热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
使用JWT的服务分布式部署之后报错:JWT Check Failure:
【docker】部署的redis突然连接不上了
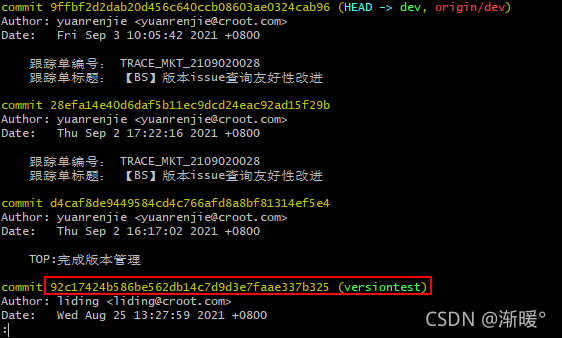
【git】如何切换到之前的提交版本
【Java】实体字段传参类型线上问题记录
效率工具RunFlow完全手册之开发者篇
微服务之Springboot整合Oauth2.0 + JWT
docker部署xxl_job
项目架构设计
项目基础服务部署
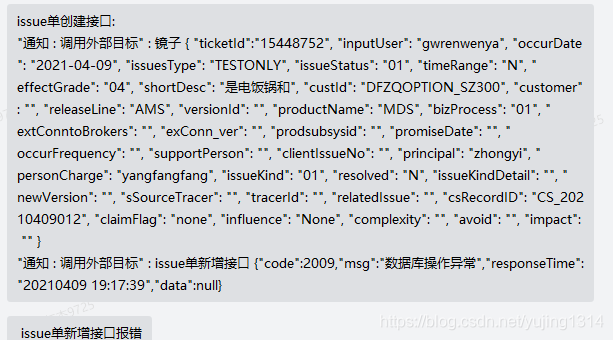
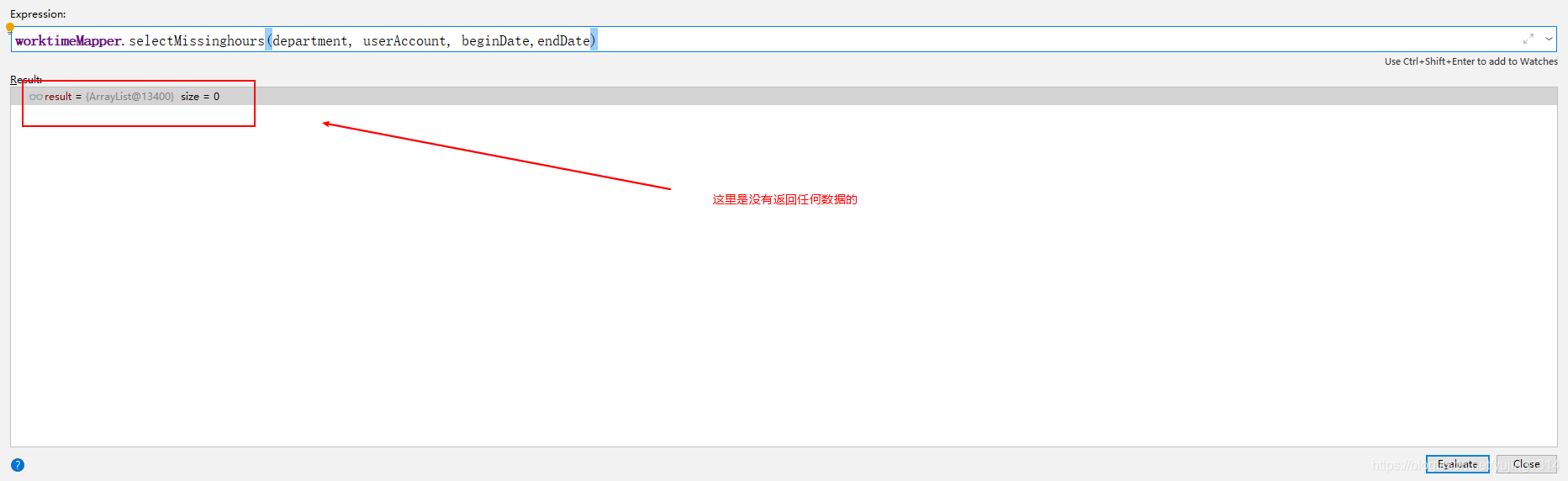
java代码中调用dao层查询接口,代码没有返回数据,打印出的sql查出了数据
Golang深入浅出之-Channels基础:创建、发送与接收数据
Redis入门到通关之多路复用详解
Redis入门到通关之Redis5种网络模型详解
Kubernetes 集群的持续性能优化实践
Golang深入浅出之-Go语言并发编程面试:Goroutine简介与创建
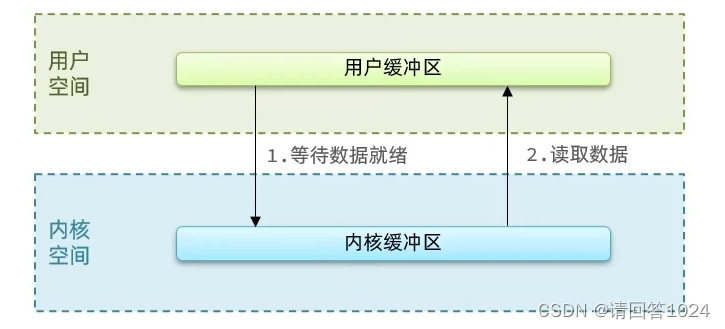
Redis入门到通关之Redis网络模型-用户空间和内核态空间
Redis入门到通关之Redis数据结构-Hash篇
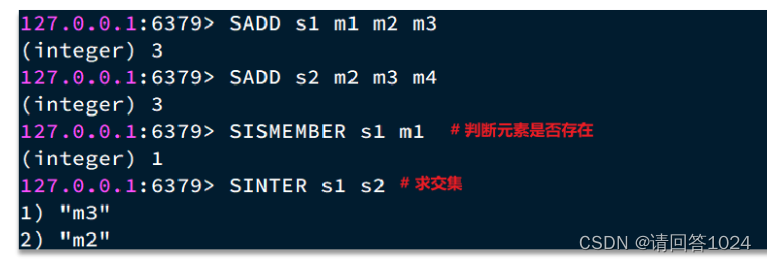
Redis入门到通关之Redis数据结构-Set篇
Golang深入浅出之-接口(Interfaces)详解:抽象、实现与空接口
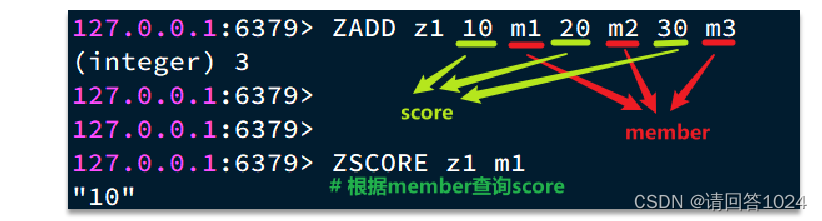
Redis入门到通关之Redis数据结构-ZSet篇
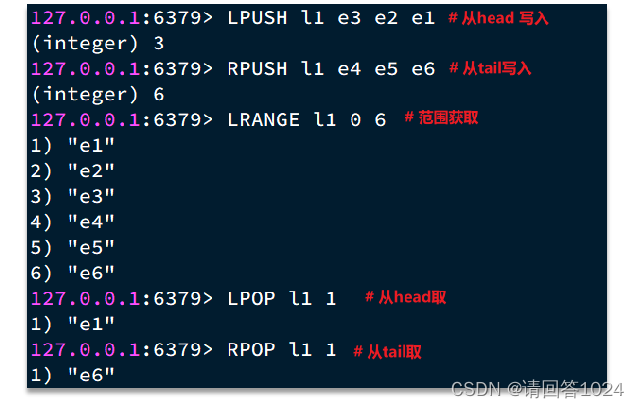
Redis入门到通关之Redis数据结构-List篇
Redis入门到通关之Redis数据结构-String篇
Redis入门到通关之数据结构解析-IntSet
Golang深入浅出之-Go语言方法与接收者:面向对象编程初探
Redis入门到通关之数据结构解析-SkipList
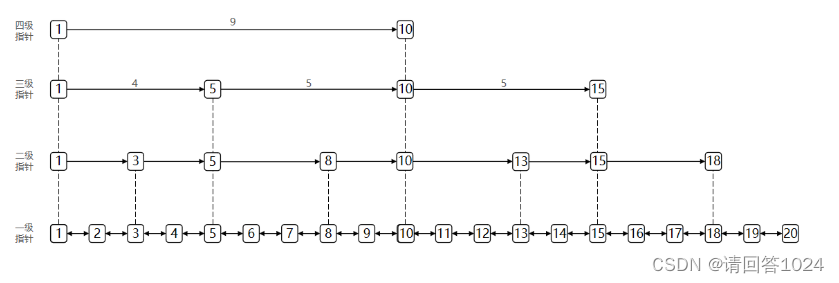
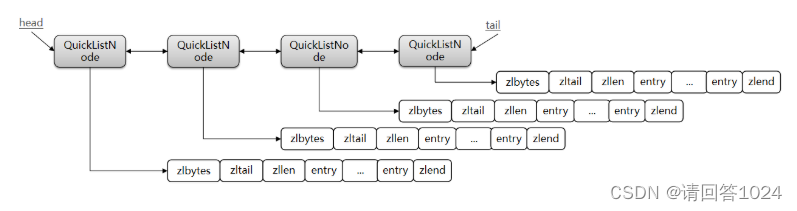
Redis入门到通关之数据结构解析-QuickList
网络安全与信息安全:防护之道在技术与意识的双重保障
Redis入门到通关之数据结构解析-动态字符串SDS
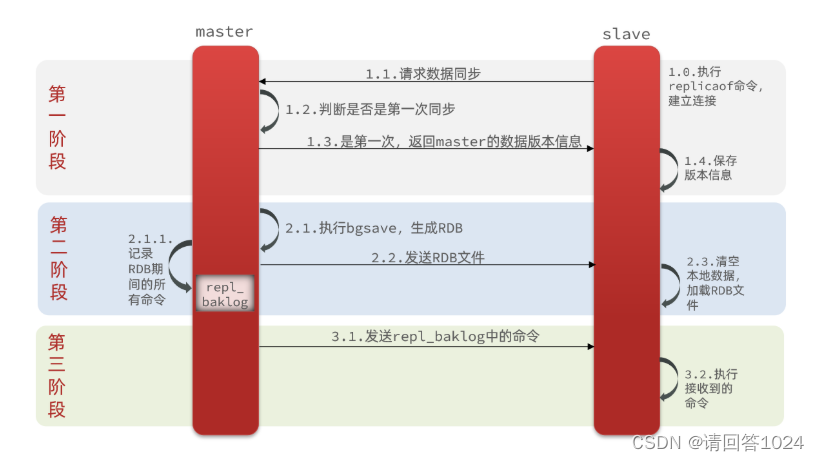
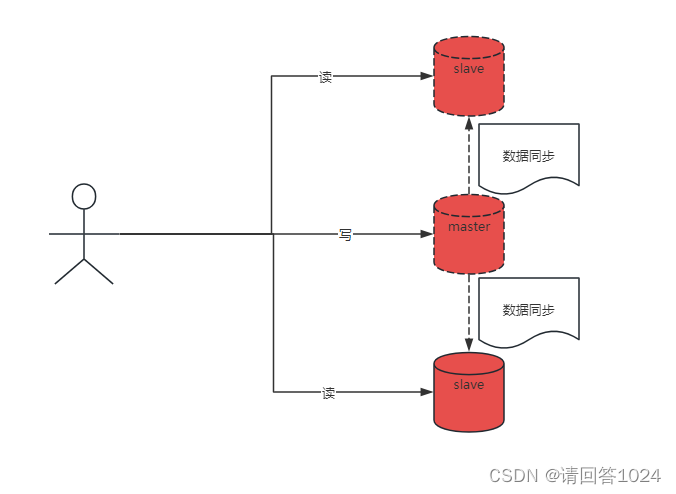
Redis入门到通关之Redis主从数据同步原理
Redis入门到通关之数据结构解析-Dict
使用Docker搭建Redis主从集群
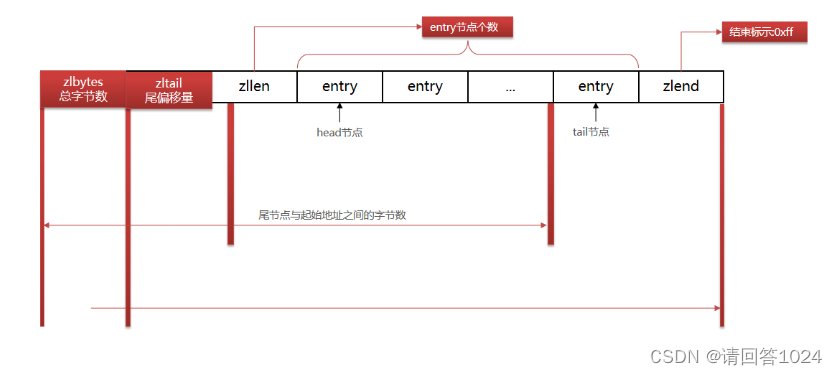
Redis入门到通关之数据结构解析-ZipList
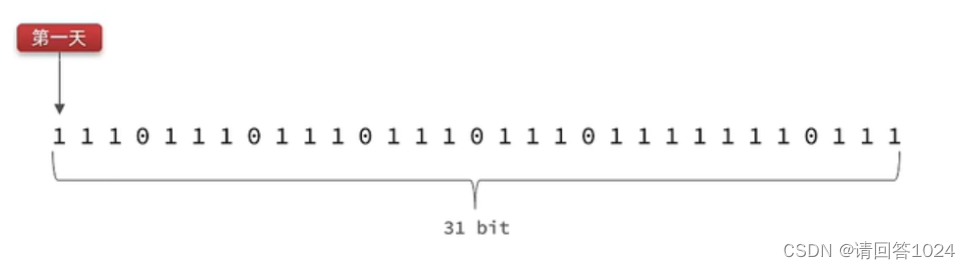
Redis入门到通关之BitMap实现签到
效率工具RunFlow完全手册之进阶篇
pollLast() 和poll啥区别
小图标还不会设计!
为啥加问号?可选链(Optional Chaining)的操作符
箭头函数多个函数体
深入理解PHP的命名空间
#是啥,v-slot插槽的区别
scoped的作用是这些!
深入理解PHP中的命名空间
彻底大悟!逆波兰表达式求值(150)
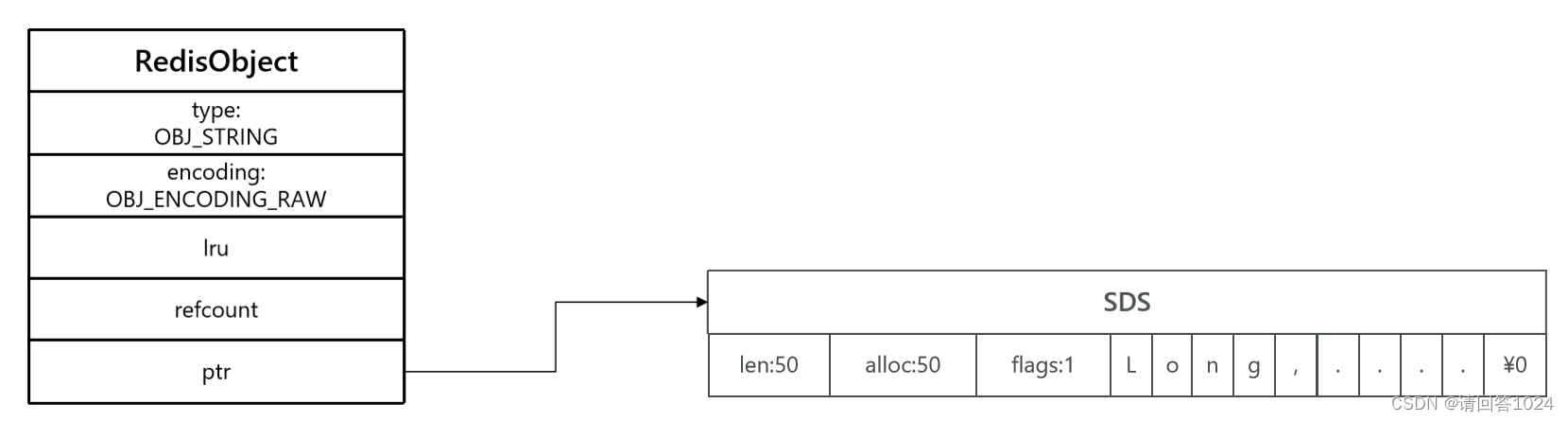
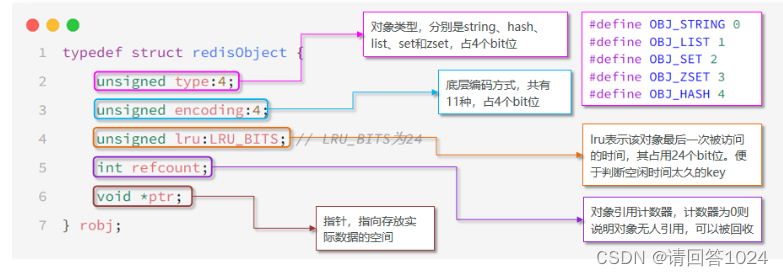
Redis入门到通关之数据结构解析-RedisObject
location.href和 window.location的区别有这些!
构建未来:云原生架构在现代企业中的应用与挑战