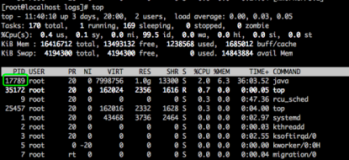
top - 16:09:36 up 159 days, 3:51, 4 users, load average: 29.00, 29.07, 29.17
Tasks: 417 total, 1 running, 415 sleeping, 1 stopped, 128 zombie
Cpu(s): 0.0%us, 0.1%sy, 0.0%ni, 99.9%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 16087M total, 14465M used, 1622M free, 113M buffers
Swap: 164M total, 8M used, 156M free, 13965M cached
今日登陆服务器。top一看,128个僵尸进程,用了下面的命令处理,记录如下
ps -ef |grep '<defunct>'
root 682 678 0 Jan24 ? 00:00:00 [sh] <defunct>
root 780 775 0 2011 ? 00:00:00 [sh] <defunct>
root 951 948 0 Jan24 ? 00:00:00 [sh] <defunct>
root 1420 1364 0 2011 ? 00:00:00 [sh] <defunct>
root 2109 2063 0 Jan24 ? 00:00:00 [sh] <defunct>
ps -ef |grep '<defunct>'|wc -l
128
`ps -ef | grep '<defunct>'|grep -v grep |awk '{print $2,$3}'|sed "s/^/kill -9 /g"`
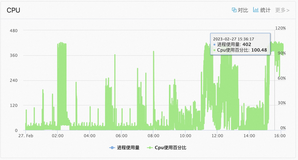
同时发现系统负载是如此之高,查看mysql,发现凌晨的备份到现在还未执行完毕,杀掉备份进程,系统负载变为以下
top - 16:29:57 up 159 days, 4:12, 5 users, load average: 1.14, 4.52, 15.14
Tasks: 305 total, 1 running, 303 sleeping, 1 stopped, 0 zombie
Cpu(s): 0.0%us, 0.0%sy, 0.0%ni, 99.9%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 16087M total, 14444M used, 1643M free, 113M buffers
Swap: 164M total, 8M used, 156M free, 13965M cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
6648 root 20 0 2472 1148 768 R 1 0.0 0:00.45 top
1 root 20 0 1940 644 596 S 0 0.0 1:29.46 init
2 root 15 -5 0 0 0 S 0 0.0 0:01.54 kthreadd
此故障是由于脚本程序执行故障引起的
本文转自it你好 51CTO博客,原文链接:http://blog.51cto.com/itnihao/830368,如需转载请自行联系原作者