Google今天推出了一个语音指令数据集,其中包含30个词的65000条语音,wav格式,每条长度为一秒钟。
这30个词都是英文的,基本是yes、no、up、down、stop、go这类。
这个数据集由Google TensorFlow团队和AIY团队共同推出的,AIY就是之前推出树莓派DIY智能音箱的那个团队:

所以说,也别指望用这个数据集训练模型然后做个App什么的,它其实和那个DIY的音箱差不多,主要供初学者/爱好者练手用。
语音识别教程
Google还配合这个数据集,推出了一份TensorFlow教程,教你训练一个简单的语音识别网络,能识别10个词,就像是语音识别领域的MNIST(手写数字识别数据集)。
虽然这份教程和数据集都比真实场景简化了太多,但能帮用户建立起对语音识别技术的基本理解,很适合初学者使用。
教程中要带你识别的词包括:yes、no、up、down、left、right、on、off、stop、go。
训练:
开始训练前,要先装好TensorFlow,然后在source tree运行这行命令:
python tensorflow/examples/speech_commands/train.py上面提到的语音指令数据集会自动开始下载,下载完成后会看到这样的提示信息:
I0730 16:53:44.766740 55030 train.py:176] Training from step: 1
I0730 16:53:47.289078 55030 train.py:217] Step #1: rate 0.001000, accuracy 7.0%, cross entropy 2.611571这表示初始化已经完成,训练开始了。
其中,Step #1表示我们正处在training loop的第1步,后面是三个指标:学习率(learning rate),控制着网络的权重调整速度;精确度(accuracy),表示在当前step下模型的识别准确率是多少;以及交叉熵(cross entropy),是损失函数的结果。
100步之后,会看到一行这样的结果:
I0730 16:54:41.813438 55030 train.py:252] Saving to "/tmp/speech_co
mmands_train/conv.ckpt-100"这表示正在存档当前的权重。
混淆矩阵:
400步后,你会看到一个混淆矩阵:
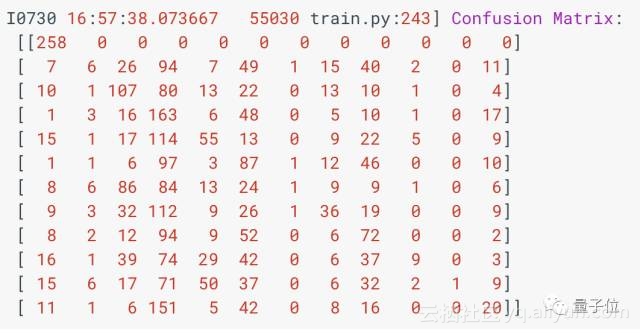
想要理解这个矩阵,要先知道它对应的标签。上面矩阵从左到右每一列分别表示:静音、未知、yes、no、up、down、left、right、on、off、stop、go。
每一行是一组样本,在这个例子中,每一组样本实际上是一个词,第一行是没有声音的,第二行是未知词,第三行是yes,等等。
每一个中括号“[]”中,标注了一组样本被识别为各个标签的数量。比如最后一行,表示有11个被识别为没声音、一个被识别为、6个被识别为yes、151个no……
通过混淆矩阵,很容易看出算法错在哪了
验证:
训练之前,最好把数据集分成三份:训练集、验证集和测试集。在训练过程中,神经网络可能会对输入数据产生记忆,为了确保训练出来的模型可以用在它没见过的数据上,需要留出一个验证集,而测试集是一个附加的安全保障,以防训练出来的模型刚好能搞定训练集和测试集,确没法用在更多数据上。
在这份教程的数据集中,训练集占约80%,验证集和测试集分别占10%。
见过混淆矩阵之后,应该会看到这样一行:
I0730 16:57:38.073777 55030 train.py:245] Step 400: Validation accuracy = 26.3% (N=3093)其中的Validation accuracy表示模型在验证集上的准确率。如果训练中的准确率一直在提高,而validation accuracy不变,就说明可能发生了过拟合。
Tensorboard:
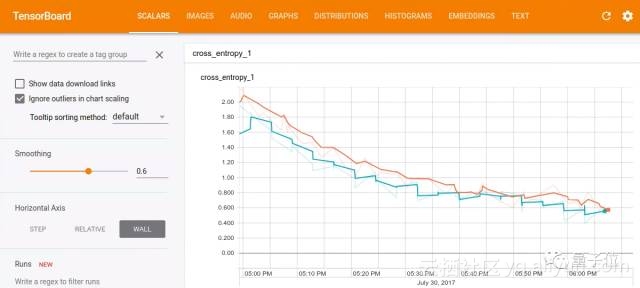
如果想将训练过程可视化,可以用Tensorboard,它的脚本默认会将事件存到/tmp/retrain_logs,运行下面一行命令就能加载出来:
tensorboard --logdir /tmp/retrain_logs然后在浏览器中打开http://localhost:6006,就能看到模型训练情况的图表:
完成训练:
脚本训练完18000步之后,会显示一份最终的混淆矩阵和一个根据测试集得出的准确率得分。如果你按照默认设置进行训练,准确率应该在80%到90%之间。
训练完成后,可以运行下面命令行,导出这个语音识别模型:
python tensorflow/examples/speech_commands/freeze.py \
--start_checkpoint=/tmp/speech_commands_train/conv.ckpt-18000 \
--output_file=/tmp/my_frozen_graph.pb然后可以用label_wav.py脚本,让这个固定的模型识别音频试试:
python tensorflow/examples/speech_commands/label_wav.py \
--graph=/tmp/my_frozen_graph.pb \
--labels=/tmp/speech_commands_train/conv_labels.txt \
--wav=/tmp/speech_dataset/left/a5d485dc_nohash_0.wav如果你识别的刚好是left,就会得到三个标签:
left (score = 0.81477)
right (score = 0.14139)
_unknown_ (score = 0.03808)这份教程所用的架构,在论文Convolutional Neural Networks for Small-footprint Keyword Spotting中有更详细的说明。论文地址:http://www.isca-speech.org/archive/interspeech_2015/papers/i15_1478.pdf
其他
量子位摘录了教程的要点,更详细的版本(英文)见:https://www.tensorflow.org/versions/master/tutorials/audio_recognition
如果你想在其他地方用上文提到的数据集,可以单独下载它。下载地址(1GB):https://download.tensorflow.org/data/speech_commands_v0.01.tar.gz
如果你想先熟悉/预览一下这些语音指令,可以下载这个Android App:
http://ci.tensorflow.org/view/Nightly/job/nightly-android/lastSuccessfulBuild/artifact/out/tensorflow_demo.apk
打开“TF Speech”,可以看到一组10个词的列表,你对着麦克风说哪个词,哪个词就会亮起来。

鉴于这是个练习用的小数据集,有时候也可能识别不是那么准……
另外,Google同时还开源了制作这个数据集的工具:https://github.com/petewarden/open-speech-recording
— 完 —