1.主频
主频也叫时钟频率,单位是MHz,用来表示CPU的运算速度。CPU的主频=外频×倍频系数。很多人认为主频就决定着CPU的运行速度,这不仅是个片面的,而且对于服务器来讲,这个认识也出现了偏差。至今,没有一条确定的公式能够实现主频和实际的运算速度两者之间的数值关系,即使是两大处理器厂家Intel和AMD,在这点上也存在着很大的争议,我们从Intel的产品的发展趋势,可以看出Intel很注重加强自身主频的发展。像其他的处理器厂家,有人曾经拿过一快1G的全美达来做比较,它的运行效率相当于2G的Intel处理器。
所以,CPU的主频与CPU实际的运算能力是没有直接关系的,主频表示在CPU内数字脉冲信号震荡的速度。在Intel的处理器产品中,我们也可以看到这样的例子:1GHzItanium芯片能够表现得差不多跟2.66GHzXeon/Opteron一样快,或是1.5GHzItanium2大约跟4GHzXeon/Opteron一样快。CPU的运算速度还要看CPU的流水线的各方面的性能指标。
当然,主频和实际的运算速度是有关的,只能说主频仅仅是CPU性能表现的一个方面,而不代表CPU的整体性能。
2.外频
外频是CPU的基准频率,单位也是MHz。CPU的外频决定着整块主板的运行速度。说白了,在台式机中,我们所说的超频,都是超CPU的外频(当然一般情况下,CPU的倍频都是被锁住的)相信这点是很好理解的。但对于服务器CPU来讲,超频是绝对不允许的。前面说到CPU决定着主板的运行速度,两者是同步运行的,如果把服务器CPU超频了,改变了外频,会产生异步运行,(台式机很多主板都支持异步运行)这样会造成整个服务器系统的不稳定。
目前的绝大部分电脑系统中外频也是内存与主板之间的同步运行的速度,在这种方式下,可以理解为CPU的外频直接与内存相连通,实现两者间的同步运行状态。外频与前端总线(FSB)频率很容易被混为一谈,下面的前端总线介绍我们谈谈两者的区别。
3.前端总线(FSB)频率
前端总线(FSB)频率(即总线频率)是直接影响CPU与内存直接数据交换速度。有一条公式可以计算,即数据带宽=(总线频率×数据带宽)/8,数据传输最大带宽取决于所有同时传输的数据的宽度和传输频率。比方,现在的支持64位的至强Nocona,前端总线是800MHz,按照公式,它的数据传输最大带宽是6.4GB/秒。
外频与前端总线(FSB)频率的区别:前端总线的速度指的是数据传输的速度,外频是CPU与主板之间同步运行的速度。也就是说,100MHz外频特指数字脉冲信号在每秒钟震荡一千万次;而100MHz前端总线指的是每秒钟CPU可接受的数据传输量是100MHz×64bit÷8Byte/bit=800MB/s。
其实现在“HyperTransport”构架的出现,让这种实际意义上的前端总线(FSB)频率发生了变化。之前我们知道IA-32架构必须有三大重要的构件:内存控制器Hub(MCH),I/O控制器Hub和PCIHub,像Intel很典型的芯片组Intel7501、Intel7505芯片组,为双至强处理器量身定做的,它们所包含的MCH为CPU提供了频率为533MHz的前端总线,配合DDR内存,前端总线带宽可达到4.3GB/秒。但随着处理器性能不断提高同时给系统架构带来了很多问题。而“HyperTransport”构架不但解决了问题,而且更有效地提高了总线带宽,比方AMDOpteron处理器,灵活的HyperTransportI/O总线体系结构让它整合了内存控制器,使处理器不通过系统总线传给芯片组而直接和内存交换数据。这样的话,前端总线(FSB)频率在AMDOpteron处理器就不知道从何谈起了。
4、CPU的位和字长
位:在数字电路和电脑技术中采用二进制,代码只有“0”和“1”,其中无论是“0”或是“1”在CPU中都是一“位”。
字长:电脑技术中对CPU在单位时间内(同一时间)能一次处理的二进制数的位数叫字长。所以能处理字长为8位数据的CPU通常就叫8位的CPU。同理32位的CPU就能在单位时间内处理字长为32位的二进制数据。字节和字长的区别:由于常用的英文字符用8位二进制就可以表示,所以通常就将8位称为一个字节。字长的长度是不固定的,对于不同的CPU、字长的长度也不一样。8位的CPU一次只能处理一个字节,而32位的CPU一次就能处理4个字节,同理字长为64位的CPU一次可以处理8个字节。
5.倍频系数
倍频系数是指CPU主频与外频之间的相对比例关系。在相同的外频下,倍频越高CPU的频率也越高。但实际上,在相同外频的前提下,高倍频的CPU本身意义并不大。这是因为CPU与系统之间数据传输速度是有限的,一味追求高倍频而得到高主频的CPU就会出现明显的“瓶颈”效应—CPU从系统中得到数据的极限速度不能够满足CPU运算的速度。一般除了工程样版的Intel的CPU都是锁了倍频的,而AMD之前都没有锁。
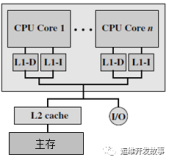
6.缓存
缓存大小也是CPU的重要指标之一,而且缓存的结构和大小对CPU速度的影响非常大,CPU内缓存的运行频率极高,一般是和处理器同频运作,工作效率远远大于系统内存和硬盘。实际工作时,CPU往往需要重复读取同样的数据块,而缓存容量的增大,可以大幅度提升CPU内部读取数据的命中率,而不用再到内存或者硬盘上寻找,以此提高系统性能。但是由于CPU芯片面积和成本的因素来考虑,缓存都很小。
L1Cache(一级缓存)是CPU第一层高速缓存,分为数据缓存和指令缓存。内置的L1高速缓存的容量和结构对CPU的性能影响较大,不过高速缓冲存储器均由静态RAM组成,结构较复杂,在CPU管芯面积不能太大的情况下,L1级高速缓存的容量不可能做得太大。一般服务器CPU的L1缓存的容量通常在32—256KB。
L2Cache(二级缓存)是CPU的第二层高速缓存,分内部和外部两种芯片。内部的芯片二级缓存运行速度与主频相同,而外部的二级缓存则只有主频的一半。L2高速缓存容量也会影响CPU的性能,原则是越大越好,现在家庭用CPU容量最大的是512KB,而服务器和工作站上用CPU的L2高速缓存更高达256-1MB,有的高达2MB或者3MB。
L3Cache(三级缓存),分为两种,早期的是外置,现在的都是内置的。而它的实际作用即是,L3缓存的应用可以进一步降低内存延迟,同时提升大数据量计算时处理器的性能。降低内存延迟和提升大数据量计算能力对游戏都很有帮助。而在服务器领域增加L3缓存在性能方面仍然有显著的提升。比方具有较大L3缓存的配置利用物理内存会更有效,故它比较慢的磁盘I/O子系统可以处理更多的数据请求。具有较大L3缓存的处理器提供更有效的文件系统缓存行为及较短消息和处理器队列长度。
其实最早的L3缓存被应用在AMD发布的K6-III处理器上,当时的L3缓存受限于制造工艺,并没有被集成进芯片内部,而是集成在主板上。在只能够和系统总线频率同步的L3缓存同主内存其实差不了多少。后来使用L3缓存的是英特尔为服务器市场所推出的Itanium处理器。接着就是P4EE和至强MP。Intel还打算推出一款9MBL3缓存的Itanium2处理器,和以后24MBL3缓存的双核心Itanium2处理器。
但基本上L3缓存对处理器的性能提高显得不是很重要,比方配备1MBL3缓存的XeonMP处理器却仍然不是Opteron的对手,由此可见前端总线的增加,要比缓存增加带来更有效的性能提升。
7.CPU扩展指令集
CPU依靠指令来计算和控制系统,每款CPU在设计时就规定了一系列与其硬件电路相配合的指令系统。指令的强弱也是CPU的重要指标,指令集是提高微处理器效率的最有效工具之一。从现阶段的主流体系结构讲,指令集可分为复杂指令集和精简指令集两部分,而从具体运用看,如Intel的MMX(MultiMediaExtended)、SSE、SSE2(Streaming-Singleinstructionmultipledata-Extensions2)、SEE3和AMD的3DNow!等都是CPU的扩展指令集,分别增强了CPU的多媒体、图形图象和Internet等的处理能力。我们通常会把CPU的扩展指令集称为"CPU的指令集"。SSE3指令集也是目前规模最小的指令集,此前MMX包含有57条命令,SSE包含有50条命令,SSE2包含有144条命令,SSE3包含有13条命令。目前SSE3也是最先进的指令集,英特尔Prescott处理器已经支持SSE3指令集,AMD会在未来双核心处理器当中加入对SSE3指令集的支持,全美达的处理器也将支持这一指令集。
8.CPU内核和I/O工作电压
从586CPU开始,CPU的工作电压分为内核电压和I/O电压两种,通常CPU的核心电压小于等于I/O电压。其中内核电压的大小是根据CPU的生产工艺而定,一般制作工艺越小,内核工作电压越低;I/O电压一般都在1.6~5V。低电压能解决耗电过大和发热过高的问题。
9.制造工艺
主频也叫时钟频率,单位是MHz,用来表示CPU的运算速度。CPU的主频=外频×倍频系数。很多人认为主频就决定着CPU的运行速度,这不仅是个片面的,而且对于服务器来讲,这个认识也出现了偏差。至今,没有一条确定的公式能够实现主频和实际的运算速度两者之间的数值关系,即使是两大处理器厂家Intel和AMD,在这点上也存在着很大的争议,我们从Intel的产品的发展趋势,可以看出Intel很注重加强自身主频的发展。像其他的处理器厂家,有人曾经拿过一快1G的全美达来做比较,它的运行效率相当于2G的Intel处理器。
所以,CPU的主频与CPU实际的运算能力是没有直接关系的,主频表示在CPU内数字脉冲信号震荡的速度。在Intel的处理器产品中,我们也可以看到这样的例子:1GHzItanium芯片能够表现得差不多跟2.66GHzXeon/Opteron一样快,或是1.5GHzItanium2大约跟4GHzXeon/Opteron一样快。CPU的运算速度还要看CPU的流水线的各方面的性能指标。
当然,主频和实际的运算速度是有关的,只能说主频仅仅是CPU性能表现的一个方面,而不代表CPU的整体性能。
2.外频
外频是CPU的基准频率,单位也是MHz。CPU的外频决定着整块主板的运行速度。说白了,在台式机中,我们所说的超频,都是超CPU的外频(当然一般情况下,CPU的倍频都是被锁住的)相信这点是很好理解的。但对于服务器CPU来讲,超频是绝对不允许的。前面说到CPU决定着主板的运行速度,两者是同步运行的,如果把服务器CPU超频了,改变了外频,会产生异步运行,(台式机很多主板都支持异步运行)这样会造成整个服务器系统的不稳定。
目前的绝大部分电脑系统中外频也是内存与主板之间的同步运行的速度,在这种方式下,可以理解为CPU的外频直接与内存相连通,实现两者间的同步运行状态。外频与前端总线(FSB)频率很容易被混为一谈,下面的前端总线介绍我们谈谈两者的区别。
3.前端总线(FSB)频率
前端总线(FSB)频率(即总线频率)是直接影响CPU与内存直接数据交换速度。有一条公式可以计算,即数据带宽=(总线频率×数据带宽)/8,数据传输最大带宽取决于所有同时传输的数据的宽度和传输频率。比方,现在的支持64位的至强Nocona,前端总线是800MHz,按照公式,它的数据传输最大带宽是6.4GB/秒。
外频与前端总线(FSB)频率的区别:前端总线的速度指的是数据传输的速度,外频是CPU与主板之间同步运行的速度。也就是说,100MHz外频特指数字脉冲信号在每秒钟震荡一千万次;而100MHz前端总线指的是每秒钟CPU可接受的数据传输量是100MHz×64bit÷8Byte/bit=800MB/s。
其实现在“HyperTransport”构架的出现,让这种实际意义上的前端总线(FSB)频率发生了变化。之前我们知道IA-32架构必须有三大重要的构件:内存控制器Hub(MCH),I/O控制器Hub和PCIHub,像Intel很典型的芯片组Intel7501、Intel7505芯片组,为双至强处理器量身定做的,它们所包含的MCH为CPU提供了频率为533MHz的前端总线,配合DDR内存,前端总线带宽可达到4.3GB/秒。但随着处理器性能不断提高同时给系统架构带来了很多问题。而“HyperTransport”构架不但解决了问题,而且更有效地提高了总线带宽,比方AMDOpteron处理器,灵活的HyperTransportI/O总线体系结构让它整合了内存控制器,使处理器不通过系统总线传给芯片组而直接和内存交换数据。这样的话,前端总线(FSB)频率在AMDOpteron处理器就不知道从何谈起了。
4、CPU的位和字长
位:在数字电路和电脑技术中采用二进制,代码只有“0”和“1”,其中无论是“0”或是“1”在CPU中都是一“位”。
字长:电脑技术中对CPU在单位时间内(同一时间)能一次处理的二进制数的位数叫字长。所以能处理字长为8位数据的CPU通常就叫8位的CPU。同理32位的CPU就能在单位时间内处理字长为32位的二进制数据。字节和字长的区别:由于常用的英文字符用8位二进制就可以表示,所以通常就将8位称为一个字节。字长的长度是不固定的,对于不同的CPU、字长的长度也不一样。8位的CPU一次只能处理一个字节,而32位的CPU一次就能处理4个字节,同理字长为64位的CPU一次可以处理8个字节。
5.倍频系数
倍频系数是指CPU主频与外频之间的相对比例关系。在相同的外频下,倍频越高CPU的频率也越高。但实际上,在相同外频的前提下,高倍频的CPU本身意义并不大。这是因为CPU与系统之间数据传输速度是有限的,一味追求高倍频而得到高主频的CPU就会出现明显的“瓶颈”效应—CPU从系统中得到数据的极限速度不能够满足CPU运算的速度。一般除了工程样版的Intel的CPU都是锁了倍频的,而AMD之前都没有锁。
6.缓存
缓存大小也是CPU的重要指标之一,而且缓存的结构和大小对CPU速度的影响非常大,CPU内缓存的运行频率极高,一般是和处理器同频运作,工作效率远远大于系统内存和硬盘。实际工作时,CPU往往需要重复读取同样的数据块,而缓存容量的增大,可以大幅度提升CPU内部读取数据的命中率,而不用再到内存或者硬盘上寻找,以此提高系统性能。但是由于CPU芯片面积和成本的因素来考虑,缓存都很小。
L1Cache(一级缓存)是CPU第一层高速缓存,分为数据缓存和指令缓存。内置的L1高速缓存的容量和结构对CPU的性能影响较大,不过高速缓冲存储器均由静态RAM组成,结构较复杂,在CPU管芯面积不能太大的情况下,L1级高速缓存的容量不可能做得太大。一般服务器CPU的L1缓存的容量通常在32—256KB。
L2Cache(二级缓存)是CPU的第二层高速缓存,分内部和外部两种芯片。内部的芯片二级缓存运行速度与主频相同,而外部的二级缓存则只有主频的一半。L2高速缓存容量也会影响CPU的性能,原则是越大越好,现在家庭用CPU容量最大的是512KB,而服务器和工作站上用CPU的L2高速缓存更高达256-1MB,有的高达2MB或者3MB。
L3Cache(三级缓存),分为两种,早期的是外置,现在的都是内置的。而它的实际作用即是,L3缓存的应用可以进一步降低内存延迟,同时提升大数据量计算时处理器的性能。降低内存延迟和提升大数据量计算能力对游戏都很有帮助。而在服务器领域增加L3缓存在性能方面仍然有显著的提升。比方具有较大L3缓存的配置利用物理内存会更有效,故它比较慢的磁盘I/O子系统可以处理更多的数据请求。具有较大L3缓存的处理器提供更有效的文件系统缓存行为及较短消息和处理器队列长度。
其实最早的L3缓存被应用在AMD发布的K6-III处理器上,当时的L3缓存受限于制造工艺,并没有被集成进芯片内部,而是集成在主板上。在只能够和系统总线频率同步的L3缓存同主内存其实差不了多少。后来使用L3缓存的是英特尔为服务器市场所推出的Itanium处理器。接着就是P4EE和至强MP。Intel还打算推出一款9MBL3缓存的Itanium2处理器,和以后24MBL3缓存的双核心Itanium2处理器。
但基本上L3缓存对处理器的性能提高显得不是很重要,比方配备1MBL3缓存的XeonMP处理器却仍然不是Opteron的对手,由此可见前端总线的增加,要比缓存增加带来更有效的性能提升。
7.CPU扩展指令集
CPU依靠指令来计算和控制系统,每款CPU在设计时就规定了一系列与其硬件电路相配合的指令系统。指令的强弱也是CPU的重要指标,指令集是提高微处理器效率的最有效工具之一。从现阶段的主流体系结构讲,指令集可分为复杂指令集和精简指令集两部分,而从具体运用看,如Intel的MMX(MultiMediaExtended)、SSE、SSE2(Streaming-Singleinstructionmultipledata-Extensions2)、SEE3和AMD的3DNow!等都是CPU的扩展指令集,分别增强了CPU的多媒体、图形图象和Internet等的处理能力。我们通常会把CPU的扩展指令集称为"CPU的指令集"。SSE3指令集也是目前规模最小的指令集,此前MMX包含有57条命令,SSE包含有50条命令,SSE2包含有144条命令,SSE3包含有13条命令。目前SSE3也是最先进的指令集,英特尔Prescott处理器已经支持SSE3指令集,AMD会在未来双核心处理器当中加入对SSE3指令集的支持,全美达的处理器也将支持这一指令集。
8.CPU内核和I/O工作电压
从586CPU开始,CPU的工作电压分为内核电压和I/O电压两种,通常CPU的核心电压小于等于I/O电压。其中内核电压的大小是根据CPU的生产工艺而定,一般制作工艺越小,内核工作电压越低;I/O电压一般都在1.6~5V。低电压能解决耗电过大和发热过高的问题。
9.制造工艺
制造工艺的微米是指IC内电路与电路之间的距离。制造工艺的趋势是向密集度愈高的方向发展。密度愈高的IC电路设计,意味着在同样大小面积的IC中,可以拥有密度更高、功能更复杂的电路设计。现在主要的180nm、130nm、90nm。最近官方已经表示有65nm的制造工艺了。
本文转自starger51CTO博客,原文链接: http://blog.51cto.com/starger/17631,如需转载请自行联系原作者