前言:extent和blockmap是张宇的描述方法,可能与其他资料上的不完全一致,按意思 对应即可
任何一种成熟、可靠的文件系统,其索引机制都是相当核心的技术实现。当然,此处并不包括像CDFS,tar之类(不能支持写操作的)的打包型文件系统。仅仅因为需要支持写操作,文件系统的设计上就需要顾虑太多,对于任何一个文件,可能会随时增加或减少内容,而伴随着容量的改变,磁盘空间的分布、文件占用块的分布需要随之动态改变,这就需要索引机制来表述这种改变。
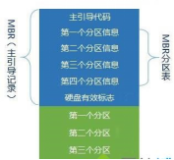
extent和blockmap是两类典型的索引实现方案,事实上,文件系统也似乎仅能按这2种方案(或共同)来实现索引。extent是基于片断的索引方案,blockmap是基于分配块的位图索引。
先说blockmap,这是用在ufs、sco htfs、ext2/3、reiserfs上的索引模式,意思是每个文件的分配块都有一个索引与之对应,是一对一的索引关系。举例来说:EXT3上有个a.dat,文件大小是4M,文件系统的块大小是4K,那这意味着a.dat会占用文件系统的1024个块。对这1024个块,系统会提供1024个4字节(即4096个字节)的索引表,来描述这1024个块到底位置在哪里(就像一个包含1024个对象的指针数组)。这样,文件系统驱动层下了指令,要读或写某个块,可以不用查询直接定位这个特定块。
显而易见,Blockmap的索引机制,需要较大索引空间做保障,随机读写时如跨度太大,缓冲机制无法一次性读入全部索引信息,效率便会下降得多。同时磁盘空间浪费很大(如同EXT3,在节点设计、文件索引等方面全部是定长的MAP机制实现,所以,ext3的磁盘空间浪费严重)。另外,如果是大文件,因块索引极大,就需要对索引块引入几级索引机制(似乎不太好理解),定位某些块时,也需要几层转换。
再谈extent方式,用于ntfs、Vxfs、jfs、ext4等文件系统。其实现方式和blockmap不同的是,索引是按分配的片断记录,只记起始块、连续块数、及文件内部块位置(NTFS叫VCN的东东)。比如上述例子,如果一个EXT4上的4M文件,块大小同样为4K,如果这个文件分配时是连续分配的,只需记录3个数字:(文件内部块号:0,文件系统分配起始块:x,连续块数:1024),不再需要1024个索引空间来描述。当然,如果这个文件有多个碎片组成,则需要多条记录来实现。
extent其优点是索引空间占有率较少,连续读写时会有优势,但缺点是算法复杂度略高。比如一个文件由100个片断(碎片)组成,需要定位到文件内部10M的偏移,则需要二叉查找属于哪个片断,再根据片断的起始地址计算到具体的分配块地址,才可以把数据读出来。如果像NTFS一样,片断本身都由变长方式实现,则内核判断上就更麻烦,文件系统崩溃的可能性也就很大了。
以个人来看,纯粹的blockmap方式,在现在文件都很大的应用环境下,稍显不太适应,慢慢的应用会越来越少。而类似ntfs的变长extent记录方式,则感觉有点得不偿失,这似乎和微软不考虑性能,不考虑健壮性,只考虑功能实现的理念相吻合。