SQL Server 进阶 01 数据库的设计
本篇目录
1. 课程内容回顾及介绍
对于SQL Server基础,我们已经学习了SQL Server的相关概念和基本操作,包括创建库、创建表、添加约束和创建安全账户等。
掌握了对数据的增加(insert)、删除(delete)、修改(update)、查询(select)等SQL语句,主要知识点如下:
- 数据库的产生背景和基础知识
- 在SQL Server中创建库、创建表
- 企业管理器和查询分析器的概念
- 定义完整性约束以及强制完整性约束所需的约束
- 使用T-SQL操作表中的数据
- 用于查询现有数据的T-SQL语句
- SQL Server中各种聚合函数
- 在SQL Server中用于查询多个表的内链接
本系列教程,我们将深入学习SQL Server的高级应用,课程内容如下:
- 如何规范化的设计数据库,如何绘制数据库的E-R模型图,方便项目团队成员的高校沟通
- 如何编写SQL语句,实现建库、建表、加约束和创建安全账户,方便对数据库的平稳移植
- 如何使用SQL Server的T-SQL语言,进行强大的SQL编程,实现多功能的数据管理
- 如何使用子查询,实现复杂的单表或多表间的高级查询
- 如何使用事务、视图和索引,实现银行转账等高效、安全的数据管理
- 如何创建存储过程,在数据库中实现高性能的数据管理
- 如何创建触发器,根据业务规则,实现复杂的数据完整性约束
2.为什么需要规范的数据库设计
您也许会问,在第一阶段,根据业务需求,我们直接建库、建表,插入测试数据,然后再查询数据,为什么现在需要强调先设计再建库、建表呢?
原因非常简单,正如我们修造建筑物一样,如果您是盖一间茅屋或一间简易平房,您会花钱请人设计房屋图纸嘛?毫无疑问,没人请。

但是,如果是房地产开发商开发一个楼盘,修建多栋楼房的居住小区,他会情人设计施工图纸嘛?答案是肯定的。

不但开发商会考虑设计施工图纸,甚至恨专业的购房者也会在看房时要求开发商出示设计图纸。
同样道理,在实际的项目开发中,如果徐彤的数据存储量较大,设计的表也比较多,表和表之间的关系比较复杂,我们就需要过滤规范的数据库设计,然后再进行具体的建库、建表工作。
不管是创建动态网站,还是创建桌面窗口应用程序,数据库设计的重要性都不言而喻。
如果设计不当,查询起来就非常吃力,程序的性能也会受到影响。
无论您是用的是SQL Server还是Oracle数据库,通过进行规范化的数据库设计,都可以使您的程序代码更具有可读性,更容易扩展,从而也会提升项目的应用性能。
2.1 什么是数据库设计
数据库设计就是规范和结构化数据库中的数据对象以及这些数据对象之间关系的过程。
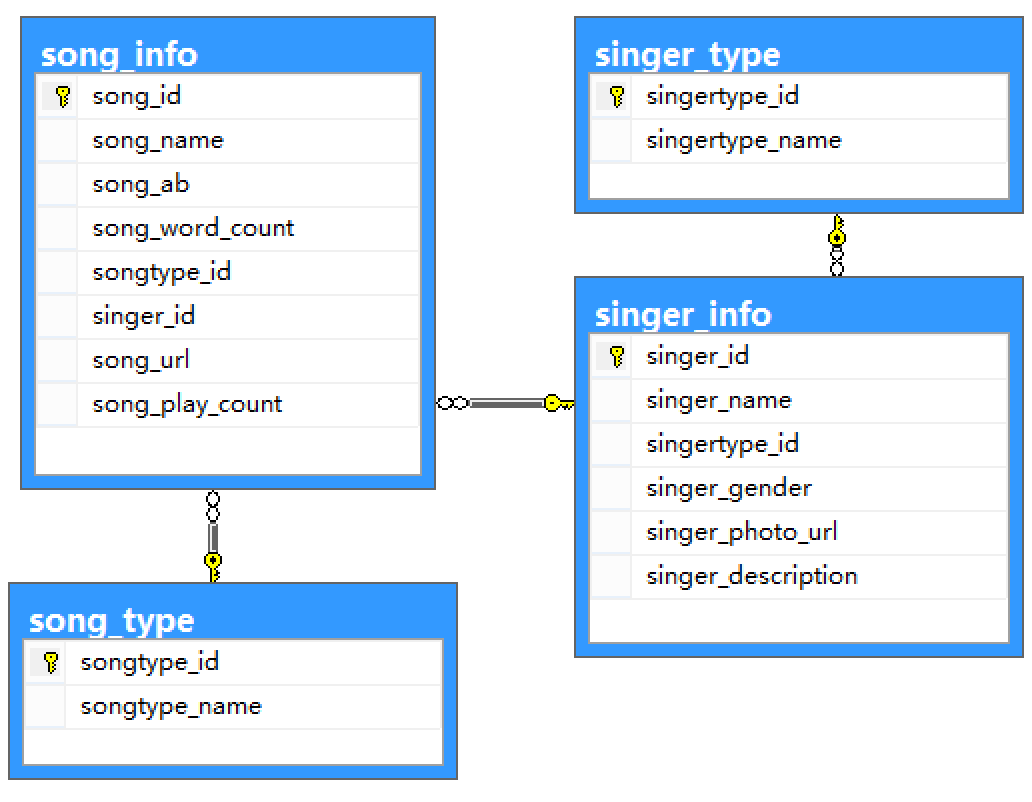
如图是一个KTV数据库的结构,示例该数据库包含歌手、歌手类型、歌曲、歌曲分类的信息,图中还显示了各个对象之间的关系。
2.2 设计数据库非常重要
数据库中创建的数据结构的种类,以及在数据对象之间建立的复杂关系是数据库系统效率的重要决定因素。

糟糕的数据库设计表现为以下几点:
- 效率低下
- 更新和检索数据时会出现许多问题
良好的数据库设计表现为以下几点:
- 效率高
- 便于进一步扩展
- 应用程序开发更容易
3. 设计数据库的步骤
经过了SQL Server基础的学习,我们对项目的开发有了一个整体的感性认识,项目开发需要经过需求分析、概要设计、详细设计、代码编写、运行测试和打包发布几个阶段。
重点讨论在各个阶段,数据库的设计过程:
- 需求分析阶段:分析客户的业务和数据处理需求
- 概要设计阶段:绘制数据库的E-R模型图,用于在项目团队内部、设计人员和客户之间进行沟通,确认需求信息的正确和完整
- 详细设计阶段:将E-R图转换为多张表,进行逻辑设计,确认各表主外键,并应用数据库设计的三大范式进行审核。经项目组开会讨论确定后,还需要根据项目的技术实现、团队开发能力以及项目的经费来源,选择具体的数据库(如SQL Server或Oracle等)进行物理实现,包括建库、建表并创建我们后面学习的存储过程和触发器等。创建完毕后开始代码编写阶段,开发前端应用程序。
现在,我们共同讨论:在需求分析阶段,后台数据库的设计步骤。
- 需求分析阶段的重点是调查、收集并分析客户业务数据需求、处理需求、安全性与完整性需求。
- 常用的需求调查方法有:在客户的公司跟班实习、组织召开调查会、邀请专人介绍、设计调查表并请用户填写、查阅业务相关数据记录等。
- 常用的数据分析方法有:调查客户的公司组织情况、各部门的业务需求情况、协助客户分析系统的各种业务需求、确定新系统的边界。
无论数据库的大小和复杂程度如何,再进行数据库的系统分析时,都可以参考下列几本步骤:
- 收集信息
- 标识对象
- 标识没个对象需要存储的详细信息
- 标识对象之间的关系
3.1. 收集信息
创建数据库之前,必须充分理解数据库需要完成的任务和功能。
简单的说,我们需要了解数据库需要存储哪些信息(数据),实现哪些功能。
以BBS论坛系统为例,我们需要了解BBS论坛的具体功能,与后台数据库的关系:
- 用户注册和登录:后台数据库需要存放用户的注册信息和在线状态信息
- 用户发帖:后台数据库需要存放帖子相关信息,如帖子内容、标题等
- 论坛版块管理:后台数据库需要存放各个板块信息,如版主、板块名称和帖子数量等
3.2 标识对象(实体)
在收集需求信息后,必须标识数据库要管理的关键对象或实体。
我们曾在Java中学习过对象的概念,对象可以是有形的事务,如人或产品。也可以是无形的事务,如商业交易、公司部门或发薪周期。
在系统中标识这些对象以后,与他们相关的对象就会理清楚。
以BBS论坛系统为例,我们需要标识出系统中的主要对象(实体),注意:对象一般是名词,一个对象只描述一件事情,不能重复出现含义相同的对象:
- 论坛用户:包括论坛普通发帖、回帖用户、各板块的版主
- 帖子:用户发的帖子或是回的帖子
- 板块:论坛的各个板块信息
数据库中的每个不同的对象都拥有一个与其相对应的表,也就是说,在我们的数据库中,会对应至少三张表,分别是用户表、帖子表和板块表。
3.3 标识每个对象需要存储的详细信息(属性)
将数据库中的主要对象标识为表的候选对象以后,下一步就是标识每个对象存储的详细信息,也称为该对象的属性,这些属性将组成表中的列。
简单的说,就是需要细分出每个对象包含的子成员信息。
以BBS论坛系统为例,我们逐步分解每个对象的子成员信息,在分解时又发现发帖合回帖不同,所以把帖子细分为发帖合回帖两个对象(实体)。

注意:
分解时,含义相同的成员信息不能重复出现,例如联系方式和电话等,每个对象对应一张表,对象中的每个子成员对应表中的每一列。
例如,从上述的关系就可以看出用户表应该包含列:用户名、密码和电子邮件等
3.4 标识对象(实体)之间的关系
关系型数据库有一项非常强大的功能,它能够关联数据库中各个项目的相关信息。
不同类型的信息可以单独存储,但是如果需要,数据库引擎可以根据需求将数据组合起来。
在设计过程中,要标识对象之间的关系,需要分析这些表,确定这些表在逻辑上是如何相关联的。
以及添加关系列建立起表之间的连接。
以BBS论坛系统为例:
- 发帖合回帖有主从关系,我们需要在回帖对象中生命它是谁的回帖
- 板块管理中的版主合论坛用户有关系,从用户对象中可以根据板块对象查出对应的版主用户的情况
- 板块合发帖有主从关系,需要声明发帖是属于哪个板块的
- 板块也和回帖有主从关系,需要声明回帖是属于哪个板块的
4. 绘制E-R(实体-关系)图
在需求分析阶段解决了客户的业务合数据处理需求后,就进入了我们的概要设计阶段,我们需要合项目团队的其他成员以及我们的客户沟通,讨论数据库的设计是否满足客户的业务合数据处理需求。
和机械行业需要机械制图,建筑行业需要施工图一样,我们的数据库设计也需要图形化的表达方式——E-R(Entity-Relationship)实体关系图,它也包括一些具有特定含义的图形符号。
下面将介绍相关理论和具体的图形符号。
4.1 实体-关系模型
4.1.1 实体
所谓实体就是指现实世界中具有区分其它事物的特征或属性并与其它实体有联系的对象。
例如BBS论坛系统中的用户、帖子、板块等,实体一般是名词,它对应我们表中的一行数据,例如张三用户这个实体,将对应“用户表”中,张三用户所在的一行数据,包括他的密码、出生日期、电子邮件等信息。
严格的说,实体指表中一行一行的特定数据,但我们在开发时,也常常把整个表也称为一个实体。
4.1.2 属性
属性可以理解为实体的特征。
例如:“用户”这个实体的属性有昵称、出生日期和电子邮件等。
属性对应表中的列。
4.1.3 关系
关系是两个货多个实体之间的联系。
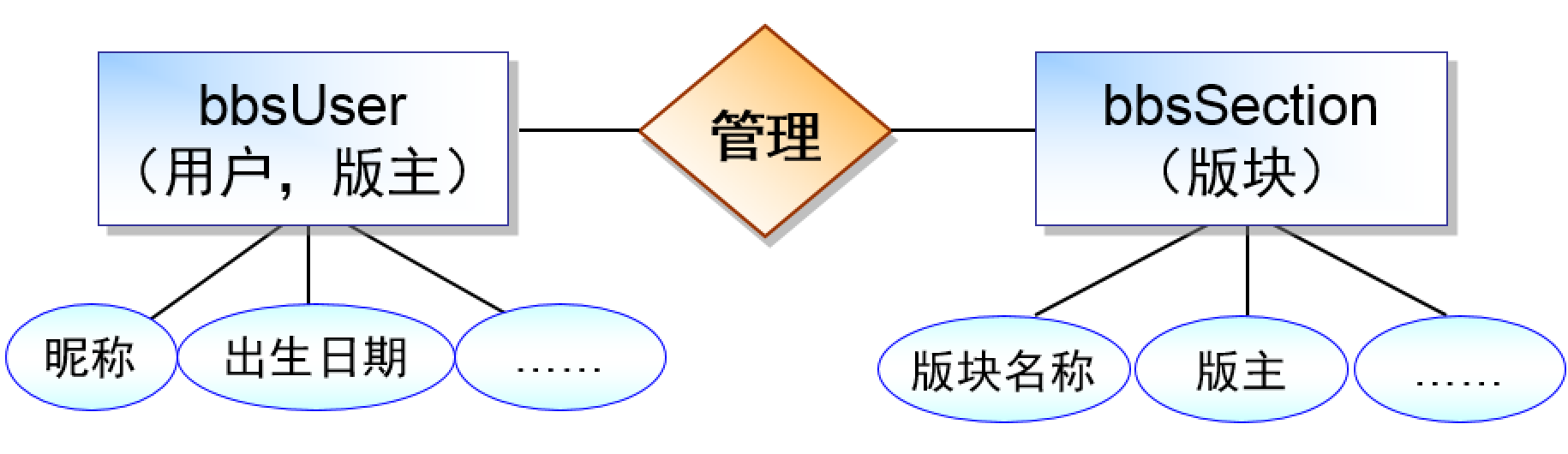
如图是用户实体和板块实体之间的关系,实体使用方块表示,实体一般是名词,属性使用椭圆表示,一般也是名词。
关系使用菱形表示,一般是动词。
4.1.4 映射基数
映射基数表示可以通过关系与该实体关联的其它实体的个数。
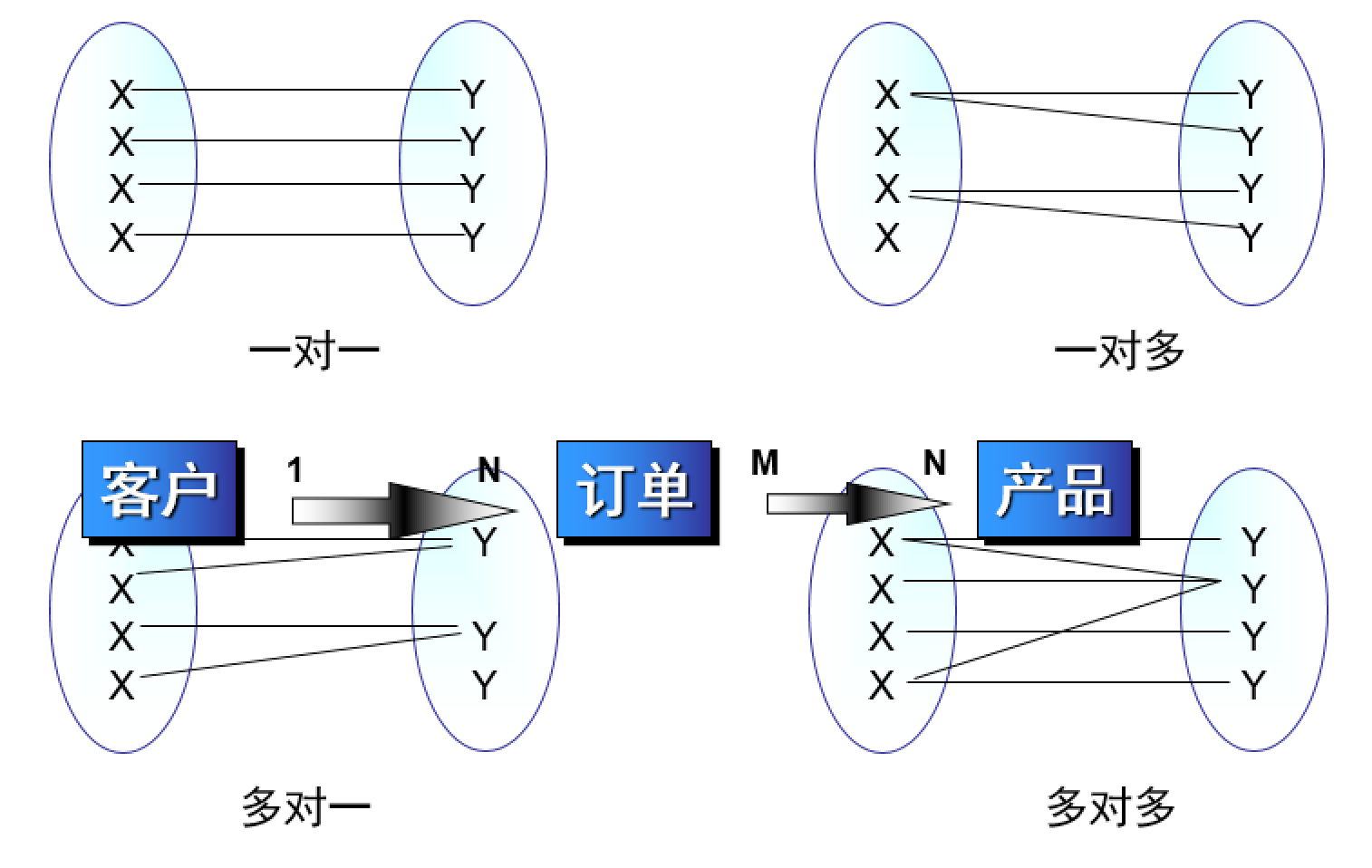
对于实体集X和Y之间的二元关系,映射基数必须为下列基数之一:
- 一对一:X中的一个实体最多与Y中的一个实体关联,并且Y中的一个实体最多与X中的一个实体关联。假定规定一个论坛用户只能担任一个板块的版主,那么,用户实体和板块实体之间就是一对一关系。
- 一对多:X中的一个实体可以与Y中的任意数量的实体关联。Y中的一个实体最多与X中的一个实体关联。一个发帖可以有多个回帖,所以说,发帖实体和回帖实体之间就是典型的一对多关系,一对多关系也常表示为1:N
- 多对一:X中的一个实体最多与Y中的一个实体关联。Y中的一个实体可以与X中的任意数量的实体关联。发帖实体和回帖实体之间就是典型的一对多关系,反过来说,回帖实体和发帖实体之间就是多对一关系了
- 多对多:X中的一个实体可以与Y中的任意数浪的实体关联,反之亦然。假定一个板块允许有多个版主,一个用户也允许担任多个板块的版主,那么板块实体和用户实体之间就是典型的多对多关系了,多对多关系也常用符号表示为M:N
4.1.5 实体关系图
E-R图以徒刑的方式将数据库的这个那个逻辑结构表示出来,E-R图的组成包括:
- 矩形表示实体
- 椭圆表示属性
- 菱形表示关系集
- 直线用来连接属性和实体集,也用来连接实体集和关系集
在本教程中,直线可以是有方向的(在末端有一个箭头),用来表示关系集的映射基数。
如图显示了一些示例,这些示例表示了可以通过关系与一个实体相关联的其它实体的个数,箭头的定位很简单,可以将其视为指向引用的实体。
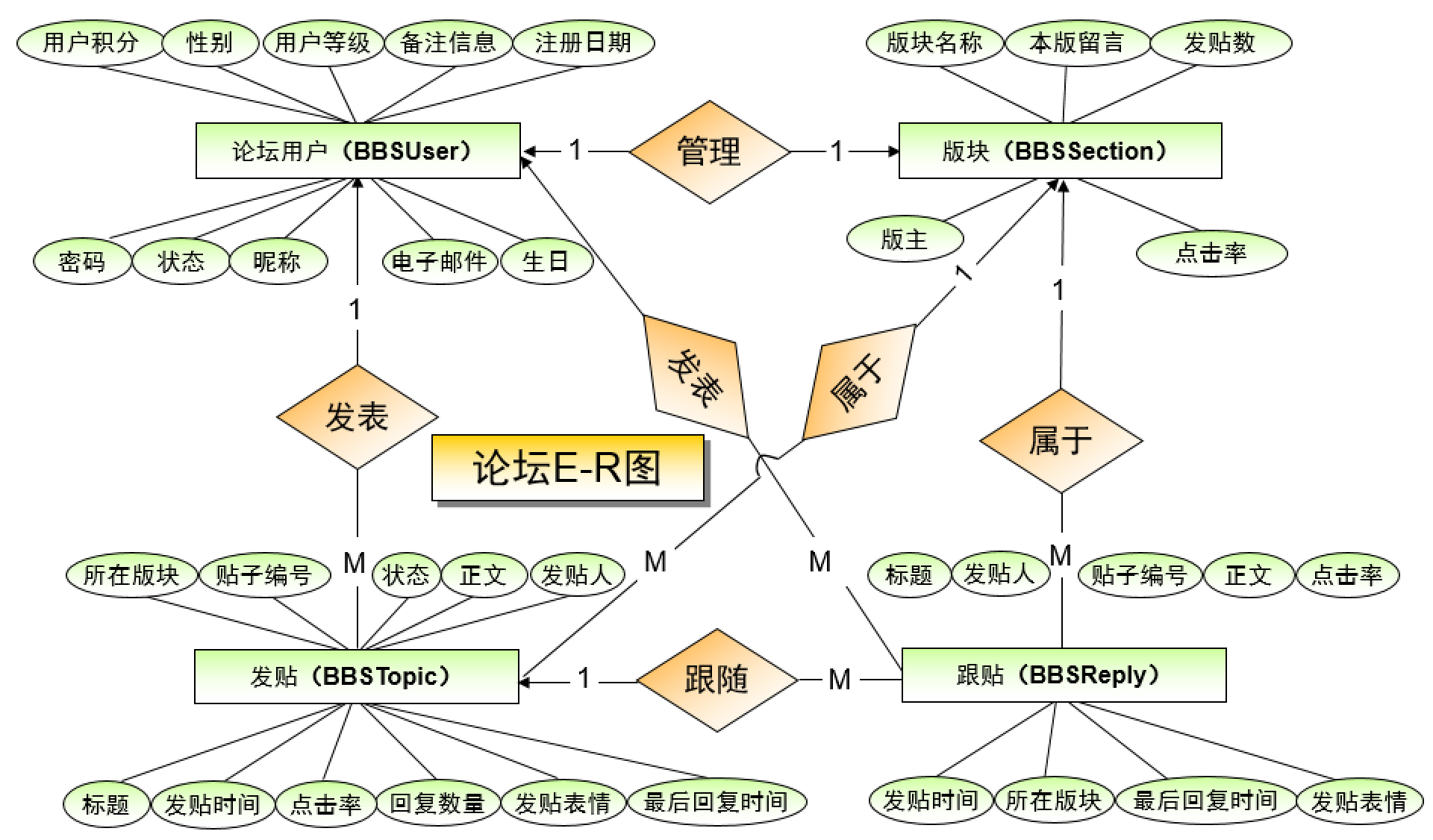
- 1:1——每个论坛用户只能管理一个板块,并且每个板块也只能由一个用户担任
- 1:N——每个论坛用户可以发表多个帖子,但是一个帖子只能对应一个发帖用户
- M:N——上图中没有体现,但是现实中,比如每个邮箱可以注册多个账户等都是多对多关系
绘制E-R图后,我们还需要与客户反复进行沟通,让客户提出修改意见,以确认系统中数据处理需求是否表示的正确和完整。
4.2 如何将E-R图转换为表
该要设计解决了客户的需求捕获,并绘制了E-R图,在后续的详细设计阶段,我们需要把E-R图转换为多张表,并标识各表的主外键。
下面将介绍如何将介绍如何将E-R图转换为表哥,如何审核各表的结构是否规范将在本篇最后进行介绍。
- 第一步,将各实体转化为对应的表,将各属性转换为各表对应的列
- 第二步,标识每个表的主键列,需要注意的是:对没有主见的表添加ID编号列,没有实际含义,只用做主键或外键,例如用户表中的UID列,板块表中添加的SID列,发帖表和回帖表中的TID列。为了数据编码的兼容性,建议实用英文字段。为了直观可见,在英文括号内著名对应的中文含义。
- 第三步,我们还需要在表之间体现实体之间的映射关系
- (1) 板块(BBSSession)表中的版主来自用户(BBSUser)表中的个别用户,所以她们之间建立主外键关系,板块(BBSSession)表中引用的版主,应引用用户表中的用户编号(UID),体现一对一的关系
- (2) 同理,发表帖(BBSTopic)和回帖表(BBSReply)中的发帖人也应和用户表中的用户编号(UID)建立主外键关系,体现一对多的关系
- (3) 回帖表(BBSReply)中的“回复的主帖”对应主贴表(BBSTopic)的“标识主键”列(TID),建立主外键关系
- (4) 回帖表(BBSReply)和主帖表(BBSTopic)中的“所在板块”列也应该与板块表(BBSSession)中板块编号(SID)建立主外键关系。
根据上述E-R图转换的表如图:
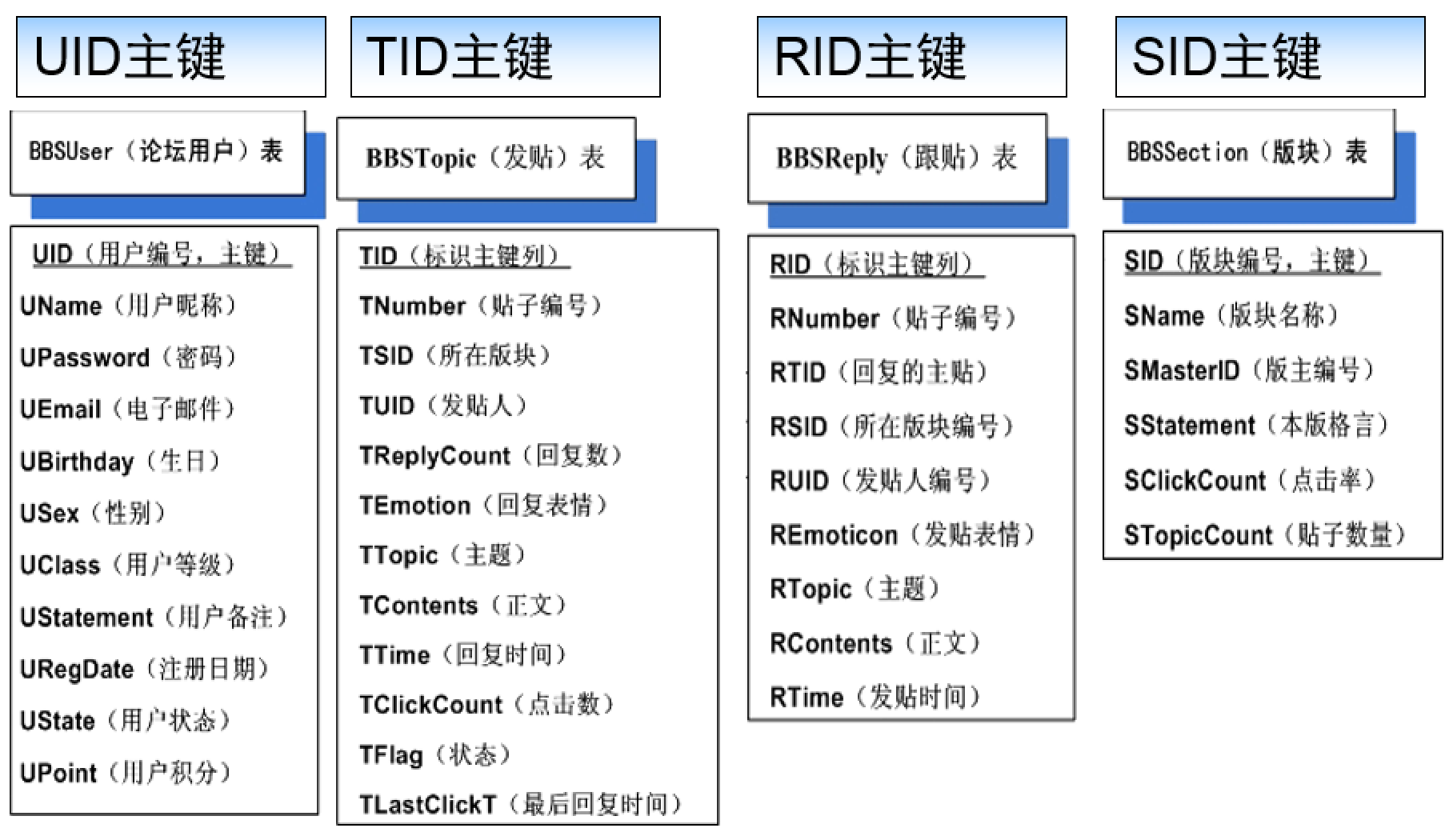
标识各表键的关系后如图:

5. 数据规范化
5.1 设计问题
有人开玩笑说,在该要设计阶段,同一个项目,10个设计人员将设计出10种不同的E-R图。
不错,不同的人从不同的角度,标识出不同的实体,实体又饱含不同的属性,自然就设计出不同的E-R图。
那么怎样审核这些设计图呢?怎么评审出最优秀的设计方案呢?
所以,我们的下一步工作就是规范化E-R图了。
为了讨论方便,下面直接以账户表(Account)为例,该表存储有关银行客户账户的信息和交易细节:
| 帐号 | 客户姓名 | 地址 | 开户日期 | 账户类型 | 交易号 | 交易金额 | 交易日期 |
| 85001 | Smith | 1,Main | 1/4/03 | Savings | 1 | 1000 | 2/4/03 |
| 85002 | James | 2,Main | 3/4/03 | Current | 2 | 200 | 4/4/03 |
| 85003 | Ritcha | 3,Main | 4/4/03 | Savings | 3 | 100 | 5/4/04 |
| 86003 | Ritcha | 3,Main | 4/4/03 | Savings | 4 | 400 | 6/4/03 |
从用户的角度而言,将所有信息放在一个表中很方便,因为这样查询数据库可能会比较容易,但是上述表具有下列问题:
- 信息重复
有很多信息是重复的,“客户姓名”和“账户类型”列种有许多重复信息,例如“Savings”,信息重复会造成存储空间的浪费以及一些其它问题,如果不小心输入“Saving”和“Savings”,在数据库中将会表示不同的账户类型。 - 更新异常
冗余信息不仅浪费存储空间,而且会增加更新的难度。如果需要修改表示将储蓄帐户指定为“Savings Account”而不是“Savings”的测试,则需要修改所有饱含该值的行,则数据库中酒会又两种类型的储蓄帐户,一个是“Savings”,另一个是“Savings Account”,这种情况被称为更新异常。 - 插入异常(无法表示某些信息)
上述表中,帐号或交易号单独不能作为主键,我们需要采用组合键作为主键,假设上表的主键为(帐号,交易号),任何要插入到该关系中的新行必须提供主键的值,因为鲜有的完整性要求主键不能完全或部分为空。如果某个帐号希望开户,即向该表中插入一行数据,如果帐号刚开户,还没有交易记录,您将无法插入开户信息的数据。这种问题被称为插入异常。 - 删除异常(丢失有用的信息)
在某些情况下,当删除一行时,可能会丢失有用的信息。例如,如果删除帐号为85002的行,就会丢失账户类型为“Current”的账户信息,该表只剩下唯一的一种账户类型“Savings”了,当希望查询有哪些账户类型时,将会误以为只有“Savings”账户类型。这种情况被称为删除异常。
5.2 规范设计
如何重新规范设计上述表呢?如何避免上述诸多异常呢?
在数据库的设计时,有一些专门的规则,成为数据库的设计范式,遵守这些规则,您将创建设计良好的数据库,下面将注意讲解数据库设计中著名的三大范式理论。
1. 第一范式(1NF,Normal Formate)
第一范式的目标时确保每列的原子性:如果每列(或者每个属性值)都是不可再分的最小数据单元(也称为最小的原子但愿),则满足第一范式(1NF)。
例如:
顾客表(顾客编号、地址、...),其中地址列还可以细分为国家、省、市、区等,更多的程序甚至把姓名也拆分为姓和名等。
2. 第二范式(2NF)
第二范式在第一范式的基础上,更进一层,其目标是确保表中的每列都和主键相关,如果一个关系满足1NF,并且出了主键以外的其它列,都依赖于该主键,则满足第二范式(2NF)。
例如:
订单表(订单编号、产品编号、订购日期、价格、...)
该表主要用来描述订单,所以订单编号设为主键,“订购日期”、“价格”两列都和“订单编号”主键相关,但“产品编号”列和“订单编号”列没有直接关系,即“产品编号”列不依赖于“订单编号”主键列,该列应从该表中删除,放入产品表中。
这样,该表就只描述一件事情:订单信息。
3. 第三范式(3NF)
第三范式在第二范式的基础上,更进一层,第三范式的目标是确保每列都和主键列直接相关,而不是间接相关:如果一个关系满足2NF,并且出了主键以外的其它列都不依赖于主键列,则满足第三范式(3NF)。
为了理解第三范式,需要根据Armstrong公理之一定义传递依赖:假设A、B和C是关系R的3个属性,如果A->B且B->C,则从这些函数依赖(FD)中,可以得出A->C,如上所述,依赖A->C是传递依赖。
例如:
订单表(订单编号、订购日期、顾客编号、顾客姓名、...)
初看该表没有问题,满足2NF,每列都和主键列“订单编号”相关,再细看您会发现“顾客姓名”列和“顾客编号”相关,“顾客编号”列和“订单编号”又相关,最后经过传递依赖,“顾客姓名”也和“订单编号”相关。
为了满足3NF我们应该去掉“顾客姓名”列,将此列放入客户表中。
了解了用于规范化数据库设计的三大范式之后,咱们回头看一下上面那个Account帐号表。
1.是否满足第一范式
第一范式要求每列必须是最小的原子单元,即不能再细分。
前面我们提及过,地址需要氛围省、市、区等,方便查询。但我们没有这方面的查询需求,所以本例中没必要拆分“地址”列。
所以,该表满足第一范式。
2.是否满足第二范式
第二范式要求每列必须和主键相关,不想管的列放入别的表中,即要求一个表只描述一件事情。
实用的技巧是,我们可以直接查看该表描述了哪几件事情,然后一件事情创建一张表。经过分析,该表描述了三件事情:
1) 账号信息
2) 交易信息
3) 账户类型信息
即我们需要创建三张表,对各列进行筛选,拆分后结果表如下:
| 类型编号 | 账户类型 |
| 1 | Savings |
| 2 | Current |
| 交易号 | 交易金额 | 交易日期 | 帐号 |
| 1 | 1000 | 2/4/03 | 85001 |
| 2 | 200 | 4/4/03 | 85002 |
| 3 | 100 | 5/4/03 | 85003 |
| 4 | 400 | 6/4/03 | 86003 |
| 帐号 | 客户信息 | 地址 | 开户日期 | 账户类型 |
| 85001 | Smith | 1,Main | 1/4/03 | 1 |
| 85002 | James | 2,Main | 3/4/03 | 2 |
| 85003 | Ritcha | 3,Main | 4/4/03 | 1 |
| 86003 | Ritcha | 4,Main | 4/4/03 | 1 |
3.是否满足第三范式
第三范式要求该表中各列必须和主键直接相关,不能间接相关,浏览每个表,已经满足了。
5.3 规范化和性能的关系
需要提醒的是,对于项目的最终用户来说,客户最关系的是方便、清晰的数据结果。
您如果让客户选择,毫无疑问,客户会认为最初的表设计最适合需求,虽然他根本就不满足三大方式,并且存在大量的数据冗余。
所以说,我们在设计数据库时,设计人员和客户对数据库的设计有一定的矛盾。
通过三大范式分解的三张表,为了满足客户的需求,最终我们需要通过三张表之间的连接查询,恢复为客户需要的数据结果。
插入数据同样如此,对客户输入的数据,我们需要分开插入在三张不同的表中。
由此可以看出,为了满足三大范式,我们的苏剧操作性可能会收到相应的影响。
所以,在时机的数据库设计中,既要考虑三大范式,避免数据的冗余和各种数据操作异常,还要考虑数据访问性能。
有时,为了减少表间链接,提高数据库的访问性能,适当允许少量数据的冗余列,才是最合适的数据库设计方案。
6. 总结
在需求分析阶段,设计数据库的一般步骤如下:
- 收集信息
- 标识对象
- 标识每个对象的属性
- 标识对象之间的关系
在概要设计阶段和相惜设计阶段,设计数据库的一般步骤为如下:
- 绘制E-R图
- 将E-R图转换为表格
- 应用三大范式规范化表哥
从关系型数据库中除去冗余数据的过程称为规范化。如果使用得当,规范化是用于获得高效关系型数据库中表的逻辑结构的最好和最容易的方法。
规范化数据时,执行下列操作:
- 将数据库的结构精简为最简单的形式
- 从表中删除冗余的列
- 标识所有依赖于其他数据的数据
【来自:张董'Blogs:http://www.cnblogs.com/LonelyShadow,转载请注明出处。】
亲们。码字不容易,觉得不错的话记得点赞哦。。





