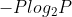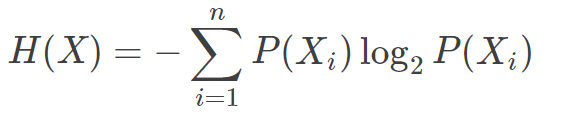在 Riak 的众多概念中,存在一个称作 Active Anti-Entropy 的,由于从字面上很难理解其真实含义,所以稍微研究了一番。结果发现水还是比较深的~
下面通过一些相关资料的研读,展开这次的知识学习。
---
Active Anti-Entropy
对于针对各副本仅作宽松一致性保证的分布式系统来说,需要一种方法将副本状态最终收敛为一致;在大数据集上进行上述收敛行为是非常有难度的; 无论是对数据集进行处理,还是在数据集之间进行比较都需要高昂的代价;
如果两个副本确实不同,那么如何高效地确定到底哪片数据不同是关键,因为只有确定后才能对不一致数据进行修复;
许多实现了最终一致性的数据库,例如 Cassandra, Riak 和 Voldemort 都实现了 Amazon Dynamo 论文中给出的方法;
Amazon Dynamo 论文中给出一种高效的、基于 Merkle Tree's (hash tree) 比较数据是否相同的方法;
BitTorrent 的实现中同样使用了 merkle tree 。
Merkle Tree
merkle tree 的叶子节点值是针对目标 data 计算得到的 hash 值;
而非叶子节点的值是针对其下子节点的 hash 值的串联(concatenate)进行的 hash 求值;
这种结构允许你按照自上而下的方式进行比较,以确认数据差异发生在何处;
如果上层节点的 hash 值相同,那么其下子节点的 hash 值一定相同,故不需要进行额外比较了;
Anti-entropy
反熵(Anti-entropy)就是指发现不一致并且修复这些不一致的处理过程。
有些时候,反熵会被简单描述成手动发起的“修复(repair)”行为(但这种描述可能存在问题);
在 Riak 中,针对何为 active anti-entropy 进行了详细的解释说明;
Active anti-entropy 可以理解成“在后台,连续性的、自动的,在不同副本间进行 merkle tree 比较,并修复不一致的过程”;
以我的观点来看,是否选择 active anti-entropy 机制进行处理,取决于实际系统中的各种因素,以及就特定工作负载的特性;
Joseph Blomstedt has an excellent video describing how active anti-entropy works in Riak. The video is also a really great example of how merkle tree's work so I suggest anyone using Cassandra or Riak or just interested in distributed systems to give it a watch. Or four.
---
Why is the word “entropy” present in anti-entropy protocols?
Q: Anti-entropy protocols are a form of gossip protocols. http://en.wikipedia.org/wiki/Gossip_protocol. I was wondering if someone could explain, the the significance of word entropy here.A: The noise creeping into the messages can be seen as a form of growing entropy in the message content. Cancelling the noise (in this case by comparing multiple replicas of the original message) is a form of entropy lowering process (i.e. an anti-entropy process, since entropy is never decreasing on its own).
Q: This answer is somewhat convincing, but eoht.info/page/Anti-entropy says that term anti-entropy is generally used to define process which are orderly and organized. I think there is still no orderly behavior in replica reconciliation. Do you think this use of anti-entropy has no significance here.
A: entropy itself is not a process, rather is it a statistical quality (usually in the field of physics or informatics), which never decreases (on it's own). I'm reading that page so that the a-e processes are working against the "natural" way entropy does. In the case of replica reconciliation it is not the process of comparing the copies itself but its output (something that seems to be the correct "average" closest to the original) that works against the noise (entropy) added during transmissions/copying earlier.
关键点:
- 熵本身不是处理过程,而是一种统计量,通常用于物理学和信息学领域;
- 熵自身从不会减少;
- 反熵是指一种降低熵的处理过程;
- 针对多副本协调的场景,反熵处理并非指针对副本本身的比较处理,而是指针对传输或复制过程中附加上熵的输出内容(个人理解为原始数据的副本)的处理;
---
Gossip protocol
gossip 协议是一种计算机间的通信协议,受启发于社交网络中的流言传播模型;现代分布式系统经常使用 gossip 协议解决某一类特定问题,因为此类问题使用其他方式很难解决;
使用 gossip 协议的两种场景:
- 底层网络属于超大型异构网络(inconvenient structure);
- 基于 gossip 的解决方案最为高效;
因为 gossip 协议传播信息的方式在某种程度上类似于生物界的病毒传播方式;
Gossip 的通信模型
The concept of gossip communication can be illustrated by the analogy of office workers spreading rumors. Let's say each hour the office workers congregate around the water cooler. Each employee pairs off with another, chosen at random, and shares the latest gossip. At the start of the day, Alice starts a new rumor: she comments to Bob that she believes that Charlie dyes his mustache. At the next meeting, Bob tells Dave, while Alice repeats the idea to Eve. After each water cooler rendezvous, the number of individuals who have heard the rumor roughly doubles (though this doesn't account for gossiping twice to the same person; perhaps Alice tries to tell the story to Frank, only to find that Frank already heard it from Dave). Computer systems typically implement this type of protocol with a form of random "peer selection": with a given frequency, each machine picks another machine at random and shares any hot rumors.
计算机系统典型的实现方式为,采取一种随机的“peer 选举”方法。即指定某个频率,每台机器随机选择另外一台机器,之后做 gossip 的传播;
gossip 协议的强悍之处在于强劲的信息传播方式;因为相同的信息很可能会反复接收到多次;
以更加技术性的术语进行表达,gossip 协议需要满足以下各个条件:
- 协议的核心特性为:周期性,两两配对,进程间交互;
- 交互中的信息交换是大小受限的;
- 只要 agent 间发生了交互,则至少有一个 agent 发生了状态变更,以反应出对端的状态;
- 不假定底层一定采用了可靠通信方式;
- 交互的频率与典型的消息延迟相比仍旧算低的,所以协议本身的附加成本是可以忽略的;
由于复制(随机性)的原因,理论上讲存在信息投递冗余的可能;
Gossip protocol 种类
准确区分 3 种比较流行的 gossip 协议类型是非常有必要的:
Dissemination 协议(或者称为 rumor-mongering 协议)
该协议基于 gossip 进行信息传播;
其工作方式是通过网络中的 flooding 代理进行 gossip 传播;但是要求其只能产生受限的 worst-case 负载;
Anti-entropy 协议
主要用于修复数据副本,通过比较副本和收敛差异达到效果;
聚合计算协议
该协议通过“对网络中节点上的信息进行抽样,再进行归并处理,最终获得一个系统范围(system-wide)的统一值”的方式,进行网络范围(network-wide)聚合计算。
该协议常用于获取被测节点中的最大值,最小值等;
Tribler, BitTorrent peer to peer client using gossip protocol.
---
Merkle tree
hash tree 就是 Merkle tree ;在 Merkle tree 中,每一个非叶子节点均以特定 label 的 hash 值进行标记;每一个叶子节点则对应特定的数据值;
hash tree 的用途:可以高效、安全的验证大数据结构中包含的内容;
hash tree 可以认为是 hash list 和 hash chain 的泛化形式;
证明某个叶子节点属于某个 hash tree 的一部分所需的计算量,与该 hash tree 节点数的兑数(log)成正比;
而对于 hash list 来说,则与 list 中的节点数目成正比;
hash tree 的概念由 Ralph Merkle 在 1979 年命名;
应用场景
hash tree 被用于确定不同计算机之间保存的、处理后的,以及经过传输后的,任何类型的数据差异;
当前 hash tree 的主要用于确保从 P2P 网络中、其他 peer 上得到的数据块是未经损坏和变更过的;甚至还可以检查出其他 peer 是否有发送假数据块的欺骗行为;
hash tree 被建议用在受信计算机系统中;
hash tree 已被用于 IPFS 和 ZFS 文件系统中,BitTorrent 协议中,Apache Wave 协议中,Git 分布式修正控制系统中,Tahoe-LAFS 备份系统中,Bitcoin P2P 网络中,Certificate Transparency 框架中,以及许多 NoSQL 系统(Apache Cassandra 和 Riak)中。
设计 hash tree 的原始目的是用来高效的处理 Lamport 一次性签名问题;
每一个 Lamport key 只能用于签名一条单独的消息,但是在与 hash tree 结合使用后,每一个 Lamport key 就可以用于许多条消息的签名了,这种结合使用最终变成了一种非常高效的数字签名机制 Merkle signature scheme ;
概览
A hash tree is a tree of hashes in which the leaves are hashes of data blocks in, for instance, a file or set of files. Nodes further up in the tree are the hashes of their respective children. For example, in the picture hash 0 is the result of hashing the result of concatenating hash 0-0 and hash 0-1. That is, hash 0 = hash( hash 0-0 + hash 0-1 ) where + denotes concatenation.
Most hash tree implementations are binary (two child nodes under each node) but they can just as well use many more child nodes under each node.
Usually, a cryptographic hash function such as SHA-2 is used for the hashing. If the hash tree only needs to protect against unintentional damage, much less secure checksums such as CRCs can be used.
In the top of a hash tree there is a top hash (or root hash or master hash). Before downloading a file on a p2p network, in most cases the top hash is acquired from a trusted source, for instance a friend or a web site that is known to have good recommendations of files to download. When the top hash is available, the hash tree can be received from any non-trusted source, like any peer in the p2p network. Then, the received hash tree is checked against the trusted top hash, and if the hash tree is damaged or fake, another hash tree from another source will be tried until the program finds one that matches the top hash.
The main difference from a hash list is that one branch of the hash tree can be downloaded at a time and the integrity of each branch can be checked immediately, even though the whole tree is not available yet. For example, in the picture, the integrity of data block 2 can be verified immediately if the tree already contains hash 0-0 and hash 1 by hashing the data block and iteratively combining the result with hash 0-0 and then hash 1 and finally comparing the result with the top hash. Similarly, the integrity of data block 3 can be verified if the tree already has hash 1-1 and hash 0. This can be an advantage since it is efficient to split files up in very small data blocks so that only small blocks have to be re-downloaded if they get damaged. If the hashed file is very big, such a hash tree or hash list becomes fairly big. But if it is a tree, one small branch can be downloaded quickly, the integrity of the branch can be checked, and then the downloading of data blocks can start.

---