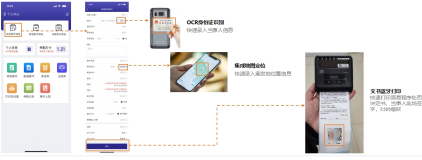
一. 引言
内容化已经成为淘宝近几年发展的重点,我们可以在手机淘宝APP(以下简称手淘)上看到很多不同的内容形式和内容型导购产品,例如,“有好货”中的以单个商品为主体的富文本内容,“必买清单”中的清单,即围绕一个主题来组织文本和商品的长图文型内容,等等。不同于商品的形式,内容可以从不同的维度组织商品,从更丰富的角度去描述商品、定义商品,丰富了手淘的产品形式,提供给了用户更多有价值的购物信息。
随着手淘内容化战略的持续推进,我们也在内容自动化生成上持续探索,并构建了“智能写手”这个产品,旨在利用淘宝的海量数据,结合人工经验和知识输入,逐步实现内容的自动化、规模化生产,和人工编写的更高质量的内容一起,带给用户更丰富、更有价值的信息。经过一段时间的沉淀,目前智能写手在短文案生成、标题生成、商品推荐理由生成、图文型内容(清单)生成上都取得了一定的进展,期间针对若干文本生成的问题也进行了不同程度的优化。
在刚过去的2017年双十一中,智能写手主要做了两件事情,一是支持了大规模实时个性化生成双十一会场入口的短文案(下面称作“智能利益点”项目),保守估计生成了上亿的文案,提升了引导效率;二是进行了图文型清单的生产和投放试水,收集到了用户的直接数据反馈,验证了方案的有效性。
1.1 智能利益点
在每年的双11大促中,手淘首页、主会场等大促活动的主要流量通道上都会有很多的会场入口(参见图1-图4),会场入口一般由三部分构成,分别是会场名称、利益点文案和商品图片素材。其中,利益点往往表达了一个商品或者一个大促会场最核心的亮点,是商家、运营提升点击效果的一个抓手。传统生产利益点文案的方式,有以下特点:
1.受限于数量和人力成本,一个商品或者会场的利益点一般不会超过三个,大多数情况只有一个利益点,这有时会导致利益点文案和商品不匹配的case发生,影响用户体验。
2.用户对一个商品不同的卖点或者说不同的文案表述的关注度是不同的,例如有人关注性价比,有人关注品质等等,人工编辑的较少的利益点文案没办法提供多样的信息,不利于引导效率的提升。
因此,这次双十一,智能写手和首页推荐算法团队、大促平台算法团队一起合作了智能利益点项目,分别在手淘首页人群会场入口、猫客首页人群会场入口、猫客首页标签会场入口、双十一主会场行业会场入口、双十一主会场标签会场入口等多个场景上线了智能利益点。几个场景样式详见以下图片,其中用红色虚线框起来的使用了智能利益点的会场入口的实际效果:
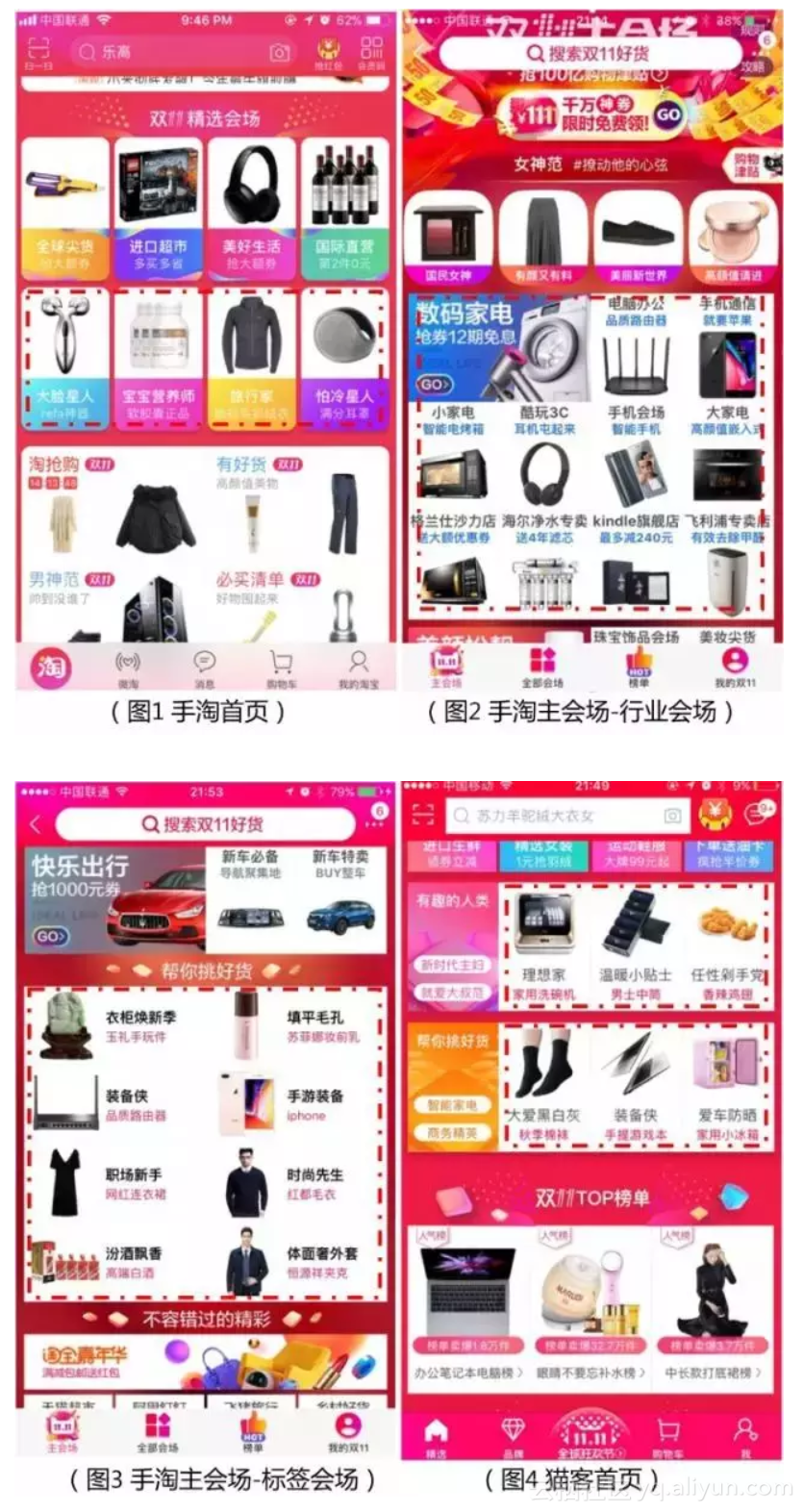
我们在双十一期间做了分桶测试,相比使用人工编辑利益点文案的分桶,智能利益点的分桶在多个场景都取得了用户点击率两位数左右的提升,这个提升是在各个场景自身优化效果的基础上的额外提升,还是比较可观的,这也说明了文案个性化生成确实给用户带来了更多的有价值的信息。
1.2 图文型清单生成
在手淘中,图文型清单是一种重要的商品组织形式,可以理解为有主题的商品集合富文本内容,主要由人工编辑而成,生产清单费时费力,尤其在大促期间,要短时间内生产大量的清单更是一个很大的挑战。这次双十一,智能写手也参与到这个工作中,结合在文本内容生成上的沉淀,生产了少量单品盘点类型的清单,具体样式如下:
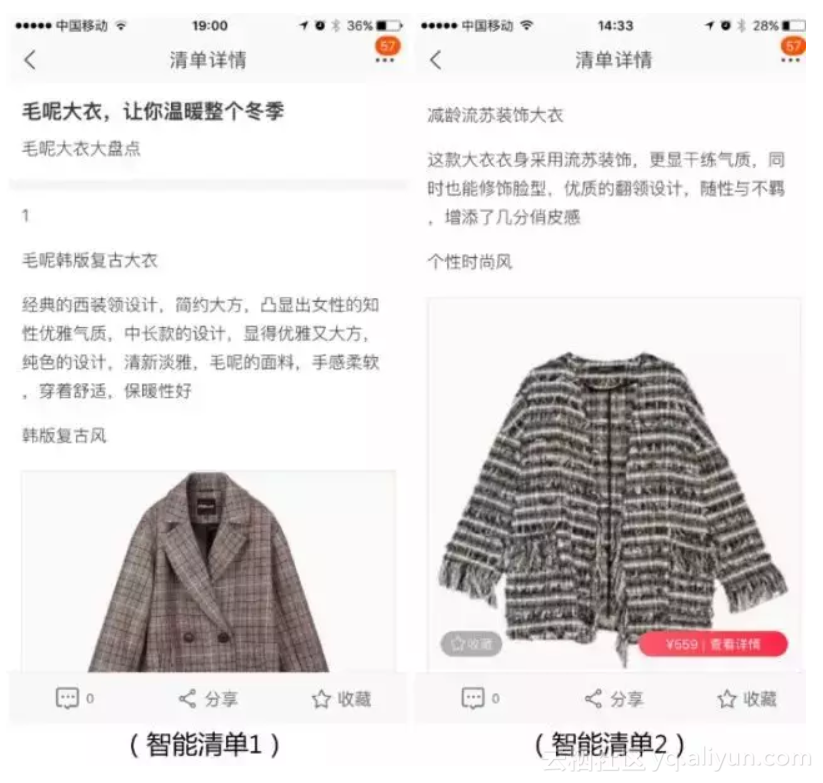
为了验证智能写手生成的清单的效果,我们在双十一期间小流量上线,和人工编辑的清单进行了分桶测试。对比人工编辑的单品盘点清单,智能写手清单在平均商品点击转化率上的表现要更好。
下面我们将分别介绍智能写手在智能利益点和图文清单生成两部分的工作。
二. 智能利益点
智能利益点解决的问题是,给定任意一个商品,挖掘这个商品各个潜在的卖点,并根据挖掘出来的用户偏好,从商品卖点集合中圈定用户最感兴趣、最可能点击的卖点,然后基于这些卖点实时生成一小段6个字以内的文案。利益点生成的解决方案主要分为这么几部分:
1.用户的偏好挖掘:主要基于用户的离线和实时行为数据来做,通过挖掘得到用户的TOP K个偏好标签集合。由于线上系统性能的限制,我们不可能使用用户所有行为过的标签,于是我们构建了用户偏好标签的排序模型对标签进行优选。
2.商品的卖点挖掘:卖点挖掘更多的依赖一些基础的数据,包括商品的标签库、属性库、人工编辑的信息等等。
3. 利益点文案的实时个性化生成:首先,我们提出了PairXNN模型,用于预估用户对一个商品的卖点的点击概率,然后,根据不同的场景要求选择合适的卖点,基于语义规则和人工设计的模板进行利益点文案的实时个性化生成。
下面主要介绍PairXNN的细节。
2.1 PairXNN概要
在商品卖点的点击率预估问题中,我们把用户偏好标签和商品卖点都用文本的方式进行了表示,因此我们选择的base模型是Aliaksei Severyn[1]的工作,他们的工作主要解决短文本pair的排序问题。在经过不断迭代实验优化后,我们最终形成了我们的PairXNN网络结构,如下图所示:
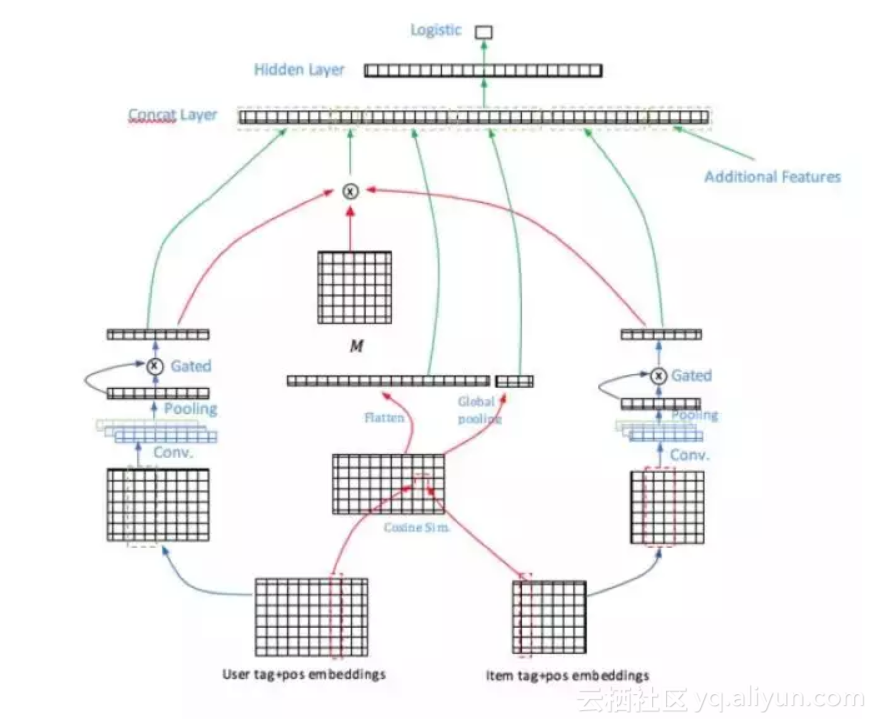
模型包含几个主要的部分:
1.用户偏好和商品卖点的语义表示:由于用户的偏好标签量比较大,如何对用户的大量偏好标签进行更深层次的偏好挖掘,是这个部分要解决的重点问题。
2.Multi-level的相似度模块:在不同的语义层级上计算用户偏好和商品卖点的相似度。
3.Additional Features:引入人工定义的额外的特征,辅助模型效果。例如用户偏好的特征、卖点的统计类特征、用户偏好和卖点的overlap特征等。
整个PairXNN模型的训练和在线预测是基于我们内部自研的XTensorflow平台进行搭建。
2.2 语义表示
在对用户侧的偏好标签做语义抽取的时候,考虑到用户偏好标签的特殊性,它不是一个真正的有合理语义意义的句子,因此我们尝试了多种不同的语义表示的网络结构,包括全连接DNN、和[1]一样的CNN、Gated CNN[3]、self-attention[2] 和tailored attention。
其中,Gated CNN是对传统的CNN结构做了优化,加入了gate机制,可以决定哪些信息更为重要,需要保留或者说舍去哪些信息。而采用Self-attention则是考虑到对于用户的偏好标签序列,需要更关注全局的语义相关性。tailored attention则是我们为了优化性能,简化语义表示网络所提出的新结构,因为智能利益点的场景都是重要场景,流量很大,对性能要求比较高。最终经过双十一期间的线上分桶测试,Gated CNN在网络性能和效果上综合最优,于是双十一全量上线的模型中采用Gated CNN的语义表示网络结构。
2.3 Multi-level相似度模块
除了上述对于user和item侧信息的映射和抽取,为了计算用户和利益点的相关性,我们从两个不同的语义层次对用户偏好标签和商品卖点的相似度计算,分别是:
1.对用户偏好标签embedding层输出和商品卖点embedding层输出的cosine similarity计算。
假定用户侧所有词的embedding矩阵为 ,商品侧词的embedding矩阵为 ,那么两侧词之间一一对应的余弦相似度(embedding已归一化)为:
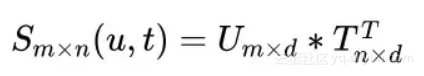
我们还在这个基础上做了global pooling,分别为max pooling/min pooling/average pooling,得到3个数值。将上式得到的相似度打平后,与pooling层得到的结果concat成一维向量共同输入至下一层。
2.对用户偏好标签的语义表示和商品卖点的语义表示计算bilinear similarity。
定义一个矩阵M去连接用户侧向量 ,商品侧向量 ,公式如下:
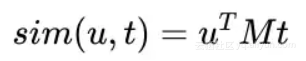
其中
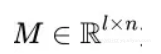
为相似度矩阵。这相当于将user侧的输入映射为 :
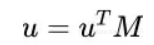
由于此时M是可训练的,这样就可以更好的将user侧和item侧的空间靠近,提升相似度的准确性。
线上实验结果表明,两个层次的相似度叠加使用的ctr要优于单独使用。
三. 图文型清单生成
一个图文型清单一般都有一个明确的主题,围绕这个主题进行相应的文本描述和商品推荐。针对这个特征,我们的解决方案包括以下几个部分:
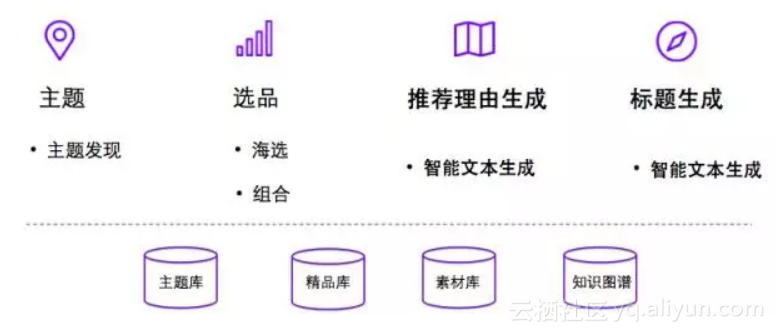
1.主题。这个主题可以由外界(运营)输入,也可以基于我们主题发现所沉淀的主题库进行选择。
2.选品。确定了主题之后,我们根据这个主题从精品库中选取和主题相关性高且质量不错的商品,然后以一定的目标组合成一个个的清单(一般一个清单包含6-10个商品)。
3.商品推荐理由生成。为每个清单的商品生成一段40-80个字的推荐理由。
4.标题生成。根据清单内的商品信息,给清单取一个概括主题又吸引用户点击的标题。清单标题要求相对简短,一般不长于20个字。例如:“懒人沙发椅,沉溺初秋慵懒美时光”。
3.1 Deep Generation Network
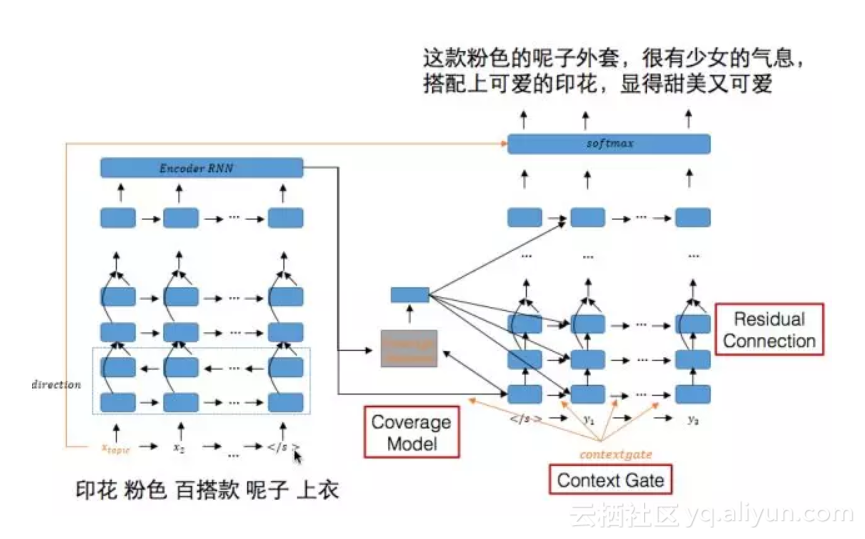
图文型清单生成中的两个模块,商品推荐理由的生成和标题生成,我们把他们归类为自然语言生成(NLG)问题,都可以定义为依赖输入信息的文本生成问题。其中,商品推荐理由生成问题中,输入的是商品的信息,而清单标题中输入的是商品集合的信息。于是,我们采用了最近比较流行的Encoder-Decoder深度神经网络模型框架来解决,基于Attention based Seq2Seq[5-6]的base model,最终形成了我们的Deep Generation Network。
下面介绍几个比较主要的部分。
3.1.1 样本
样本的质量和数量是模型效果的基础,我们基于淘宝上的人工编写的商品推荐理由数据和清单标题数据进行了清洗,筛选得到符合我们目标的样本集数据。
3.1.2 coverage attention model[8]
在推荐理由生成中经常会出现多个内容重复描述同一个输入信息的情况,或者是对于输入信息在推荐理由中没有涉及。这个问题类似于机器翻译问题中“过译”和“漏译”的问题。在传统的统计机器翻译方法中,有coverage set的概念,去记录输入source文本哪些已经被翻译过了,而之后的模型主要考虑将没有翻译过的文本进行翻译。在深度学习中,是通过coverage model的方式和attention model做结合,达到这样的效果。
原来attention的计算方式如下:
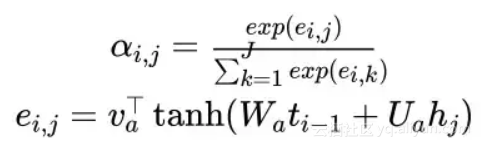

3.1.3 context gate[9]
在推荐理由的输出当中,模型的主体是基于RNN的seq2seq架构,那么在decoder的输出端的输出,主要受2部分影响:
1. 一部分是encoder的输入
2. 另一部分是当前step的前一个step的输出。
那么对于不同的输出,两部分的影响应该是不同的,比如说,当前一个输入词是虚词时,主要的信息应该由encoder影响,但是如果前一个词和当前词明显有相关性时,当前词的主要应该由前一个词影响。所以,我们考虑加入context gate,对这种情况进行建模。
公式如下:
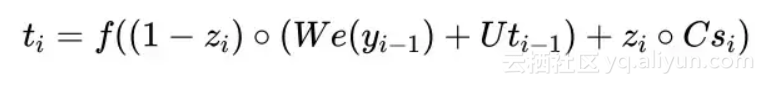

3.1.4 Beam Search
在前文中提到用RNN生成语句时,在每个时刻取输出结果中概率最大的词作为生成的词,是比较greedy的做法,没有考虑词的组合因素,因此,我们在seq2seq的实验中也尝试了beam search。beam search只在predict的时候使用,举个例子,当beam search size=2时,每个时刻都会保留当前概率最大的两个序列。
beam search在实践过程中很有用,它提供了一种很好的对生成序列进行干预的基础,一方面你可以对beam search的候选集的选择以及最终序列的选择做定制化的处理,比如你的选择目标,另一方面,对一些模型还不能完全保证解决的bad case(例如重复词出现等),可以在beam search中进行处理。
3.1.5 CNN
对于我们生成清单标题的问题,由于输入是多个商品的文本内容,商品文本之间并没有真正的序列关系,反而更需要一个类似主题特征抽取的部分,从而能根据主题进行标题的生成。而CNN在句子分类已经有不错的应用[7]了,于是我们在清单标题生成问题中,采用了CNN作为Encoder,实验结果也表明CNN比LSTM在标题生成的主题准确率上要高。
3.1.6 Reinforcement Learning
我们在训练和预测的时候会碰到下面2个问题:
1. 训练和预测的环境是不同的,训练在decoder的每次的输出,依赖的是前一个位置的ground truth的输入,而预测的时候是前一个位置predict的输出,原因是训练时候如果就依赖predict的结果的话,会造成损失累计,训练非常难收敛。
2. 我们的评价目标是BLEU[11]值,这是整个句子生成之后和样本之间的对比,而我们在训练的时候是对于每一个位置的predict label计算loss,那么造成了评价和训练目标的差别,并且BLEU是一个整体目标,相当于是个延迟的reward。
综上所述非常适合利用reinforcement learning的方式[10]来解决。对于这样一个强化学习问题,首先我们定义这个问题的3个要素:
1. action:每一个timestep选择的候选词
2. state:每一个timestep的hidden state
3. reward:最终的BLEU值
算法流程如下:
1. warm start:依旧利用原来的方法去训练模型,达到相对收敛的状态。
2. 逐渐在decode的末尾加入强化学习的方式,例如从倒数第一个位置加入强化学习,当收敛较好了,再从倒数第二个位置开始加入。
Loss定义如下:
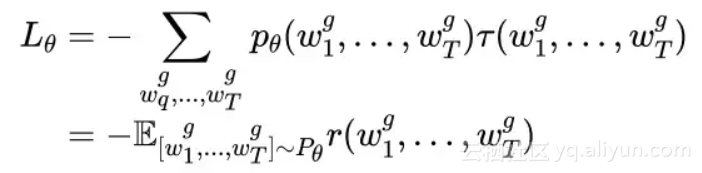
3. 选择的action的时候,使用的是KNN的方式。本文是使用REINFORCE算法,是policy gredient的方式,并且文本的action空间非常大,所以比较难收敛。我们使用原来的predict方式打分,分数高的N个词作为候选词。然后这些词和policy gredient选出的词,做KNN,距离是embedding后的距离,选择距离最近的作为action。
4. 最终,除了第一个timestep还保留着期望的输入,其余都将是强化学习的方式。
3.2 效果展示
这里展示部分在测试集上生成的标题和推荐理由,给大家一些直观的感觉:
清单标题
- 卫衣,穿出你的青春活力
- 加绒牛仔裤,让你的冬天更有范
- 牛仔外套,穿出帅气的你
- 羊羔毛外套,温暖整个冬天
- 穿上格子装,让你秒变女神
- 职场新人,职场穿搭指南
- 穿上白衬衫,做个安静的女子
- 穿上蕾丝,做个性感的女子
商品推荐理由
- 这件针织款连衣裙采用了v领的设计,露出性感的锁骨,性感显优雅,衣身的撞色拼接,丰富了视觉效果,更显时尚感。
- 简约的圆领设计,修饰颈部线条,中长款的设计,显得优雅又大方,干净素雅,展现出清新的文艺风格,在端庄中流露出一股优雅的气质。
- 假两件的设计,让你的身材更加的修长,宽松的版型,穿着舒适,不挑身材,时尚百搭,轻松穿出时尚感。
四. 展望
智能写手在双十一的智能利益点和图文清单生成上拿到了初步的效果,但是仍然还存在很多问题待解决,后续我们将在如下方面继续探索和优化:
1. 效果评估。现在采用BLEU、覆盖率、准确率、人工评测结合的方法来评估效果,但BLEU和实际目标不完全一致,人工评测成本又较高,需要有更好的评价方案。
2. 更丰富的输入信息。引入包括商品图像、用户评价等在内的信息,除了可以解决输入输出的不一致外,还能给用户提供更有价值的内容。
3.语言生成理解。通过模型的可视化,可以分析bad case的根源,优化模型。
4. 机器生成方面目前还有描述的准确度、多样性问题需要解决,另外考虑到很多缺少足够样本的业务也有生成的需求,模型是否能具备迁移能力也是一个可能的方向。
五. 关于团队
阿里巴巴推荐算法团队目前主要负责阿里电商平台(包括淘宝、天猫、Lazada等)的商品及feeds流推荐,其中用户导购场景个性化,首页首图个性化、猜你喜欢、购买链路等场景每天服务数亿用户,涉及智能文本生成、流量效率提升、用户体验、提高商家及达人参与淘宝的积极性,优化商业生态运行机制。
欢迎热爱算法,对业务有好奇心,有合作精神的同学一起工作、成长。简历可投邮箱:
shaoyao@taobao.com
或者guli.lingl@taobao.com
或者jinxin.hjx@alibaba-inc.com
西湖湖畔,翘首以盼,等你来信~
六. 参考文献
[1] Severyn A, Moschitti A. Learning to rank short text pairs with convolutional deep neural networks[C]//Proceedings of the 38th
International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 2015: 373-382.
[2] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin.
Attention is all you need. arXiv preprint arXiv:1706.03762,2017.
[3] Dauphin Y N, Fan A, Auli M, et al. Language modeling with gated convolutional networks[J]. arXiv preprint arXiv:1612.08083,2016.
[4] Luo W, Li Y, Urtasun R, et al. Understanding the effective receptive field in deep convolutional neural networks[C]//Advances in
Neural Information Processing Systems. 2016: 4898-4906.MLA
[5] Neural Machine Translation by Jointly Learning to Align and Translate
[6] Rush A M, Chopra S, Weston J. A neural attention model for abstractive sentence summarization[J]. arXiv preprint arXiv:1509.00685, 2015.
[7] Kim Y. Convolutional neural networks for sentence classification[J]. arXiv preprint arXiv:1408.5882, 2014.
[8] Tu Z, Lu Z, Liu Y, et al. Modeling coverage for neural machine translation[J]. arXiv preprint arXiv:1601.04811, 2016.
[9] Tu Z, Liu Y, Lu Z, et al. Context gates for neural machine translation[J]. arXiv preprint arXiv:1608.06043, 2016.
[10] Sequence Level Training with Recurrent Neural Networks, ICLR 2016.
[11] Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: A method for automatic evaluation of machine translation.
原文发布时间为:2018-01-25
本文作者:夜胧