scala文件读写,序列化
import java.io._
import java.nio.file._
import scala.io.Source
object HelloWorld extends App {
println("打印所有的子目录")
implicit def makeFileVisitor(f: (Path) => Unit) = new SimpleFileVisitor[Path] {
override def visitFile(p: Path, attrs: attribute.BasicFileAttributes) = {
f(p)
FileVisitResult.CONTINUE
}
}
val dir: File = new File("D:/scalawork")
Files.walkFileTree(dir.toPath, (f: Path) => println(f))
println("打印所有的文件")
def subdirs(dir: File): Iterator[File] = {
val children = dir.listFiles.filter(_.isDirectory)
children.toIterator ++ children.toIterator.flatMap(subdirs _)
}
subdirs(new File("D:/scalawork")).foreach { println _ }
println("写文件")
val out = new PrintWriter("numbers.txt")
for (i <- 1 to 100) out.println(i)
// use string format
val quantity = 100
val price = .1
out.print("%6d %10.2f".format(quantity, price))
out.close()
println("读文件")
val lines = Source.fromFile("numbers.txt").getLines()
lines.foreach { println _ }
println("读取二进制文件")
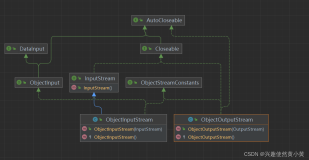
class Student(val name: String, val sex: Short, val addr: String) extends Serializable {
override def toString(): String = {
"name:%s,sex:%d,addr:%s".format(name, sex, addr)
}
}
val studentA = new Student("张三", 2, "广州")
val studentB = new Student("李四", 2, "广州")
val outObj = new ObjectOutputStream(new FileOutputStream("student.obj"))
outObj.writeObject(studentA)
outObj.writeObject(studentB)
outObj.close()
val in = new ObjectInputStream(new FileInputStream("student.obj"))
println(in.readObject().asInstanceOf[Student])
println(in.readObject().asInstanceOf[Student])
//读取二进制文件
var in = None: Option[FileInputStream]
var out = None: Option[FileOutputStream]
try {
in = Some(new FileInputStream("/tmp/Test.class"))
out = Some(new FileOutputStream("/tmp/Test.class.copy"))
var c = 0
while ({ c = in.get.read; c != -1 }) {
out.get.write(c)
}
} catch {
case e: IOException => e.printStackTrace
} finally {
println("entered finally ...")
if (in.isDefined) in.get.close
if (out.isDefined) out.get.close
}
}