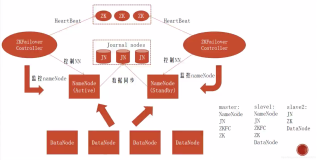
本篇文章开始实际的集群搭建操作。
最开始,是集群规划,对集群的大概样子要心中有数
然后,配置drbd和pacemaker
其次,hadoop的配置,主要是指跟集群有关的配置
最后才是集群资源的配置
一、规划:
我们的Namenode双机热备,需要哪些资源?
首先,一般双节点主备方案所通用的资源:
一个虚拟IP:
一个drbd:
一个文件系统:drbd主备节点切换时,卸载或加载相应的分区
一个主从集群资源:这个资源是从drbd延伸过来的,因为drbd是两个节点上同时运行,所以要区分主从,这个资源用ms命令创建,而不是primitive
然后是特定集群中的资源,对于hadoop的namenode集群而言,资源如下:
一个hdfs服务:启动namenode的hdfs的服务
一个jobtracker服务:启动namenode的jobtracker服务
这两个资源最好编组,比如,把这两个资源编组为hadoop,否则在写约束时比较繁杂。
关于组资源:在很多案例中,人们使用group命令把虚拟IP和其它运行于DRBD主节点之上的服务(如文件系统、apache或mysql等)进行编组,这样可以简化约束条件配置。
资源编组有一些特点:
1、一般是两个以上的资源进行编组(两个也可以),编组的资源有一个额外的属性,即允许组中资源并行地启用;
2、组中的所有资源默认在同一个物理节点上运行;
3、组中的资源以显示顺序启动,以相反顺序停止;
4、如果组中的某资源在某节点上无法运行,则该资源其后的其它资源也不允许运行
5、在配置约束时,组中的资源通常使用组ID进行统一配置
需要哪些约束?
1、组资源hadoop要和虚拟IP绑定在一起,colocation约束
2、文件系统要和drbd的主节点绑定在一起,同样是colocation约束
3、组资源hadoop要和文件系统绑定在一起,也是colocation约束
4、虚拟IP先于组资源hadoop启动,是order约束
5、drbd提升主节点以后,再启动文件系统,又一个order约束
6、文件系统挂载以后,再启动hadoop,还是order约束
7、最后,两个额外的属性:property no-quorum-policy=ignore和stonith-enabled=false,这两个属性在双节点主备集群中的必要性,官方文档有说明。
总结资源配置顺序如下:
VIP--hadoop--两个资源的约束
--drbd--文件系统--两个资源的约束 (cib模式)
--hadoop--文件系统--这两个资源的约束
注意:drbd及文件系统配置时,要使用cib模式,否则会报错,我也是折腾了很久也明白过来的!
二、pacemaker的配置:
pacemaker的安装与配置,参考本博客pacemaker相关的文章。
配置文件:略。
三、drbd的配置:
drbd的安装与配置,已经有相关的文章。这里直接贴配置文件:
resource配置文件:略。
global-common配置文件:
-
......略
-
......
-
common {
-
protocol C;
-
-
handlers {
-
-
pri-on-incon-degr "/usr/lib/drbd/notify-pri-on-incon-degr.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
-
-
pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
-
-
local-io-error "/usr/lib/drbd/notify-io-error.sh; /usr/lib/drbd/notify-emergency-shutdown.sh; echo o > /proc/sysrq-trigger ; halt -f";
-
-
fence-peer "/usr/lib/drbd/crm-fence-peer.sh";
-
-
split-brain "/usr/lib/drbd/notify-split-brain.sh root";
-
-
after-resync-target "/usr/lib/drbd/crm-unfence-peer.sh";
-
-
}
-
-
startup {
-
-
# wfc-timeout degr-wfc-timeout outdated-wfc-timeout wait-after-sb
-
-
}
-
-
disk {
-
on-io-error detach;
-
fencing resource-only;
-
-
}
-
......略
-
......
-
syncer {
-
rate 10M;
-
al-extents 512;
-
csums-alg sha1;
-
-
}
上述配置文件只贴出了handler、disk等部分配置段,有几点要说一下:
1、配置文件删除了startup部分的配置。在配置HA时遇到了错误,在解决错误的过程中删掉了该配置,后来问题解决,也没有补上;个人觉得,HA中drbd由pacemaker来控制,pacemaker中也有相关的启动参数,似乎不必配置drbd本身的启动参数了。纯属个人意见。
2、有两个地方还需要调优:一是handler部分的split-brain,目前把邮件发送到root@localhost,以后要搭建postfix,发邮件到我的工作邮箱;还有一个是syncer部分的rate,目前是10M,以后还要调优,这个需要测试xfs的读写速度(主要是写速度)以后才能定下来。
四、hadoop的配置:
有几个配置文件要修改:
1、$HADOOP_HOME/conf/core-site.xml,修改两个参数:fs.default.name和hadoop.tmp.dir,
把fs.default.name的地址修改为虚拟IP对应的虚拟主机名,把hadoop.tmp.dir的目录位置修改为drbd分区:
-
<property>
-
<name>fs.default.name</name>
-
<value>hdfs://DRBD:9000</value>
-
</property>
-
-
<property>
-
<name>hadoop.tmp.dir</name>
-
<value>/data/temp</value>
-
</property>
说明,DRBD是我的虚拟主机名。其实这时候还没配置虚拟IP及虚拟主机名,但已经规划好了,所以这里直接填了。
2、$HADOOP_HOME/conf/hdfs-site.xml,修改dfs.name.dir,把目录位置修改为drbd分区:
-
<property>
-
<name>dfs.name.dir</name>
-
<value>/data/nn</value>
-
</property>
说明,/data目录是我的drbd分区所挂载的目录。
3、$HADOOP_HOME/conf/mapred-site.xml,修改两个参数:mapred.job.tracker,以及mapred.job.tracker.http.address,把它们的地址修改为虚拟IP:
-
<property>
-
<name>mapred.job.tracker</name>
-
<value>DRBD:9001</value>
-
</property>
-
-
<property>
-
<name>mapred.job.tracker.http.address</name>
-
<value>DRBD:50030</value>
-
</property>
4、$HBASE_HOME/conf/hbase-site.xml文件,修改hbase.rootdir:
-
<property>
-
<name>base.rootdir</name>
-
<value>hdfs://DRBD:9000/hbase</value>
-
</property>
五、开始配置集群资源:
首先,查看一下当前的集群配置:

配置资源与约束之前的准备工作:
1、要注意主备节点之间的时钟同步!
2、关闭drbd自启动,而使用pacemaker管理资源:
-
chkconfig --level 2345 drbd off
3、由于官方没有提供namenode的资源代理,所以我们首先要创建RA,而在创建RA之前,我们还要hdfs和jobtracker的启动/停止脚本。
a、创建hdfs脚本:
该脚本用于启动/停止namenode节点的hdfs服务。
最简单的办法,修改start-dfs.sh及stop-dfs.sh脚本,删除最后两行,重新命名为start-namenode.sh,和stop-namenode.sh。
b、创建jobtracker脚本:
该脚本用于启动/停止namenode节点的jobtracker服务。
最简单的办法,修改start-mapred.sh及stop-mapred.sh脚本,删除最后一行,重新命名为start-jobtracker.sh,和stop-jobtracker.sh。
创建hdfs的资源代理:
OCF标准我不太懂,所以写了一个LSB标准的。两种RA的写法,参考:http://www.linux-ha.org/wiki/OCF_Resource_Agent,和http://refspecs.linux-foundation.org/LSB_3.2.0/LSB-Core-generic/LSB-Core-generic/iniscrptact.html
在/etc/init.d目录下,创建脚本dfs:
-
#!/bin/bash
-
#This is a Resource Agent for managing hadoop namenode
-
#2011-08-30 by qinshan.li
-
#
-
HADOOP_HOME=/home/hdfs/hadoop-0.20.2-CDH3B4
-
DFS_USER=hdfs
-
DFS_START=$HADOOP_HOME/bin/start-namenode.sh
-
DFS_STOP=$HADOOP_HOME/bin/stop-namenode.sh
-
-
start() {
-
echo -n "Starting dfs: "
-
su - $DFS_USER -c $DFS_START
-
sleep 10
-
if netstat -an |grep 50070 >/dev/null
-
then
-
echo "dfs is running"
-
return 0
-
else
-
return 3
-
fi
-
}
-
-
stop() {
-
if netstat -an |grep 50070 |grep LISTEN >/dev/null
-
then
-
echo "Shutting down dfs"
-
su - $DFS_USER -c $DFS_STOP
-
else
-
echo "dfs is not running"
-
return 3
-
fi
-
if netstat -an |grep 50070 |grep LISTEN >/dev/null
-
then
-
sleep 10
-
kill -9 $(cat $HADOOP_HOME/pids/hadoop-hdfs-namenode.pid)
-
fi
-
}
-
-
restart() {
-
if netstat -an |grep 50070 |grep LISTEN >/dev/null
-
then
-
stop
-
sleep 10
-
start
-
else
-
start
-
return 0
-
fi
-
}
-
-
status() {
-
if netstat -an |grep 50070 |grep LISTEN >/dev/null
-
then
-
echo "dfs is running"
-
return 0
-
else
-
echo "dfs is stopped"
-
return 3
-
fi
-
}
-
-
case "$1" in
-
start)
-
start
-
;;
-
stop)
-
stop
-
;;
-
restart|force-reload)
-
restart
-
;;
-
status)
-
status
-
;;
-
*)
-
-
echo "Usage: /etc/init.d/dfs {start|stop|restart|status}"
-
exit 1
-
;;
-
esac
-
exit 0
仿照上述脚本,创建jobtracker的资源代理:
在/etc/init.d目录下,创建mapred脚本:
脚本略
开始配置资源与约束:
提示:创建资源前,最后先使用meta命令查看一下该资源代理的常用选项!特别地,当你从网上照搬某些配置时,有时候系统会提示没有某配置项,或时间设定太短,这时候更需要meta命令了!
添加集群资源:
#配置no-quorum-policy和stonith-enabled
已配置,略过。命令如下:
-
crm(live)configure# property no-quorum-polic=ignore
-
crm(live)configure# property stonith-enabled=false
#创建虚拟IP资源
-
crm(live)configure# primitive VIP ocf:heartbeat:IPaddr2 \ #斜杠前有空格
-
> params ip=10.10.0.200 cidr_netmask=32 \ #根据实际情况进行配置!
-
> op monitor interval=20s timeout=30s
-
crm(live)configure# commit
#把虚拟IP添加到host表,整个hadoop集群的节点都要添加,而不仅仅是两个namenode节点:
-
vim /etc/hosts,添加:
-
10.10.0.200 DRBD
#创建hdfs资源
-
crm(live)configure# primitive namenode lsb:dfs \
-
> op monitor interval=20 timeout=20 start-delay=20
-
crm(live)configure# commit
#创建jobtracker资源
-
crm(live)configure# primitive jobtracker lsb:mapred
-
crm(live)configure# commit
#创建组资源hadoop,把namenode和jobtracker资源进行编组
-
crm(live)configure# group HADOOP namenode jobtracker
-
crm(live)configure# commit
#配置资源VIP和组资源hadoop的两个约束
-
crm(live)configure# colocation HADOOP-with-VIP inf: HADOOP VIP
-
crm(live)configure# order HADOOP-after-VIP inf: VIP HADOOP
-
crm(live)configure# commit
#设置集群内的资源粘性,防止资源在节点间频繁迁移
-
crm(live)configure# rsc_defaults resource-stickiness=100
-
crm(live)configure# commit
#修改集群默认的时间间隔,我觉得20s太短了,改为60s
-
crm(live)configure# property default-action-timeout=60
-
crm(live)configure# commit
#创建drbd资源,及其状态克隆资源
#参考:http://www.clusterlabs.org/wiki/DRBD_HowTo_1.0。注意,官方推荐使用ocf:linbit:drbd来配置drbd!
#注意:drbd资源,及文件系统资源,使用cib模式进行配置
-
crm(live)# cib new drbd
-
INFO: drbd shadow CIB created
-
-
crm(drbd)# configure primitive drbd0 ocf:linbit:drbd \
-
> params drbd_resource=namenode \
-
> op start timeout=250 \
-
> op stop timeout=110 \
-
> op promote timeout=100 \
-
> op demote timeout=100 \
-
> op notify timeout=100 \
-
> op monitor role=Master interval=20 timeout=30 \
-
> op monitor role=Slave interval=30 timeout=30
-
-
crm(drbd)# configure ms ms-drbd0 drbd0 \
-
> meta master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true
-
-
crm(drbd)# cib commit drbd
-
INFO: commited 'drbd' shadow CIB to the cluster
#创建文件系统资源,并配置文件系统与drbd资源的两个约束
-
crm(live)# cib new fs
-
INFO: fs shadow CIB created
-
-
crm(fs)# configure primitive fs-drbd0 ocf:heartbeat:Filesystem \
-
> params device=/dev/drbd0 directory=/data fstype=xfs
-
crm(fs)# configure colocation fs-on-drbd0 inf: fs-drbd0 ms-drbd0:Master
-
crm(fs)# configure order fs-after-drbd0 inf: ms-drbd0:promote fs-drbd0:start
-
-
crm(fs)# cib commit fs
-
INFO: commited 'fs' shadow CIB to the cluster
#配置组资源hadoop与文件系统的两个约束
-
crm(live)configure# colocation HADOOP-on-fs inf: HADOOP fs-drbd0
-
crm(live)configure# order HADOOP-after-fs inf: fs-drbd0 HADOOP
-
crm(live)configure# commit
查看集群配置:
crm configure show
图就不贴了!:-)
查看集群状态:

测试迁移:
在SER-126上,执行crm node standby,停止其运行的所有服务,观察Namenode能否自动切换到SER-125上:

迁移成功!
搭建工作到此就完成了,可以在namenode上跑一些任务测试一下。
本文转自 li_qinshan 51CTO博客,原文链接:http://blog.51cto.com/share/655862