

数据集的可视化展示对于分析数据集内在的规律有着很大帮助,因此我想着先学习一点matplotlib和seaborn的画图操作。
import numpy as np
import pandas as pd
import seaborn as sns
from scipy import stats,integrate
from sklearn.datasets import load_boston
import matplotlib.pyplot as plt
%matplotlib inline加载数据集:
Data = load_boston()
X=pd.DataFrame(Data["data"])
y=pd.DataFrame(Data["target"])
Data=pd.DataFrame(np.hstack((X,y)))
data=pd.read_csv("Desktop/creditcard.csv")
iris_data = sns.load_dataset('iris')
Data.columns=['a','b','c','d','e','f','g','h','i','j','k','l','m','n']#从数据集提取出的数据默认列名是自然数字,但是这样下面的lmplot函数会报错,所以手动修改了列名
print(list(Data))#打印列名打印列名:
['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n']中间取了几列做线性拟合:
sns.lmplot(x='a',y='n',data=Data)
sns.lmplot(x='c',y='n',data=Data)
sns.lmplot(x='d',y='n',data=Data)
sns.lmplot(x='sepal_length', y='sepal_width', hue='species', data=iris_data可以看到,seaborn的lmpolt函数可以直接对数据线性回归拟合,还给出了置信区间。
lmplot中,参数x,y都是列名,data就是使用的数据集,hue是分类,按照鸢尾花的species类别进行分类




sns.distplot(data["V1"],bins=50,kde=False,fit=stats.gamma)#V1V2是数据集的列名
plt.show()
sns.distplot(data["V2"],bins=20,kde=True,fit=stats.gamma)#bins为横轴等分数,kde是核分布
plt.show()#如果像lmplot一样不分开打印会导致图表重叠在一起```
可视化结果如下:
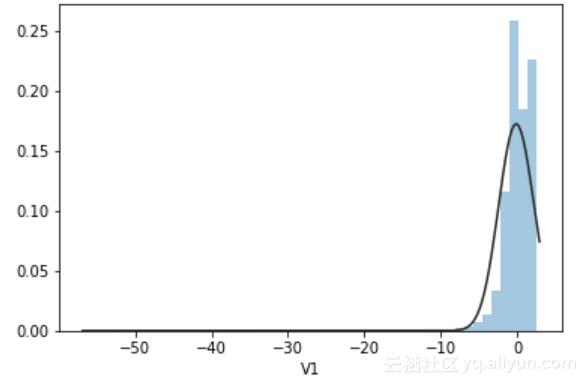
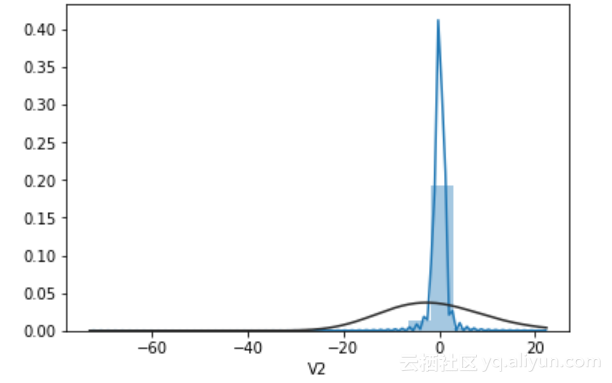
displot函数可以给出一个特征的分布情况,其中的fit=stats.gamma调用scipy中的计算高斯分布的函数,就是图上的黑色密度分布线。
类似的函数还有regplot。sns.JointGrid(data=Data, x='e', y='n').plot(sns.regplot, sns.distplot)
plt.show()
需要对图表设置样式,即加上.plot(sns.regplot, sns.distplot),否则不显示
这里默认选择了 seaborn 带有的回归拟合散点图以及单变量分布图
可视化结果为:
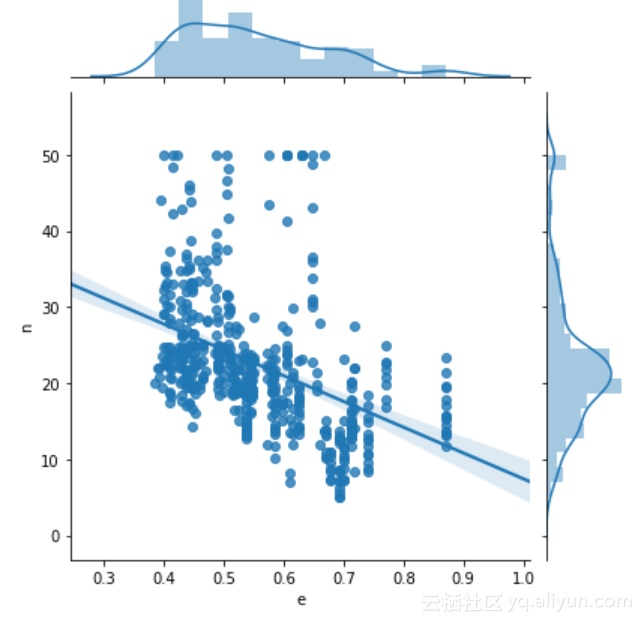
JointGrid显示了回归结果的同时也给出边缘分布
多个特征相互比较,可以用PairGridsns.PairGrid(data=iris_data,hue='species').map(plt.scatter)
同样也需要设置图表样式
结果的一部分:
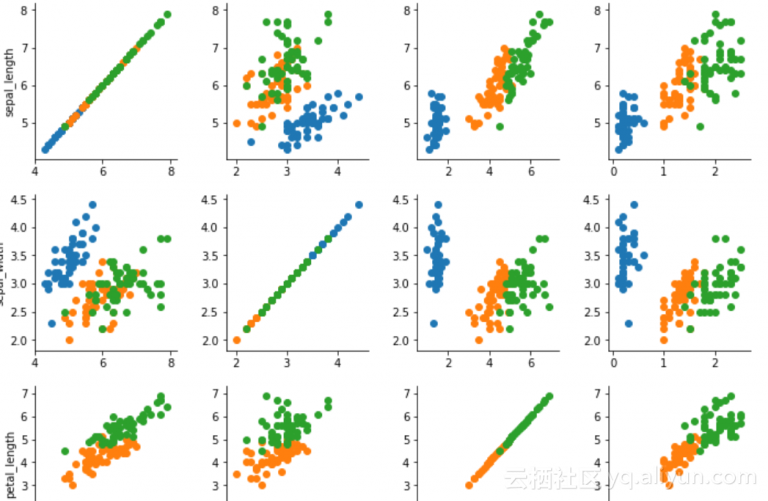
更多的还有像色彩矩阵,小提琴状图,箱形图等,不同的图适用不同的数据集。可视化的最终目的还是直观地了解数据集的嗯不状况,以方便做出最好的处理。



