下面资料来源:http://blog.csdn.net/chenhuajie123/article/details/9296359
归并排序的定义
归并排序算法采用的是分治算法,即把两个(或两个以上)有序表合并成一个新的有序表,即把待排序的序列分成若干个子序列,每个子序列都是有序的,然后把有序子序列合并成整体有序序列,这个过程也称为2-路归并.注意:归并排序的一种稳定排序,即相等元素的顺序不会改变.
归并排序的原理
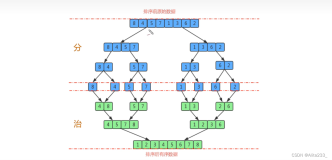
常见的排序主要有两种,一种是先把待排序的序列一次分割,使子序列的长度减小至1,然后在合并,另外一种是把待排序两两分组排序然后在合并,具体过程用图来解释:
(1) 先分割再合并
待排序序列(14,12,15,13,11,16)
(2) 分组合并
待排序序列(25,57,48,37,12,92,86)
(图片显示不了,无语,有空画一个。)
归并排序实现的示例代码:
1 #include<stdio.h> 2 3 //将有二个有序子数组a[begin...mid]和a[mid+1...end]合并。 4 void MergeArray(int a[],int begin,int mid,int end,int temp[]) 5 { 6 int i=begin,j=mid+1; 7 int m=mid,n=end; 8 int k=0; 9 10 while(i<=m && j<=n) 11 { 12 if(a[i]<=a[j]) 13 temp[k++]=a[i++]; 14 else 15 temp[k++]=a[j++]; 16 } 17 while(i<=m) 18 temp[k++]=a[i++]; 19 while(j<=n) 20 temp[k++]=a[j++]; 21 22 //把temp数组中的结果装回a数组 23 for(i=0;i<k;i++) 24 a[begin+i]=temp[i]; 25 } 26 27 void mergesort(int a[],int begin,int end,int temp[]) 28 { 29 if(begin<end) 30 { 31 int mid = (begin+end)/2; 32 mergesort(a,begin,mid,temp); //左边有序 33 mergesort(a,mid+1,end,temp); //右边有序 34 MergeArray(a,begin,mid,end,temp); //将左右两边有序的数组合并 35 } 36 } 37 int main() 38 { 39 int num[10]={2,5,9,3,6,1,0,7,4,8}; 40 int temp[10]; 41 mergesort(num,0,9,temp); 42 for(int i=0;i<10;i++) 43 { 44 printf("%d",num[i]); 45 } 46 printf("\n"); 47 }
归并排序的时间复杂度
归并排序的最好、最坏和平均时间复杂度都是O(nlogn),而空间复杂度是O(n),比较次数介于(nlogn)/2和(nlogn)-n+1,赋值操作的次数是(2nlogn)。因此可以看出,归并排序算法比较占用内存,但却是效率高且稳定的排序算法。
==========================================================
归并排序及其时间复杂度分析
来源:http://xwrwc.blog.163.com/blog/static/46320003201141582544245/
1》归并排序的步骤如下:
Divide: 把长度为n的输入序列分成两个长度为n/2的子序列。
Conquer: 对这两个子序列分别采用归并排序。
Combine: 将两个排序好的子序列合并成一个最终的排序序列。
2》时间复杂度:
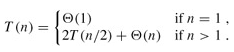
这是一个递推公式(Recurrence),我们需要消去等号右侧的T(n),把T(n)写成n的函数。其实符合一定条件的Recurrence的展开有数学公式可以套,这里我们略去严格的数学证明,只是从直观上看一下这个递推公式的结果。当n=1时可以设T(1)=c1,当n>1时可以设T(n)=2T(n/2)+c2n,我们取c1和c2中较大的一个设为c,把原来的公式改为:
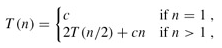
这样计算出的结果应该是T(n)的上界。下面我们把T(n/2)展开成2T(n/4)+cn/2(下图中的(c)),然后再把T(n/4)进一步展开,直到最后全部变成T(1)=c(下图中的(d)):
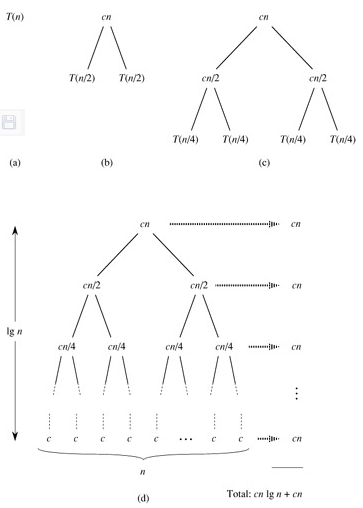
把图(d)中所有的项加起来就是总的执行时间。这是一个树状结构,每一层的和都是cn,共有lgn+1层,因此总的执行时间是cnlgn+cn,相比nlgn来说,cn项可以忽略,因此T(n)的上界是Θ(nlgn)。
如果先前取c1和c2中较小的一个设为c,计算出的结果应该是T(n)的下界,然而推导过程一样,结果也是Θ(nlgn)。既然T(n)的上下界都是Θ(nlgn),显然T(n)就是Θ(nlgn)。
========================================================
归并排序
来源:http://learn.akae.cn/media/ch11s04.html
插入排序算法采取增量式(Incremental)的策略解决问题,每次添一个元素到已排序的子序列中,逐渐将整个数组排序完毕,它的时间复杂度是O(n2)。下面介绍另一种典型的排序算法--归并排序,它采取分而治之(Divide-and-Conquer)的策略,时间复杂度是Θ(nlgn)。归并排序的步骤如下:
-
Divide: 把长度为n的输入序列分成两个长度为n/2的子序列。
-
Conquer: 对这两个子序列分别采用归并排序。
-
Combine: 将两个排序好的子序列合并成一个最终的排序序列。
在描述归并排序的步骤时又调用了归并排序本身,可见这是一个递归的过程。
例 11.2. 归并排序


1 #include <stdio.h> 2 3 #define LEN 8 4 int a[LEN] = { 5, 2, 4, 7, 1, 3, 2, 6 }; 5 6 void merge(int start, int mid, int end) 7 { 8 int n1 = mid - start + 1; 9 int n2 = end - mid; 10 int left[n1], right[n2]; 11 int i, j, k; 12 13 for (i = 0; i < n1; i++) /* left holds a[start..mid] */ 14 left[i] = a[start+i]; 15 for (j = 0; j < n2; j++) /* right holds a[mid+1..end] */ 16 right[j] = a[mid+1+j]; 17 18 i = j = 0; 19 k = start; 20 while (i < n1 && j < n2) 21 if (left[i] < right[j]) 22 a[k++] = left[i++]; 23 else 24 a[k++] = right[j++]; 25 26 while (i < n1) /* left[] is not exhausted */ 27 a[k++] = left[i++]; 28 while (j < n2) /* right[] is not exhausted */ 29 a[k++] = right[j++]; 30 } 31 32 void sort(int start, int end) 33 { 34 int mid; 35 if (start < end) { 36 mid = (start + end) / 2; 37 printf("sort (%d-%d, %d-%d) %d %d %d %d %d %d %d %d\n", 38 start, mid, mid+1, end, 39 a[0], a[1], a[2], a[3], a[4], a[5], a[6], a[7]); 40 sort(start, mid); 41 sort(mid+1, end); 42 merge(start, mid, end); 43 printf("merge (%d-%d, %d-%d) to %d %d %d %d %d %d %d %d\n", 44 start, mid, mid+1, end, 45 a[0], a[1], a[2], a[3], a[4], a[5], a[6], a[7]); 46 } 47 } 48 49 int main(void) 50 { 51 sort(0, LEN-1); 52 return 0; 53 }
执行结果是: sort (0-3, 4-7) 5 2 4 7 1 3 2 6 sort (0-1, 2-3) 5 2 4 7 1 3 2 6 sort (0-0, 1-1) 5 2 4 7 1 3 2 6 merge (0-0, 1-1) to 2 5 4 7 1 3 2 6 sort (2-2, 3-3) 2 5 4 7 1 3 2 6 merge (2-2, 3-3) to 2 5 4 7 1 3 2 6 merge 0-1, 2-3) to 2 4 5 7 1 3 2 6 sort (4-5, 6-7) 2 4 5 7 1 3 2 6 sort (4-4, 5-5) 2 4 5 7 1 3 2 6 merge (4-4, 5-5) to 2 4 5 7 1 3 2 6 sort (6-6, 7-7) 2 4 5 7 1 3 2 6 merge (6-6, 7-7) to 2 4 5 7 1 3 2 6 merge (4-5, 6-7) to 2 4 5 7 1 2 3 6 merge (0-3, 4-7) to 1 2 2 3 4 5 6 7
sort函数把a[start..end]平均分成两个子序列,分别是a[start..mid]和a[mid+1..end],对这两个子序列分别递归调用sort函数进行排序,然后调用merge函数将排好序的两个子序列合并起来,由于两个子序列都已经排好序了,合并的过程很简单,每次循环取两个子序列中最小的元素进行比较,将较小的元素取出放到最终的排序序列中,如果其中一个子序列的元素已取完,就把另一个子序列剩下的元素都放到最终的排序序列中。为了便于理解程序,我在sort函数开头和结尾插了打印语句,可以看出调用过程是这样的:
图 11.4. 归并排序调用过程
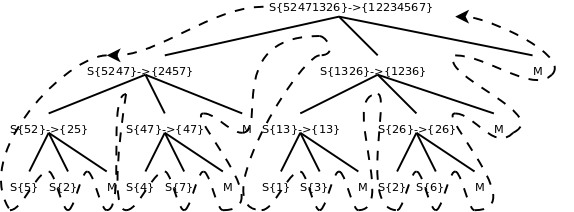
图中S表示sort函数,M表示merge函数,整个控制流程沿虚线所示的方向调用和返回。由于sort函数递归调用了自己两次,所以各函数之间的调用关系呈树状结构。画这个图只是为了清楚地展现归并排序的过程,读者在理解递归函数时一定不要全部展开来看,而是要抓住Base Case和递推关系来理解。我们分析一下归并排序的时间复杂度,以下分析出自[算法导论]。
首先分析merge函数的时间复杂度。在merge函数中演示了C99的新特性--可变长数组,当然也可以避免使用这一特性,比如把left和right都按最大长度LEN分配。不管用哪种办法,定义数组并分配存储空间的执行时间都可以看作常数,与数组的长度无关,常数用Θ-notation记作Θ(1)。设子序列a[start..mid]的长度为n1,子序列[mid+1..end]的长度为n2,a[start..end]的总长度为n=n1+n2,则前两个for循环的执行时间是Θ(n1+n2),也就是Θ(n),后面三个for循环合在一起看,每走一次循环就会在最终的排序序列中确定一个元素,最终的排序序列共有n个元素,所以执行时间也是Θ(n)。两个Θ(n)再加上若干常数项,merge函数总的执行时间仍是Θ(n),其中n=end-start+1。
然后分析sort函数的时间复杂度,当输入长度n=1,也就是start==end时,if条件不成立,执行时间为常数Θ(1),当输入长度n>1时:
总的执行时间 = 2 × 输入长度为n/2的sort函数的执行时间 + merge函数的执行时间Θ(n)
设输入长度为n的sort函数的执行时间为T(n),综上所述:
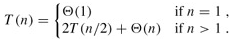
这是一个递推公式(Recurrence),我们需要消去等号右侧的T(n),把T(n)写成n的函数。其实符合一定条件的Recurrence的展开有数学公式可以套,这里我们略去严格的数学证明,只是从直观上看一下这个递推公式的结果。当n=1时可以设T(1)=c1,当n>1时可以设T(n)=2T(n/2)+c2n,我们取c1和c2中较大的一个设为c,把原来的公式改为:

这样计算出的结果应该是T(n)的上界。下面我们把T(n/2)展开成2T(n/4)+cn/2(下图中的(c)),然后再把T(n/4)进一步展开,直到最后全部变成T(1)=c(下图中的(d)):
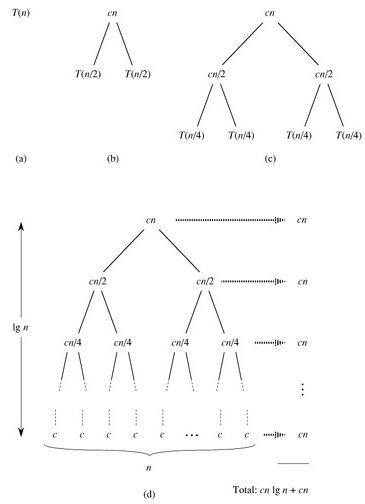
把图(d)中所有的项加起来就是总的执行时间。这是一个树状结构,每一层的和都是cn,共有lgn+1层,因此总的执行时间是cnlgn+cn,相比nlgn来说,cn项可以忽略,因此T(n)的上界是Θ(nlgn)。
如果先前取c1和c2中较小的一个设为c,计算出的结果应该是T(n)的下界,然而推导过程一样,结果也是Θ(nlgn)。既然T(n)的上下界都是Θ(nlgn),显然T(n)就是Θ(nlgn)。
和插入排序的平均情况相比归并排序更快一些,虽然merge函数的步骤较多,引入了较大的常数、系数和低次项,但是对于较大的输入长度n,这些都不是主要因素,归并排序的时间复杂度是Θ(nlgn),而插入排序的平均情况是Θ(n2),这就决定了归并排序是更快的算法。但是不是任何情况下归并排序都优于插入排序呢?哪些情况适用插入排序而不适用归并排序?留给读者思考。
习题
快速排序是另外一种采用分而治之策略的排序算法,在平均情况下的时间复杂度也是Θ(nlgn),但比归并排序有更小的时间常数。它的基本思想是这样的:
1 int partition(int start, int end) 2 { 3 从a[start..end]中选取一个pivot元素(比如选a[start]为pivot); 4 在一个循环中移动a[start..end]的数据,将a[start..end]分成两部分, 5 使a[start..mid-1]比pivot元素小,a[mid+1..end]比pivot元素大,而a[mid]就是pivot元素; 6 return mid; 7 } 8 9 void quicksort(int start, int end) 10 { 11 int mid; 12 if (end > start) { 13 mid = partition(start, end); 14 quicksort(start, mid-1); 15 quicksort(mid+1, end); 16 } 17 }
请补完partition函数,这个函数有多种写法,请选择时间常数尽可能小的实现方法。想想快速排序在最好和最坏情况下的时间复杂度是多少?快速排序在平均情况下的时间复杂度分析起来比较复杂,有兴趣的读者可以参考[
下面来自百度百科:http://baike.baidu.com/link?url=ctLPkJAC2f8htsbT_S_HWB_2_5wRxEQ3QFXpiUWVnl-SC-8kLqZQQRVhL73AVsE0#3_2
快速排序算法
快速排序(Quicksort)是对冒泡排序的一种改进。由C. A. R. Hoare在1962年提出。它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
过程就不复制了。看代码吧
#include <iostream> using namespace std; //从小到大 int partion(int a[],int p,int r){ int x = a[r]; //通常,拿最后一个值,作为预期的中间值 int middle = p; //记录“较小的一段数据”的最大下标。通常这个值在p和r的中间,故起名middle for (int j = p ; j < r ; j++){ if (a[j] < x){ int temp = a[middle]; a[middle] = a[j]; a[j] = temp; middle++; } } int temp = a[r]; a[r] = a[middle]; a[middle] = temp; return middle; } void QuickSort(int a[],int p,int r){ if (p<r){ int q=partion(a,p,r); QuickSort(a,p,q-1); QuickSort(a,q+1,r); } } int main(){ int array[]={0,-2,11,-4,13,-5,14,-43}; QuickSort(array,0,7); for(int i = 0 ; i <= 7 ; i++) cout<<array[i]<<" "; cout<<endl; return 0; }
下面是Java快排的代码:
1 public static void quickSort(int a[], int start, int end) 2 { int i,j; 3 i = start; 4 j = end; 5 if((a==null)||(a.length==0)) 6 return; 7 while(i<j){ 8 while(i<j&&a[i]<=a[j]){ //以数组start下标的数据为key,右侧扫描 9 j--; 10 } 11 if(i<j){ //右侧扫描,找出第一个比key小的,交换位置 12 int temp = a[i]; 13 a[i] = a[j]; 14 a[j] = temp; 15 } 16 while(i<j&&a[i]<a[j]){ //左侧扫描(此时a[j]中存储着key值) 17 i++; 18 } 19 if(i<j){ //找出第一个比key大的,交换位置 20 int temp = a[i]; 21 a[i] = a[j]; 22 a[j] = temp; 23 } 24 } 25 if(i-start>1){ 26 //递归调用,把key前面的完成排序 27 quickSort(a,start,i-1); 28 } 29 if(end-i>1){ 30 quickSort(a,i+1,end); //递归调用,把key后面的完成排序 31 } 32 } 33 34 //////////////////////////// 方式二 //////////////////////////////// 35 更有效率点的代码: 36 public <T extends Comparable<? super T>> T[] quickSort(T [] targetArr, 37 int start, int end) { 38 int i = start + 1, j = end; 39 T key = targetArr[start]; 40 SortUtil<T> sUtil = new SortUtil<T>(); 41 42 if (start >= end) { 43 return targetArr; 44 } 45 46 /* 从i++和j--两个方向搜索不满足条件的值并交换 * 47 * 条件为:i++方向小于key,j--方向大于key */ 48 while (true) { 49 while (targetArr[j].compareTo(key) > 0) { 50 j --; 51 } 52 while (targetArr[i].compareTo(key) < 0 && i < j) { 53 i ++; 54 } 55 if(i >= j) { 56 break; 57 } 58 sUtil.swap(targetArr, i, j); 59 if(targetArr[i] == key) { 60 j--; 61 } else { 62 i++; 63 } 64 } 65 66 /* 关键数据放到‘中间’ */ 67 sUtil.swap(targetArr, start, j); 68 69 if(start < i - 1) { 70 this.quickSort(targetArr, start, i - 1); 71 } 72 if(j + 1 < end) { 73 this.quickSort(targetArr, j + 1 , end); 74 } 75 76 return targetArr; 77 } 78 79 ////////////////方式三:减少交换次数,提高效率///////////////////// 80 private <T extends Comparable<? super T>> void quickSort(T[] targetArr, 81 int start, int end) { 82 int i = start, j = end; 83 T key = targetArr[start]; 84 85 while(i < j) { 86 //按 j -- 方向遍历目标数组,直到比 key 小的值为止 87 while(j > i && targetArr[j].compareTo(key) >= 0) { 88 j --; 89 } 90 if(i < j) { 91 // targetArr[i] 已经保存在key中,可将后面的数填入 92 targetArr[i] = targetArr[j]; 93 } 94 //按 i ++ 方向遍历目标数组,直到比 key 大的值为止 95 while(i < j && targetArr[i].compareTo(key) < 0) { 96 i ++; 97 } 98 if(i < j) { 99 // targetArr[j] 已保存在targetArr[i]中,可将前面的值填入 100 targetArr[j] = targetArr[i]; 101 } 102 } 103 // 此时 i == j 104 targetArr[i] = key; 105 106 if(i - start > 1) { 107 // 递归调用,把key前面的完成排序 108 this.quickSort(targetArr, start, i - 1); 109 } 110 if(end - j > 1) { 111 // 递归调用,把key后面的完成排序 112 this.quickSort(targetArr, j + 1, end); 113 } 114 }
其他关于快排的讲解:
http://www.cnblogs.com/morewindows/archive/2011/08/13/2137415.html