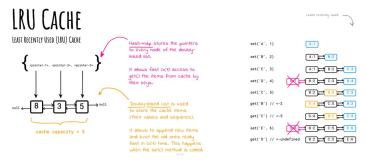
这个是比较经典的LRU(Least recently used,最近最少使用)算法,算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。 一般应用在缓存替换策略中。其中的”使用”包括访问get和更新set。
LRU算法
LRU是Least Recently Used 近期最少使用算法。内存管理的一种页面置换算法,对于在内存中但又不用的数据快(内存块)叫做LRU,Oracle会根据那些数据属于LRU而将其移出内存而腾出空间来加载另外的数据,一般用于大数据处理的时候很少使用的数据那么就直接请求数据库,如果经常请求的数据就直接在缓存里面读取。
最近最久未使用(LRU)的页面置换算法,是根据页面调入内存后的使用情况进行决策的。由于无法预测各页面将来的使用情况,只能利用“最近的过去”作为“最近的将来”的近似,因此,LRU置换算法是选择最近最久未使用的页面予以淘汰。该算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间t,当须淘汰一个页面时,选择现有页面中其t值最大的,即最近最久未使用的页面予以淘汰(可以使用这种方法去实现)。
LRU的实现
1) 可利用一个栈来保存当前使用的各个页面的页面号。每当进程访问某页面时,便将该页面的页面号从栈中移出,将它压入栈顶。因此,栈顶始终是最新被访问页面的编号,而栈底则是最近最久未使用页面的页面号。(由于效率过低在leetCode上超时,代码未贴出)
2) 也可以过双向链表和HashMap来实现。
双向链表用于存储数据结点,并且它是按照结点最近被使用的时间来存储的。 如果一个结点被访问了, 我们有理由相信它在接下来的一段时间被访问的概率要大于其它结点。于是, 我们把它放到双向链表的头部。当我们往双向链表里插入一个结点, 我们也有可能很快就会使用到它,同样把它插入到头部。 我们使用这种方式不断地调整着双向链表,链表尾部的结点自然也就是最近一段时间, 最久没有使用到的结点。那么,当我们的Cache满了, 需要替换掉的就是双向链表中最后的那个结点(不是尾结点,头尾结点不存储实际内容)。
如下是双向链表示意图,注意头尾结点不存储实际内容:
头 --> 结 --> 结 --> 结 --> 尾 结 点 点 点 结 点 <-- 1 <-- 2 <-- 3 <-- 点
假如上图Cache已满了,我们要替换的就是结点3。
哈希表的作用是什么呢?如果没有哈希表,我们要访问某个结点,就需要顺序地一个个找, 时间复杂度是O(n)。使用哈希表可以让我们在O(1)的时间找到想要访问的结点, 或者返回未找到。
java实现
LinkedHashMap恰好是通过双向链表实现的java集合类,它的一大特点是,以当某个位置被命中,它就会通过调整链表的指向,将该位置调整到头位置,新加入的内容直接放在链表头,如此一来,最近被命中的内容就向链表头移动,需要替换时,链表最后的位置就是最近最少使用的位置。关于 LinkedHashMap 的具体实现,可以参考此文:LinkedHashMap的实现原理。
假定现有一进程所访问的页面序列为:
4,7,0,7,1,0,1,2,1,2,6
随着进程的访问,栈中页面号的变化情况如图所示。在访问页面6时发生了缺页,此时页面4是最近最久未被访问的页,应将它置换出去。

题目的要求是实现下面三个方法:
class LRUCache{
public:
LRUCache(int capacity) {
}
int get(int key) {
}
void set(int key, int value) {
}
};
C++实现
// A simple LRU cache written in C++
// Hash map + doubly linked list
#include <iostream>
#include <vector>
#include <ext/hash_map>
using namespace std;
using namespace __gnu_cxx;
template <class K, class T>
struct Node{
K key;
T data;
Node *prev, *next;
};
template <class K, class T>
class LRUCache{
public:
LRUCache(size_t size){
entries_ = new Node<K,T>[size];
for(int i=0; i<size; ++i)// 存储可用结点的地址
free_entries_.push_back(entries_+i);
head_ = new Node<K,T>;
tail_ = new Node<K,T>;
head_->prev = NULL;
head_->next = tail_;
tail_->prev = head_;
tail_->next = NULL;
}
~LRUCache(){
delete head_;
delete tail_;
delete[] entries_;
}
void Put(K key, T data){
Node<K,T> *node = hashmap_[key];
if(node){ // node exists
detach(node);
node->data = data;
attach(node);
}
else{
if(free_entries_.empty()){// 可用结点为空,即cache已满
node = tail_->prev;
detach(node);
hashmap_.erase(node->key);
}
else{
node = free_entries_.back();
free_entries_.pop_back();
}
node->key = key;
node->data = data;
hashmap_[key] = node;
attach(node);
}
}
T Get(K key){
Node<K,T> *node = hashmap_[key];
if(node){
detach(node);
attach(node);
return node->data;
}
else{// 如果cache中没有,返回T的默认值。与hashmap行为一致
return T();
}
}
private:
// 分离结点
void detach(Node<K,T>* node){
node->prev->next = node->next;
node->next->prev = node->prev;
}
// 将结点插入头部
void attach(Node<K,T>* node){
node->prev = head_;
node->next = head_->next;
head_->next = node;
node->next->prev = node;
}
private:
hash_map<K, Node<K,T>* > hashmap_;
vector<Node<K,T>* > free_entries_; // 存储可用结点的地址
Node<K,T> *head_, *tail_;
Node<K,T> *entries_; // 双向链表中的结点
};
int main(){
hash_map<int, int> map;
map[9]= 999;
cout<<map[9]<<endl;
cout<<map[10]<<endl;
LRUCache<int, string> lru_cache(100);
lru_cache.Put(1, "one");
cout<<lru_cache.Get(1)<<endl;
if(lru_cache.Get(2) == "")
lru_cache.Put(2, "two");
cout<<lru_cache.Get(2);
return 0;
}
参考:http://hawstein.com/posts/lru-cache-impl.html;http://www.cnblogs.com/LZYY/p/3447785.html