文章copy link:http://cloudera.iteye.com/blog/889468 链接所有者保留所有权!
http://www.csdn.net/article/2013-05-10/2815222-cloudera-release-impala-1-0 【cloudera impala】
官方doc
https://wiki.cloudera.com/display/DOC/HBase+Installation
首先升级yum:
在 /etc/yum.repos.d/ 下创建cloudera-cdh3.repo 然后把



- [cloudera-cdh3]
- name=Cloudera's Distribution for Hadoop, Version 3
- mirrorlist=http://archive.cloudera.com/redhat/cdh/3/mirrors
- gpgkey = http://archive.cloudera.com/redhat/cdh/RPM-GPG-KEY-cloudera
- gpgcheck = 0
[cloudera-cdh3] name=Cloudera's Distribution for Hadoop, Version 3 mirrorlist=http://archive.cloudera.com/redhat/cdh/3/mirrors gpgkey = http://archive.cloudera.com/redhat/cdh/RPM-GPG-KEY-cloudera gpgcheck = 0
追加到cloudera-cdh3.repo 里。
然后执行:
yum update yum
参照:
https://wiki.cloudera.com/display/DOC/CDH3+Installation
安装hadoop:
更新好yum 就能通过yum 下载hadoop 了 很方便。
在集群中每个节点都下载hadoop
- yum install hadoop-0.2X
yum install hadoop-0.2X
然后创建hadoop用户(这里注意,下载了cloudera 的hadoop 后,会自动创建一个hadoop组和两个用户:mapred、hdfs 。 用户本人没用)
所以创建用户时必须加上 -g hadoop (吧hadoop 用户也加入hadoop组)
修改hadoop集群配置文件:
vi /etc/hadoop/conf/hdfs-site.xml
- <configuration>
- <property>
- <name>dfs.replication</name>
- <value>3</value> <!--hdfs 备份最好多做些,防止数据丢失-->
- </property>
- <property>
- <name>dfs.name.dir</name>
- <value>/data/namenode</value>
- </property>
- <property>
- <!-- specify this so that running 'hadoop namenode -format' formats the right dir -->
- <name>dfs.data.dir</name>
- <value>/data/datanode</value>
- </property>
- </configuration>
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value> <!--hdfs 备份最好多做些,防止数据丢失-->
</property>
<property>
<name>dfs.name.dir</name>
<value>/data/namenode</value>
</property>
<property>
<!-- specify this so that running 'hadoop namenode -format' formats the right dir -->
<name>dfs.data.dir</name>
<value>/data/datanode</value>
</property>
</configuration>
vi /etc/hadoop/conf/mapred-site.xml (因为hbase和mapreduce 没关系,所以这个配置文件没做详细修改)
- <configuration>
- <property>
- <name>mapred.job.tracker</name>
- <value>hbase150:9001</value>
- </property>
- <!--add fair schedualer -->
- <property>
- <name>mapred.jobtracker.taskScheduler</name>
- <value>org.apache.hadoop.mapred.FairScheduler</value>
- </property>
- <property>
- <name>mapred.fairscheduler.allocation.file</name>
- <value>/etc/hadoop/conf/pools.xml</value>
- </property>
- <!-- Enable Hue plugins -->
- <property>
- <name>mapred.jobtracker.plugins</name>
- <value>org.apache.hadoop.thriftfs.ThriftJobTrackerPlugin</value>
- <description>Comma-separated list of jobtracker plug-ins to be activated.
- </description>
- </property>
- <property>
- <name>jobtracker.thrift.address</name>
- <value>0.0.0.0:9290</value>
- </property>
- </configuration>
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hbase150:9001</value>
</property>
<!--add fair schedualer -->
<property>
<name>mapred.jobtracker.taskScheduler</name>
<value>org.apache.hadoop.mapred.FairScheduler</value>
</property>
<property>
<name>mapred.fairscheduler.allocation.file</name>
<value>/etc/hadoop/conf/pools.xml</value>
</property>
<!-- Enable Hue plugins -->
<property>
<name>mapred.jobtracker.plugins</name>
<value>org.apache.hadoop.thriftfs.ThriftJobTrackerPlugin</value>
<description>Comma-separated list of jobtracker plug-ins to be activated.
</description>
</property>
<property>
<name>jobtracker.thrift.address</name>
<value>0.0.0.0:9290</value>
</property>
</configuration>
vi /etc/hadoop/conf/core-site.xml
- <configuration>
- <property>
- <name>fs.default.name</name>
- <value>hdfs://hbase150:9000</value>
- </property>
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/data/tmp</value>
- </property>
- </configuration>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hbase150:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/tmp</value>
</property>
</configuration>
各节点之间的hadoop用户ssh无密码登陆以及其它细节这里就不说了,网上多的是,配置文件贴出来是希望分享下,或者接受大家 宝贵耳朵建议。
启动hdfs(不用启动mapreduce。):
执行 /usr/lib/hadoop/bin/start-dfs.sh
注意:启动会遇到用户权限问题。因为cloudera 吧hdfs相关的目录权限设置的是hdfs用户(mapreduce 也是) 所以这里就需要用root 把相关目录给hadoop: chown -R hadoop [目录名]
还有启动之前需要对namenode 进行format 这里会问是否真的要format [Y/N] 千万别输入小写的y 要输入大写.. 因为这个我郁闷了好久..
还有namenode 的safemode leave 的时候,出现没有权限的报错,提示大概是:需要更高权限的用户。 而我的用户是hadoop 对hdfs来说是最高权限的用户啊。郁闷了很久后 发现时namenode 没启动起来导致的。。。
hdfs成功启动后,安装zookeeper (hbase需要zookeeper)
hbase自带有zookeeper 我这里是自己安装zookeeper。
参照
https://wiki.cloudera.com/display/DOC/ZooKeeper+Installation
即可搭建起zookeeper集群
遇到的问题类似 ,同样是因为用cloudera 的zookeeper时会有目录所属用户问题。 把相关目录全chown 给hadoop就行。
还遇到个棘手的问题就是:参照上篇博客:
http://cloudera.iteye.com/blog/902949
还有,这里我没有用cloudera 的命令:
/etc/init.d/hadoop-zookeeper start
因为cloudera 的这个启动文件会自动su 到zookeeper 用户,而我全是用hadoop用户操作的。
所以我是用:
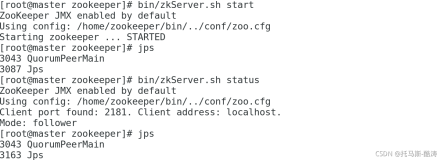
- /usr/lib/zookeeper/bin/zkServer.sh start
/usr/lib/zookeeper/bin/zkServer.sh start
启动的。
可用
- /usr/lib/zookeeper/bin/zkServer.sh status
/usr/lib/zookeeper/bin/zkServer.sh status
查看状态
用
- /usr/lib/zookeeper/bin/zkServer.sh stop
/usr/lib/zookeeper/bin/zkServer.sh stop
停止。
zookeeper集群安装完毕后即可安装hbase
安装hbase:
参照:
https://wiki.cloudera.com/display/DOC/HBase+Installation
我也没用cloudera 的启动,原因同上。
我用:
- /usr/lib/hbase/bin/start-hbase.sh
/usr/lib/hbase/bin/start-hbase.sh
启动。这里注意了,需要修改start-hbase.sh的源码。因为hbase会自动启动zookeeper 所以注释掉源码中的zookeeper启动的那行。
stop-hbase.sh亦是。
另外 这种启动方式还需要在master中配置/etc/hbase/conf/regionservers
这样只需在master 中执行启动hbase 的命令即可,不用再slaves 中逐一启动regionserver了。
最后,想说下,最好把日志log 都统一管理起来。我吧日志都放到/data/log 下了。 (/data目录是我专门用来放hadoop hbase 的东西的,namenode 和datanode 也全都在/data目录下。)