,还要知道这样写的含义,这样有助于你记忆。其实solr里有很多这样的缩写。
facet.offset:表示从那一组开始显示,默认是从0开始,这个参数也支持全局设置和单个维度设置,和facet.limit类似,测试如下:
测试结果如下:
facet.mincount表示每组统计的数字的最小值,默认最小值为0,这个参数也支持对单个维度进行设置,即支持f.域名.facet.mincount,直接facet.mincount设置是全局生效。具体测试就留给你们自己去操作了,我想现在你们应该会了,不需要我再截图了。
facet.missing:表示如果匹配的document当中有域值为null的时候,该document是否应该统计在内,默认facet.missing=false即不统计在内,
facet.method:表示使用哪种策略或者说方法进行facet统计,可选值有enum(枚举迭代),fc即field cache(域缓存),fcs(field cache per segment)即每个段文件的域缓存,默认值是fc,如果你的索引数据需要频繁更新的情况下,才推荐使用fcs,如果你的facet域存在少量唯一的域值即facet统计出来的组数只有几个(10个以下)时,才推荐使用enum进行遍历而不使用field Cache,只有Facet统计出来组数比较多的时候使用Field Cache才有价值。这个查询参数同样支持单个维度设置,你懂的,具体测试就留给你们自己去操作了。
facet.enum.cache.minDf: 表示当你facet.method=enum时,指定term的document频率最小值,小于这个频率的document不进行filterCache,这个值越大相对于FilterCache来说,占用内存越少,但查询时间也增加。一般这个值推荐设置为20-50,,它并不影响最终的facet返回结果,只是影响facet查询性能。这个参数同样支持全局设置和单个维度设置
facet.threads:表示最多开启多少个线程并行去延迟加载域的值,默认为0,即表示不额外
开辟线程,设置为负数即表示线程数不受限制
facet.date:表示对某个域进行日期范围的facet查询,参数值一般为dateField的域名称,如果你使用了facet.date参数,那么facet.date.start. facet.date.end, facet.date.gap需要强制性的同时搭配使用,facet.date.start表示日期范围的起始日期,end即表示结束日期,gap即表示递增的公差,比如+1DAY,+1MONTH,2YEARS
facet.date.hardend: 可选值为true/false,表示含义还是举例说明吧,比如你facet.date.start=2015-01-01,而facet.date.end=2015-09-20 假如你facet.date.gap=+1MONTH即表示按一个月把start与end之间的时间根据gap值分成9份,如果hardend为true,那最后一份的时间范围是2015-09-01至2015-09-20,如果hardend为false,那最后一份的时间范围就是2015-09-01至2015-10-01,即直接无视end参数的限制,严格按照gap的间隔来算。
Facet.date.other: 可选的参数值为before,after,between,none,all
before: 表示需要对start之前的日期做个统计,
after: 表示需要对end之后的日期做个统计
between: 表示需要对start与end之间的日期做个统计
none: 表示不做任何汇总统计
all: 表示before,after,between都需要做统计
示例如下:
&facet=on
&facet.date=date
&facet.date.start=2009-1-1T0:0:0Z
&facet.date.end=2010-1-1T0:0:0Z
&facet.date.gap=%2B1MONTH
&facet.date.other=all
返回结果如下:
<int name="before">180</int>
<int name="after">5</int>
<int name="between">54</int>
Facet Query: 它跟Filter Query有点类似,示例如下:
&facet=on
&facet.query=date:[2009-1-1T0:0:0Z TO 2009-2-1T0:0:0Z]
&facet.query=date:[2009-4-1T0:0:0Z TO 2009-5-1T0:0:0Z]
Key操作符
阿通过key操作符可以为face查询返回的json串中的属性名起一个别名,示例如下:
facet.field={!key=”br”}brand 为brand起一个别名叫br
facet.query=price:[10 TO 20] 返回的json串中属性名默认是price:[10 TO 20],这显然很难看,可以为她起个别名,比如facet.query={!key=”10-20”}price:[10 TO 20] 起个别名叫 10-20
tag&ex操作符
当你使用filter query时,如果你filter Quer作用的域刚好又是facet域时,统计的结果会被限定在filter Query范围之内,看示例:
返回结果如下:
这时如果你想要统计其他组的数字时,你就需要使用tag操作符来标记filter Query,然后在facet.field时,通过tag打的标记使用ex操作符排除该tag标记代表的filter Query对facet.field统计的影响,具体请看示例:
返回结果如下:
Facet Range查询:
即Facet的数字范围查询,日期范围请使用facet.date,不过它的使用方法跟facet.date日期范围查询相似,同理也有facet.range.start,facet.range.end,facet.range.gap,facet.range.hardend,facet.range.other你懂的,就不多说了,区别就是facet range一般用于数字范围检索,此配置项同样支持全局配置以及单个facet域配置。
Facet Pivot查询:
啊pivot干嘛用的,很难用文字解释,我的理解是两个维度的叠加,比如我想统计每种品牌下各种颜色的手机都有多少个?可能你首先想到的是对brand和coloe域进行facet查询啊,测试一下看符不符合我们的预期,
返回结果如下:
但我们可以通过多次查询来实现,比如:
返回结果:
如果要统计白色呢,url改为:http://localhost:8080/solr/core2/select?wt=json&indent=true&q=*:*&facet=true&facet.field=brand&fq=color:白色,如果要统计金色呢,你懂的,那如果我们有几百种颜色呢,那岂不是要查询几百次,有没有一种方法能实现一次查询完成我们期望的统计效果呢,答案就是Pivot Facet Query,测试示例如下:
url : http://localhost:8080/solr/core2/select?wt=json&indent=true&q=*:*&facet=true&facet.pivot=brand,color
返回结果如下:
url: http://localhost:8080/solr/core2/select?wt=json&indent=true&q=*:*&facet=true&facet.pivot={!key=bc}brand,color
给brand,color起个bc别名,我只是为了演示下key取别名也可以作用在facet.pivot参数上,效果图如下:
OK,到此Facet的常见查询我就讲解的差不多了,不过我们的测试都是直接敲URL然后贴到浏览器地址栏里去测试的,略显蛋疼,以后再介绍solr4j的使用吧,那样我们就能通过编程的方式来进行Facet Query测试了,不过理解Facet这些查询配置参数有助于你以后学习solr4j,磨刀不误砍材工嘛!
益达Q-Q: 7-3-6-0-3-1-3-0-5
益达的Q-Q群: 1-0-5-0-9-8-8-0-6
转载:http://iamyida.iteye.com/blog/2217148