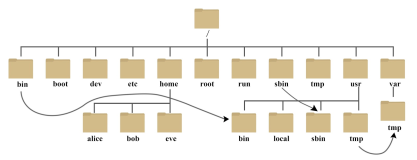
find--在某个指定的路径下查找需要的文件或目录
格式:
find [查找位置] [查找标准] [处理动作]
查找位置:默认为当前目录,可以指定多个目录,多个之间用空格
查找标准:默认为查找指定目录下的所有文件
处理动作:显示到标准输出,默认为print
查找标准
以文件名查找
-name "文件名称" : 根据文件名查找,支持glob(文件名通配),注意文件名需用双引号
|
1
2
3
4
5
6
7
|
[root@localhost ~]
# find /etc/ -name "ifcfg-eth0"
/etc/sysconfig/network-scripts/ifcfg-eth0
[root@localhost ~]
# find /etc/ -name "ifcfg*"
/etc/sysconfig/network-scripts/ifcfg-eth0
/etc/sysconfig/network-scripts/ifcfg-lo
/etc/sysconfig/network-scripts/ifcfg-eth0bak
[root@localhost ~]
#
|
-iname "文件名称",根据文件名查找,不区分大小写
|
1
2
3
4
5
6
|
[root@localhost ~]
# mkdir Justin juStin jusTin
[root@localhost ~]
# find -iname "justin"
.
/juStin
.
/jusTin
.
/Justin
[root@localhost ~]
#
|
以文件的属性查找
-user "USERNAME" ----根据属主查找
-group "GROUP" --- 根据属组查找
-uid "UID" ---根据UID查找
-gid "GID" ---根据GID查找
-nouser--- 查找没有属主的文件
-nogroup--- 查找没有属组的文件
|
1
2
3
4
5
|
#在/dev目录下查找用户名为root组为disk的文件并用长格式显示
[root@localhost ~]
# find /dev/ -user root -a -group disk -ls
10630 0 crw-rw---- 1 root disk 9月 24 10:18
/dev/sg0
10241 0 brw-rw---- 1 root disk 9月 24 10:18
/dev/ram3
9915 0 brw-rw---- 1 root disk 9月 24 2013
/dev/ram1
|
多条件查找连接符
-a: 与
-o: 或
-not、!:非
|
1
2
3
4
5
6
|
[root@localhost home]
# ls
111.txt 222.log justin justin1 justin2
[root@localhost home]
# find /home/ -name "*.txt" -o -name "*.log"
/home/222
.log
/home/111
.txt
[root@localhost home]
# find /home/ -name "*.txt" -a -name "*.log"
|
以文件类型查找
-type 文件类型
文件类型指的是普通文件(f)、目录(d)、块设备文件(b)、字符设备文件(c)、符号链接文件(l)、命令管道文件(p)、套接字文件(s)等
|
1
2
3
4
5
|
[root@localhost ~]
# find /bin/ -type l
/bin/mail
/bin/rview
/bin/ex
/bin/gtar
|
以文件大小查找
-size”大小条件
一般使用“+”、“-”号设置超过或小于指定的大小作为查找条件。常用的容量单位包括k(注意是小写)、M、G。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
[root@localhost ~]
# find /root/ -size 2k ;大小为2K的文件
/root/
.gconf
/apps/brasero/config/priority/
%gconf.xml
/root/
.gconf
/desktop/gnome/accessibility/keyboard/
%gconf.xml
/root/
.gnote
/89099c13-c354-48d6-89ce-0415b1db3c78
.note
/root/
.gnote
/db520e7c-3433-4433-b35a-3ad9a14e16d4
.note
/root/anaconda-ks
.cfg
[root@localhost ~]
# find /root/ -size +50k ;大小超过50k的文件
/root/
.cache
/ibus/pinyin/user-1
.3.db
/root/
.cache
/ibus/bus/registry
.xml
/root/
.pulse
/8665cfcff9c76f94fac16e0000000022-device-volumes
.tdb
/root/
.gstreamer-0.10
/registry
.i386.bin
/root/
.gconfd
/saved_state
[root@localhost ~]
#
|
-empty 空文件(目录)
|
1
|
[root@localhost ~]
# find -empty /
|
-maxdepth 限制find命令在目录中按照递减方式查找文件的时候搜索文件超过某个级别或者搜索过多的目录
|
1
|
[root@localhost ~]
# find . -maxdepth 2 -name fred
|
假如这个fred文件在./sub1/fred目录中,那么这个命令就会直接定位这个文件,查找很容易成功。假如,这个文件在./sub1/sub2/fred目录中,那么这个命令就无法查找到。因为前面已经给find命令在目录中最大的查询目录级别为2,只能查找2层目录下的文件。这样做的目的就是为了让find命令更加精确的定位文件,如果你已经知道了某个文件大概所在的文件目录级数,那么加入-maxdepth n 就很快的能在指定目录中查找成功。
以文件修改时间查找
-atime [+|-]# : access time访问时间,默认为天,#表示#天的这个时间点,+#表示至少有#天没访问, -#表示#天之内有访问
-mtime [+|-]# : modify time修改时间,#表示#天的这个时间点没有被修改,+#表示至少有#天没有修改 , -#表示#天之内有修改
-ctime [+|-]# : change time改变时间,#表示#天的这个时间点没有被改变,+#表示至少有#天没有被改变 , -#表示#天之内有被改变
mtime和ctime的区别在于,只有修改了文件的内容,才会更新文件的mtime,而对文件更名,修改文件的属主等操作,只会更新ctime。举例说明: 对文件进行mv操作,mtime不变,ctime更新;编辑文件内容,mtime和ctime同时修改。
-amin [+|-]# :时间为分钟,#表示#分钟的这个时间点没有被访问,+#表示至少有#分钟没有被访问 , -#表示#分钟之内访问
-mmin [+|-]# :时间为分钟,#表示#分钟的这个时间点没有被修改,+#表示至少有#分钟没有被修改 , -#表示#分钟之内有被修改
-cmin [+|-]# :时间为分钟,#表示#分钟的这个时间点没有被改变,+#表示至少有#分钟没有被改变 , -#表示#分钟之内有被改变
|
1
2
|
[root@localhost logs]
# find /opt/queryweb/logs -mtime +7 -type f -name "*.log" -exec rm -f {} \;
[root@localhost logs]
#
|
以文件权限查找
-perm [+|-] MODE
不带[+|-]表示精确权限匹配,
+表示任何一类用户的任何一位权限匹配
- 表示每类用户的每位权限都匹配
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
#精确匹配/etc下权限为755的文件。ugo都必须同时满足
[root@localhost ~]
# find /etc/ -perm 755 -ls |more
622593 16 drwxr-xr-x 98 root root 12288 Aug 6 14:39
/etc/
622778 8 drwxr-xr-x 2 root root 4096 Jan 12 2007
/etc/jvm
622638 8 drwxr-xr-x 2 root root 4096 Aug 2 16:44
/etc/xinetd
.d
#755用二进制表示为111 101 101;+后跟权限匹配原则是满足所有权限位的一个位就可以
[root@localhost ~]
# find /etc/ -perm +755 -ls |more
622593 16 drwxr-xr-x 98 root root 12288 Aug 6 14:39
/etc/
622625 8 -rw-r--r-- 1 root root 135 Aug 6 13:31
/etc/printcap
622645 20 -rw-r--r-- 1 root root 14100 Sep 5 2006
/etc/mime
.types
#-后跟权限匹配原则是ugo中所有位权限必须同时满足,属主必须为rwx,属组和other至少为rw
[root@localhost ~]
# find /etc/ -perm -755 -ls |more
622593 16 drwxr-xr-x 98 root root 12288 Aug 6 14:39
/etc/
622778 8 drwxr-xr-x 2 root root 4096 Jan 12 2007
/etc/jvm
622638 8 drwxr-xr-x 2 root root 4096 Aug 2 16:44
/etc/xinetd
.d
|
处理动作
-print---find命令将匹配的文件输出到标准输出。
-exec---对匹配的文件执行该参数所给出的shell命令。相应命令的形式为'command' {} \;,注意{}和\;之间的空格,同时两个{}之间没有空格
-ok---和-exec的作用相同,只不过以一种更为安全的模式来执行该参数所给出的shell命令,在执行每一个命令之前,都会给出提示,让用户来确定是否执行。
|
1
2
3
4
5
6
7
8
9
10
11
|
# 在当前目录下查找除目录以外的所有类型的文件 ,并打印出来
[root@localhost
test
]
# find . ! -type d –print
#查找root目录下的以log结尾的文件,将其复制到test目录下。
[root@localhost
test
]
# find /root –name “*log” –type f –exec cp {} /root/test/ \; 2>/dev/null
#通过-exec参数指定后面要执行的命令,{}表示将查找到的内容全部复制,\;表示命令的结束,2>/dev/null是指将执行查找过程中出现的错误信息重定向到黑洞文件中,也就是不显示那些错误信息。
#长格式显示test下的普通文件
[root@localhost
test
]
# find . -type f -exec ls -l { } \;
#***test下大小为0的文件
[root@localhost
test
]
# find ./ -size 0 -exec rm {} \;
#在当前目录中查找所有文件名以.conf结尾、更改时间在5日以上的文件,并***它们,只不过在***之前先给出提示
[root@localhost
test
]
# find . -name "*.conf" -mtime +5 -ok rm { } \;
|
/dev/null,外号叫"黑洞",它等价于一个只写文件,所有写入它的内容都会永远丢失.,而尝试从它那儿读取内容则什么也读不到。如果不想让消息以标准输出显示或写入文件,那么可以将消息重定向到它。
/dev/zero主要的用处是用来创建一个指定长度用于初始化的空文件,就像临时交换文件。
xargs
在使用find命令的-exec选项处理匹配到的文件时, find命令将所有匹配到的文件一起传递给exec执行。但有些系统对能够传递给exec的命令长度有限制,这样在find命令运行几分钟之后,就会出现溢出错误。错误信息通常是“参数列太长”或“参数列溢出”。find命令把匹配到的文件传递给xargs命令,而xargs命令每次只获取一部分文件而不是全部,这样它可以先处理最先获取的一部分文件,然后是下一批,并如此继续下去。
在有些系统中,使用-exec选项会为处理每一个匹配到的文件而发起一个相应的进程,并非将匹配到的文件全部作为参数一次执行;这样在有些情况下就会出现进程过多,系统性能下降的问题,因而效率不高;
而使用xargs命令则只有一个进程。另外,在使用xargs命令时,究竟是一次获取所有的参数,还是分批取得参数,以及每一次获取参数的数目都会根据该命令的选项及系统内核中相应的可调参数来确定。
|
1
2
3
4
5
6
7
8
9
|
#查找系统中的每一个普通文件,然后使用xargs命令来测试它们分别属于哪类文件[root@localhost ~]# find . -type f -print | xargs file
#在整个系统中查找内存信息转储文件(core dump) ,然后把结果保存到/tmp/core.log 文件中:
[root@localhost ~]
# find / -name "core" -print | xargs echo "" >/tmp/core.log
#用grep命令在所有的普通文件中搜索hostname这个词
[root@localhost ~]
# find . -type f -print | xargs grep "hostname"
#***3天以前的所有东西 (find . -ctime +3 -exec rm -rf {} \;)
[root@localhost ~]
# find ./ -mtime +3 -print|xargs rm -f –r
#***文件大小为零的文件
[root@localhost ~]
# find ./ -size 0 | xargs rm -f &
|
xargs
xargs命令是给其他命令传递参数的一个过滤器,也是组合多个命令的一个工具。它擅长将标准输入数据转换成命令行参数,默认从管道传来的值是放在最后的
xargs能够处理管道或者stdin并将其转换成特定命令的命令参数。xargs是构建单行命令的重要组件之一。
xargs也可以将单行或多行文本输入转换为其他格式,例如多行变单行,单行变多行。xargs的默认命令是echo,空格是默认定界符。这意味着通过管道传递给xargs的输入将会包含换行和空白,不过通过xargs的处理,换行和空白将被空格取代。xargs是构建单行命令的重要组件之一。如下:
|
1
2
3
4
5
6
7
8
9
|
[root@localhost ~]
# cat xargs.txt
1 2 3 4
a b c d
A B C D
a1 b2 c3 d4
A1 B2 C3 D4
[root@localhost ~]
# cat xargs.txt | xargs
1 2 3 4 a b c d A B C D a1 b2 c3 d4 A1 B2 C3 D4
[root@localhost ~]
#
|
-0 当sdtin含有特殊字元时候,将其当成一般字符,像/'空格等
-a file 从文件中读入作为sdtin
|
1
2
3
4
5
6
7
8
9
|
[root@localhost ~]
# cat xargs.txt
1 1 1 1
2 2
3 3 3
4 4 4 4
5 5 5 5
[root@localhost ~]
# xargs -a xargs.txt
1 1 1 1 2 2 3 3 3 4 4 4 4 5 5 5 5
[root@localhost ~]
#
|
-e flag ,注意有的时候可能会是-E,flag必须是一个以空格分隔的标志,当xargs分析到含有flag这个标志的时候就停止。
|
1
2
3
|
[root@localhost ~]
# cat xargs.txt |xargs -E "3" echo
1 1 1 1 2 2
[root@localhost ~]
#
|
-p 操作具有可交互性,每次执行comand都交互式提示用户选择
|
1
2
3
4
|
[root@localhost ~]
# cat xargs.txt |xargs -p echo
echo
1 1 1 1 2 2 3 3 3 4 4 4 4 5 5 5 5 ?...y
1 1 1 1 2 2 3 3 3 4 4 4 4 5 5 5 5
[root@localhost ~]
#
|
-n xargs 的-n选项设置每次送给command命令的参数个数,参数以空白字符或<newline>换行符分割
|
1
2
3
4
5
6
7
8
|
[root@localhost ~]
# cat xargs.txt |xargs -n 3 echo
1 1 1
1 2 2
3 3 3
4 4 4
4 5 5
5 5
[root@localhost ~]
#
|
-t 启用命令行输出模式:其先回显要运行的命令,然后执行命令,打印出命令结果,跟踪与调试xargs的利器,也是研究xargs运行原理的好办法;
-i -i 选项告诉 xargs 可以使用{}代替传递过来的参数, 建议使用-I,其符合POSIX标准
-I 格式: xargs -I rep-str comand rep-srt rep-str 为代替传递给xargs参数, 可以使 {} $ @ 等符号 ,其主要作用是当xargs command 后有多个参数时,调整参数位置。eg:find . -name "*.txt " |xargs -I {} cp {} /tmp ;默认管道会将find的结果传递给cp做为最后的参数,通过-I来指定起传递过来参数的未知
-r 如果没有要处理的参数传递给xargsxargs 默认是带 空参数运行一次,如果你希望无参数时,停止 xargs,直接退出,使用 -r 选项即可,其可以防止xargs 后面命令带空参数运行报错。If the standard input does not contain any nonblanks, do not run the command, exit
-s size 设置每次构造Command行的长度总大小,包括 command +init-param +传递参数,Size 参数必须是正整数
-L num Use at most max-lines nonblank input lines per command line.-s是含有空格的。
-l 同-L
-d delim 分隔符,默认的xargs分隔符是回车,argument的分隔符是空格,这里修改的是xargs的分隔符
|
1
2
3
4
5
6
7
8
9
|
[root@localhost ~]
# echo "51ctox51ctox51cto"|xargs -dx
51cto 51cto 51cto
[root@localhost ~]
# echo "51ctox51ctox51cto"|xargs -n1 -dx
51cto
51cto
51cto
[root@localhost ~]
#
|
-x exit的意思,主要是配合-s使用。
-P 修改最大的进程数,默认是1,为0时候为as many as it can ,这个例子我没有想到,应该平时都用不到的吧。
查找并显示文件
找到某个文件是我们的目的,我们更想知道查找到的文件的详细信息和属性,如果我们采取现查找文件,在使用LS命令来查看文件信息是相当繁琐的,现在我们也可以把这两个命令结合起来使用。
|
1
2
3
|
[root@localhost ~]
# find / -name "httpd.conf" -ls
12063 34 -rw-r--r-- 1 root root 33545 Dec 30 15:36
/etc/httpd/conf/httpd
.conf
[root@localhost ~]
#
|
find命令配合使用exec和xargs可以使用户对所匹配到的文件执行几乎所有的命令。
which---查找外部命令所对应的程序文件
|
1
2
3
4
5
6
7
8
|
[root@localhost ~]
# which ls
alias
ls
=
'ls --color=auto'
/bin/ls
[root@localhost ~]
# which pwd
/bin/pwd
[root@localhost ~]
# which cd
/usr/bin/which
: no
cd
in
(
/usr/lib/qt-3
.3
/bin
:
/usr/local/sbin
:
/usr/local/bin
:
/sbin
:
/bin
:
/usr/sbin
:
/usr/bin
:
/root/bin
)
[root@localhost ~]
#
|
说明:which命令用于查找Linux外部命令所对应的程序文件,其搜索范围由环境变量PATH决定,在PATH变量指定的路径中,搜索某个系统命令的位置,并且返回第一个搜索结果。也就是说,使用which命令,就可以看到某个系统命令是否存在,以及执行的到底是哪一个位置的命令,执行命令后,首先显示出系统中所设置命令的别名,然后是命令的程序文件如“/bin/ls”。如果要查找的是一个内部命令,那将找不到任何对应的程序文件如cd。
whereis---查找文件或目录
-b---只找二进制文档
-m---只查找manual路径下的文件
-s---只查找source下的
-u---查找以上三个找不到的文件档案
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
[root@localhost ~]
# whereis pwd
pwd
:
/bin/pwd
/usr/share/man/man1/pwd
.1.gz
/usr/share/man/man1p/pwd
.1p.gz
[root@localhost ~]
# whereis etc
etc:
/usr/local/etc
[root@localhost ~]
# whereis -b pwd
pwd
:
/bin/pwd
[root@localhost ~]
# whereis -m pwd
pwd
:
/usr/share/man/man1/pwd
.1.gz
/usr/share/man/man1p/pwd
.1p.gz
[root@localhost ~]
# whereis -s pwd
pwd
:
[root@localhost ~]
# whereis -u pwd
pwd
:
/bin/pwd
/usr/share/man/man1/pwd
.1.gz
/usr/share/man/man1p/pwd
.1p.gz
[root@localhost ~]
#
|
说明:只能用于程序名的搜索,而且只搜索二进制文件(参数-b)、man说明文件(参数-m)和源代码文件(参数-s),如果省略参数,则返回所有信息
locate---查找文件
|
1
2
3
4
5
|
#查找/etc下pass开头的文件
[root@localhost ~]
# locate /etc/pass
/etc/passwd
/etc/passwd-
[root@localhost ~]
#
|
说明:locate命令其实是“find -name”的另一种写法,但是要比后者快得多,原因在于它不搜索具体目录,而是搜索一个数据库(/var/lib/locatedb),这个数据库中含有本地所有文件信息。Linux系统自动创建这个数据库,并且每天自动更新一次,所以使用locate命令查不到最新变动过的文件。为了避免这种情况,可以在使用locate之前,先使用updatedb命令,手动更新数据库
grep---Global Regular Expression Print全局搜索正则表达式并将结果打印出来---在文件中查找并显示包含指定字符串的行,目标是字符串
格式:grep [参数] 查找条件 目标文件
功能说明:grep指令是一种强大的文本搜索工具,是一个对行进行搜索的操作,它能使用正则表达式搜索文本,用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设grep指令会把含有范本样式的那一行显示出来。若不指定任何文件名称,或是所给予的文件名为“-”,则grep指令会从标准输入设备读取数据。
Unix的grep家族包括grep、egrep和fgrep。 egrep表示扩展的grep,相比grep支持更多的元字符(元字符就是指那些在正则表达式中具有特殊意义的专用字符),"grep -E"相当于egrep。fgrep是fast grep,不支持元字符,但是搜索速度更快。grep搜索的结果被送到屏幕,不影响原文件内容。
grep搜索建议:
匹配字符串、调用变量时建议使用双引号:grep "ZOO_INFO" zookeeper.log g r e p“$ M Y VA R” zookeeper.log
正则匹配应使用单引号:grep ‘\<ZOO_INFO\>’ zookeeper.log
--color=auto 匹配的关键用颜色显示出来

如果每次使用 grep 都得要自行加上 --color=auto 需要在 ~/.bashrc 内加上这行:『alias grep='grep --color=auto'』再以『 source ~/.bashrc 』来立即生效即可

|
1
|
[root@justin ~]
# source /root/.bashrc
|
-v---反向查找,即输出与查找条件不相符的行

-i或--ignore-case---忽略字符大小写的差别
|
1
2
3
4
5
6
7
8
9
10
11
|
[root@localhost home]
# echo "a" > i
[root@localhost home]
# echo "A" >> i
[root@localhost home]
# cat i
a
A
[root@localhost home]
# grep "a" i
a
[root@localhost home]
# grep -i "a" i
a
A
[root@localhost home]
#
|
-E---多个字符串一起搜寻,就是egrep
|
1
|
[root@justin ~]
# cat /etc/samba/smb.conf |egrep -v '#|;'
|
过滤掉#号和;号的行
-A<显示行数n>或--after-context=<显示行数n> 除了显示符合范本样式的那一列之外,并显示该行之后n行的内容。
|
1
2
3
4
5
6
7
|
[root@localhost ~]
# cat /boot/grub/grub.conf | grep -A 2 title
title Red Hat Enterprise Linux (2.6.32-279.el6.i686)
root (hd0,0)
kernel
/vmlinuz-2
.6.32-279.el6.i686 ro root=UUID=31d213fb-c46d-4b1d-9300-f43c0c7afb94 rd_NO_LUKS KEYBOARDTYPE=pc KEYTABLE=us rd_NO_MD crashkernel=auto LANG=zh_CN.UTF-8 rd_NO_LVM rd_NO_DM rhgb quiet
[root@localhost ~]
# cat /boot/grub/grub.conf | grep title
title Red Hat Enterprise Linux (2.6.32-279.el6.i686)
[root@localhost ~]
#
|
-B<显示行数n>或--before-context=<显示行数n> 除了显示符合范本样式的那一行之外,并显示该行之前n行内容
|
1
2
3
4
5
|
[root@localhost ~]
# cat /boot/grub/grub.conf | grep -B 2 title
splashimage=(hd0,0)
/grub/splash
.xpm.gz
hiddenmenu
title Red Hat Enterprise Linux (2.6.32-279.el6.i686)
[root@localhost ~]
#
|
-C<显示行数n>或--context=<显示行数n>或-<显示行数n> 除了显示符合范本样式的那一行之外,并显示该行之前后n行的内容。
|
1
2
3
4
5
6
7
|
[root@localhost ~]
# cat /boot/grub/grub.conf | grep -C 2 title
splashimage=(hd0,0)
/grub/splash
.xpm.gz
hiddenmenu
title Red Hat Enterprise Linux (2.6.32-279.el6.i686)
root (hd0,0)
kernel
/vmlinuz-2
.6.32-279.el6.i686 ro root=UUID=31d213fb-c46d-4b1d-9300-f43c0c7afb94 rd_NO_LUKS KEYBOARDTYPE=pc KEYTABLE=us rd_NO_MD crashkernel=auto LANG=zh_CN.UTF-8 rd_NO_LVM rd_NO_DM rhgb quiet
[root@localhost ~]
#
|
-c或--count 计算符合范本样式行数。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
[root@localhost ~]
# cat /boot/grub/grub.conf | grep -c 2.6.32
3
[root@localhost ~]
# cat /boot/grub/grub.conf
# grub.conf generated by anaconda
#
# Note that you do not have to rerun grub after making changes to this file
# NOTICE: You have a /boot partition. This means that
# all kernel and initrd paths are relative to /boot/, eg.
# root (hd0,0)
# kernel /vmlinuz-version ro root=/dev/sda2
# initrd /initrd-[generic-]version.img
#boot=/dev/sda
default=0
timeout=5
splashimage=(hd0,0)
/grub/splash
.xpm.gz
hiddenmenu
title Red Hat Enterprise Linux (2.6.32-279.el6.i686)
root (hd0,0)
kernel
/vmlinuz-2
.6.32-279.el6.i686 ro root=UUID=31d213fb-c46d-4b1d-9300-f43c0c7afb94 rd_NO_LUKS KEYBOARDTYPE=pc KEYTABLE=us rd_NO_MD crashkernel=auto LANG=zh_CN.UTF-8 rd_NO_LVM rd_NO_DM rhgb quiet
initrd
/initramfs-2
.6.32-279.el6.i686.img
[root@localhost ~]
#
|
-r或--recursive 递归的搜索
当要只知道要查找的字符串大致的目录位置不清除具体路径,通过递归搜索查找到
-L:输出时只显示不包含匹配项的文件名。
-l ----只显示匹配字符串的文件名不显示匹配的行,通常和-r 一起使用
|
1
2
3
4
5
6
7
8
9
10
11
|
[root@justin ~]
# mkdir -p /home/grep/{grep1,grep2}
[root@justin ~]
# touch /home/grep/grep1/a.txt
[root@justin ~]
# echo "1 2 3" > /home/grep/grep1/a.txt
[root@justin ~]
# touch /home/grep/grep1/1.txt
[root@justin ~]
# echo "a b c" > /home/grep/grep1/1.txt
[root@justin ~]
# grep "a" /home/grep/
[root@justin ~]
# grep "a" -r /home/grep/
/home/grep/grep1/1
.txt:a b c
[root@justin ~]
# grep "a" -rl /home/grep/
/home/grep/grep1/1
.txt
[root@justin ~]
#
|
-n或--line-number---在显示符合范本样式的那一行之前,标示出该列的行数编号
|
1
2
3
|
[root@localhost ~]
# cat /boot/grub/grub.conf | grep -n title
14:title Red Hat Enterprise Linux (2.6.32-279.el6.i686)
[root@localhost ~]
#
|
-o:只显示被模式匹配到的字符串,而不是整个行
|
1
2
3
|
[root@localhost ~]
# cat /boot/grub/grub.conf | grep -no title
14:title
[root@localhost ~]
#
|
-h:输出时每行行首不显示文件名
。-H:输出时每行行首显示文件名。
-w, –word-regexp:精确匹配,匹配单词还不是字符串,如想匹配“justin”,”justin_peng”就不会被匹配
\<: 单词锚定词首,例如\<r..t 那么root、rooter均可以匹配,而chroot就不能匹配
\>: 单词锚定词尾,例如r..t\> 那么root、chroot均可匹配,而chroot就不能匹配,如果要锚定root 可以使用\<root\>
|
1
2
3
4
5
6
7
8
9
|
[root@justin home]
# cat grep.txt
justin
justin_peng
[root@justin home]
# grep "justin" grep.txt
justin
justin_peng
[root@justin home]
# grep -w "justin" grep.txt
justin
[root@justin home]
#
|
-R, -r, –recursive:递归搜索, 查找你搜索的目录或子目录下的所有含有某个你要找的文件.
|
1
2
3
4
5
6
|
[root@justin
grep
]
# grep "justin" /home/
[root@justin
grep
]
# grep -R "justin" /home/
/home/grep/grep
.txt:justin
/home/grep
.txt:justin
/home/grep
.txt:justin_peng
[root@justin
grep
]
#
|
正则匹配:
符号”[]“表示匹配指定范围内的任意单个字符,'passw[Oo]rd'匹password和passwOrd
|
1
2
3
4
5
6
|
[root@justin ~]
# echo "password" > /home/grep/grep1/a.txt
[root@justin ~]
# echo "passwOrd" >> /home/grep/grep1/a.txt
[root@justin ~]
# grep -nr 'passw[oO]rd' /home/grep/
/home/grep/grep1/a
.txt:1:password
/home/grep/grep1/a
.txt:2:passwOrd
[root@justin ~]
#
|
[] 里面不论有几个字节,他都谨一个一个字节的匹配,也就是只会匹配password和passwOrd,而不会匹配passwoOrd,在一组集合字节中,如果该字节组是连续的,例如大写英文/小写英文/数字等等, 就可以使用[a-z],[A-Z],[0-9],[a-zA-Z]等方式来书写
如果要匹配空格,最好用空格的[:space:]来匹配,如果直接用空格来匹配那么tab产生的空格是不会匹配的
|
1
|
[root@justin ~]
# grep '[[:space:]]' grep.txt
|
[[:alpha:]] 代表英文大小写字母 a-z A-Z
[[:upper:]] :表示大写字母[A-Z]
[[:alnum:]]: 所有的字母和数字
[[:blank:]] [[:space:]] 代表空格键与 [Tab] 按键两者
[[:digit:]] :表示数字 [0-9]
符号"[^]"表示匹配指定范围之外的任意单个字符,如:'[^a-fA-F]oo'匹配不包含A-F和a-f的一个字母开头,紧跟oo的行。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
[root@justin ~]
# echo "Google" > /home/grep/grep1/1.txt
[root@justin ~]
# echo "google" >> /home/grep/grep1/1.txt
[root@justin ~]
# echo "Foogle" >> /home/grep/grep1/1.txt
[root@justin ~]
# echo "foogle" >> /home/grep/grep1/1.txt
[root@justin ~]
# cat /home/grep/grep1/1.txt
Google
google
Foogle
foogle
[root@justin ~]
# grep '[^a-fA-F]oo' /home/grep/grep1/1.txt
Google
google
[root@justin ~]
#
|
符号“^”表示以什么字符开头,“^word”表示以“word”开头,如果word前面有空格时需要使用[:space:]来匹配前面的空格[root@Zabbix_server home]# grep '^[[:space:]]*root' punct.txt
符号“$”表示以什么字符结尾,“word$”表示以“word”结尾。如果word后面有符号匹配时候需要使用[:punct:]来匹配后的符号[root@Zabbix_server home]# grep 'root[[:punct:]]*$' punct.txt 表示匹配punct.txt文件中以root单词结尾后面接任意多个符号的行
匹配行尾为小数点(.)因为小数点具有其他意义(底下会介绍),所以必须要使用转义字符(\)来加以解除其特殊意义,转义为一个普通字符!
|
1
2
3
4
5
6
7
8
9
10
|
[root@justin ~]
# grep '.$' /home/grep/grep1/a.txt
grep
grap
grbp
grabp
grcbp
grcbp.
[root@justin ~]
# grep '\.' /home/grep/grep1/a.txt
grcbp.
[root@justin ~]
#
|
小数点”.“表示任意一个非换行符的字符,'gr.p'匹配gr后接一个任意字符,然后是p
|
1
2
3
4
5
6
7
8
9
10
|
[root@justin ~]
# echo "grep" > /home/grep/grep1/a.txt
[root@justin ~]
# echo "grap" >> /home/grep/grep1/a.txt
[root@justin ~]
# echo "grbp" >> /home/grep/grep1/a.txt
[root@justin ~]
# echo "grabp" >> /home/grep/grep1/a.txt
[root@justin ~]
# echo "grcbp" >> /home/grep/grep1/a.txt
[root@justin ~]
# grep 'gr.p' /home/grep/grep1/a.txt
grep
grap
grbp
[root@justin ~]
#
|
星号“*”:基本正则表达式中表示匹配其前的字符出现0次或任意次数,例如ab*c,那么ac、abc、acc都会匹配,而abdc就不匹配,星号在基本正则表达式里只指次数,*不会匹配隐藏文件。只表示次数,不表示任意字符
扩展正则表达式中多以下元字符:
+ 匹配一个或多个前面的字符.它的作用和*很相似,但唯一的区别是它不匹配零个字 符的情况,如果要指定范围使用{n,m}来指定,如查找一位或2位数值的行:
|
1
2
3
|
[root@Zabbix_server ~]
# egrep --color=auto '\<[0-9]{1,3}[[:space:]]' /proc/meminfo
[root@Zabbix_server ~]
# egrep --color=auto '\<[0-9]{3}[[:space:]]' /proc/meminfo
[root@Zabbix_server ~]
# egrep --color=auto '\<[0-9]+[[:space:]]' /proc/meminfo
|
| 表示或关系
例如egrep 'abc|def' /proc/meminfo 查找abc或者def
分组
例如 egrep 'abc|def' /proc/meminfo 查找abc或者def
egrep 'ab(c|d)ef' /proc/meminfo 查找abcef或者abdef
|
1
2
3
4
5
6
7
8
9
|
[root@Zabbix_server home]
# egrep 'abc|def' 12.txt --color=auto
abc
abcdef
abcef
abdef
[root@Zabbix_server home]
# egrep 'ab(c|d)ef' 12.txt --color=auto
abcef
abdef
[root@Zabbix_server home]
#
|
问号“?”:基本正则表达式中表示匹配其前的字符出现0次或1次数。只做次数匹配,不做字符匹配
|
1
2
3
4
5
6
7
8
9
|
[root@justin ~]
# echo "google" > /home/grep/grep1/a.txt
[root@justin ~]
# echo "goooooooooooooogle" >> /home/grep/grep1/a.txt
[root@justin ~]
# grep 'g..gle' /home/grep/grep1/a.txt
google
[root@justin ~]
# grep 'g*gle' /home/grep/grep1/a.txt
google
goooooooooooooogle
[root@justin ~]
# grep 'g.gle' /home/grep/grep1/a.txt
[root@justin ~]
#
|
如果想查找两个字符之间任意个字符的条件,可以通过小数点和星号一起来匹配,如查找前尾分别为gr和g的行
|
1
|
[root@justin ~]
# grep 'gr.*g' /home/grep/grep1/a.txt
|
字符范围\{m,n \}:限制前一个字符重复出现最少m次,最多n次数
因为 { 与 } 的符号在 shell 是有特殊意义的,因此必须要使用字符 \ 来让他失去特殊意义
\{m,\} 表示至少m次,
\{0,n\} 表示最多n次,不能使用\{,n\}
\{m\} 表示只出现m次
() 将候选的所有元素放在()内,用|隔开
"a(1|2|3)bc"满足的例子a1bc、mba3bcd
如果要以组的形式匹配,例如xaby 要匹配ab组合出现多次可以使用\(\)来匹配,例如x\(ab\)*y,表示xy中间中ab出现0次或n次
前向引用
|
1
2
3
4
5
6
|
[root@Zabbix_server home]
# cat 1.txt
He love his lover.
She like her liker.
He love his liker.
She like her lover.
[root@Zabbix_server home]
#
|
例如要匹配love和lover、like和liker同时所在行
|
1
2
3
4
|
[root@Zabbix_server home]
# grep '\(l..e\).*\1r' 1.txt
He love his lover.
She like her liker.
[root@Zabbix_server home]
#
|
这里\1表示匹配第一个左括号内l..e相同的内容,\(l\(..\)e\).*\2r表示匹配\(..\)这个内..相同的内容,以此类推
查找出现两个o的行:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
[root@justin ~]
# cat /home/grep/grep1/a.txt
"Open Source"
is a good mechanism to develop programs.
apple is my favorite food.
Football game is not use feet only.
Oh! The soup taste good.
google is the best tools
for
search ke
goooooogle
yes
!
[root@justin ~]
# grep 'o\{2\}' /home/grep/grep1/a.txt
"Open Source"
is a good mechanism to develop programs.
apple is my favorite food.
Football game is not use feet only.
Oh! The soup taste good.
google is the best tools
for
search ke
goooooogle
yes
!
[root@justin ~]
#
|
查找g后面出现2到5次o,然后紧跟g的行:
|
1
2
3
|
[root@justin ~]
# grep 'go\{2,5\}g' /home/grep/grep1/a.txt
google is the best tools
for
search ke
[root@justin ~]
#
|
查找g后面出现两次以上o后面跟g的行:
|
1
2
3
4
5
6
7
|
[root@justin ~]
# grep 'go\{2,\}g' /home/grep/grep1/a.txt
google is the best tools
for
search ke
goooooogle
yes
!
[root@justin ~]
# grep 'go*g' /home/grep/grep1/a.txt
google is the best tools
for
search ke
goooooogle
yes
!
[root@justin ~]
#
|
正则表达式特殊符号
| 字符类 | 代表意义 |
| [:alnum:] | 代表英文大小写字符及数字,即0-9,A-Z,a-z |
| [:alpha:] | 代表任何英文大小字符,即A-Z,a-z |
| [:lower:] | 代表小写字符,即a-z |
| [:upper:] | 代表大写字符,即A-Z |
| [:digit:] | 代表数字,即0-9 |
| [:xdigit:] | 代表十六进制的数字类型,因此包括0-9,A-F,a-f的数字与字符 |
| [:blank:] | 代表空格键与tab按键 |
| [:graph:] | 除了空格与tab按键之外的其它所有按键 |
| [:space:] | 任何会产生空白的字符,包括空格键,Tab键,CR等 |
| [:cntrl:] | 代表键盘上面的控制按键,既包括CR,LF,Tab,Del等 |
| [:print:] | 代表任意可打印字符 |
| [:punct:] | 代表标点符号,即" ' ? ! ; : # $ |
cat
cat只适合查看内容较短的文件,无法上翻页,只能显示、查看一屏内容
tac同上,只是倒叙显示内容
|
1
2
3
4
5
6
7
8
9
|
[root@justin home]
# cat test
111
222
333
[root@justin home]
# tac test
333
222
111
[root@justin home]
#
|
more
more适合查看长文件,可以上、下翻页,按空格键下翻一页,按Enter下翻一行,按b上翻一页,cat和more可以配合使用
|
1
2
|
[root@justin log]
# more boot.log
[root@justin log]
# cat boot.log |more
|
less
less使用查看长文件,而且可以搜索【关键词】,按N/n查找前后关键字
|
1
2
3
4
5
6
|
[root@justin log]
# less secure
Jan 22 10:58:30 justin sshd[1716]: Server listening on :: port 22.
Jan 22 10:59:12 justin sshd[1901]: Accepted password
for
root from 10.15.72.73 port 60959 ssh2
Jan 22 10:59:13 justin sshd[1901]: pam_unix(sshd:session): session opened
for
user root by (uid=0)
Jan 22 10:59:13 justin sshd[1901]: subsystem request
for
sftp
/port
22
|
head
查看文件头N行数据,默认头10,通过-n指定查看行数;
|
1
2
3
4
|
[root@justin log]
# head -n 2 secure
Nov 13 17:31:16 localhost sshd[1582]: Server listening on 0.0.0.0 port 22.
Nov 13 17:31:16 localhost sshd[1582]: Server listening on :: port 22.
[root@justin log]
#
|
tail
查看文件末尾n行,用法同上;参数-f动态实时
|
1
2
|
[root@justin log]
# tail -n 2 secure -f
[root@justin log]
# tail -fn 2 secure
|