Kafka-manager部署
一、概念
概念百度了一下,可以根据相关资料进行理解。
1.1 Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。
Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker。
Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
Partition
Partition是物理上的概念,每个Topic包含一个或多个Partition.
Producer
负责发布消息到Kafka broker
Consumer
消息消费者,向Kafka broker读取消息的客户端。
Consumer Group
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
1.2 ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
ZooKeeper的基本运转流程:
1、选举Leader。
2、同步数据。
3、选举Leader过程中算法有很多,但要达到的选举标准是一致的。
4、Leader要具有最高的执行ID,类似root权限。
5、集群中大多数的机器得到响应并follow选出的Leader。
1.3 kafka-manager为了简化开发者和服务工程师维护Kafka集群的工作,yahoo构建了一个叫做Kafka管理器的基于Web工具,叫做 Kafka Manager。这个管理工具可以很容易地发现分布在集群中的哪些topic分布不均匀,或者是分区在整个集群分布不均匀的的情况。它支持管理多个集群、选择副本、副本重新分配以及创建Topic。同时,这个管理工具也是一个非常好的可以快速浏览这个集群的工具,有如下功能:
1.管理多个kafka集群
2.便捷的检查kafka集群状态(topics,brokers,备份分布情况,分区分布情况)
3.选择你要运行的副本
4.基于当前分区状况进行
5.可以选择topic配置并创建topic(0.8.1.1和0.8.2的配置不同)
6.删除topic(只支持0.8.2以上的版本并且要在broker配置中设置delete.topic.enable=true)
7.Topic list会指明哪些topic被删除(在0.8.2以上版本适用)
8.为已存在的topic增加分区
9.为已存在的topic更新配置
10.在多个topic上批量重分区
11.在多个topic上批量重分区(可选partition broker位置)
kafka-manager 项目地址:https://github.com/yahoo/kafka-manager
二、部署
2.1 初始化环境
初始化系统,关闭防火墙修改主机名与ip名称
名称 |
HOSTNAME |
IP |
1 |
kafka-1 |
172.17.10.207 |
2 |
kafka-2 |
172.17.10.208 |
3 |
kafka-3 |
172.17.10.209 |

2.2 java安装
yum install -y java-1.8.0-openjdk
2.3 安装zookeeper(三台都装)
cd /usr/local wget http://apache.fayea.com/zookeeper/zookeeper-3.4.9/zookeeper-3.4.9.tar.gz tar zxf zookeeper-3.4.9.tar.gz mv zookeeper-3.4.9 zookeeper cd zookeeper/conf cp zoo_sample.cfg zoo.cfg
编辑zoo.cfg
tickTime=2000 #服务之间或者客户端与服务段之间心跳时间 initLimit=10 #Follower启动过程中,从Leader同步所有最新数据的时间 syncLimit=5 #Leader与集群之间的通信时间 dataDir=/usr/local/zookeeper/data #zookeeper存储数据 datalogDir=/usr/local/zookeeper/logs #zookeeper存储数据的日志 clientPort=2181 #zookeeper默认端口 #集群配置信息 server.1=172.17.10.207:2888:3888 server.2=172.17.10.208:2888:3888 server.3=172.17.10.209:2888:3888
server.1 这个1是服务器的标识也可以是其他的数字, 表示这个是第几号服务器,用来标识服务器,这个标识要写到快照目录下面myid文件里
#172.17.10.207为集群里的IP地址,第一个端口是master和slave之间的通信端口,默认是2888,第二个端口是leader选举的端口,集群刚启动的时候选举或者leader挂掉之后进行新的选举的端口默认是3888
完整配置

cd /usr/local/zookeeper mkdir data logs #创建数据与日志文件夹 cd data echo “1”>myid #第2 台zookeeper服务器就echo 2 /usr/local/zookeeper/bin/zkServer.sh start #启动

/usr/local/zookeeper/bin/zkServer.sh status #查看状态

2.4 安装kafka(三台都装)
wget http://apache.fayea.com/kafka/0.10.0.0/kafka_2.11-0.10.0.0.tgz tar zxf kafka_2.11-0.10.0.0.tgz mv kafka_2.11-0.10.0.0/ kafka cd kafka/config
编辑 server.properties
broker.id=1 #kafka集群标识,不能相同,第一台是1以此类推,其他都一样。 log.dirs=/usr/local/kafka-logs host.name=172.17.10.184 #主机ip zookeeper.connect=172.17.10.185:2181,172.17.10.184:2181,172.17.10.183:2181 mkdir /usr/local/kafka/kafka-logs /usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties & #启动kafka
查看是否启动成功
netstat -ntpl|grep 9092

2.4 安装kafka-manager
git clone https://github.com/yahoo/kafka-manager cd kafka-manager sbt clean distcd #过程比较长
得到文件kafka-manager-1.3.0.8.zip
unzip kafka-manager-1.3.0.8.zip -d /usr/local cd /usr/local/kafka-manager-1.3.0.8 修改配置 conf/application.properties # 如果zk是集群,这里填写多个zk地址 kafka-manager.zkhosts="172.17.10.185:2181,172.17.10.184:2181,172.17.10.183:2181"
启动
kafka-manager 默认的端口是9000,可通过 -Dhttp.port,指定端口; -Dconfig.file=conf/application.conf指定配置文件: nohup bin/kafka-manager -Dconfig.file=conf/application.conf -Dhttp.port=8080 &
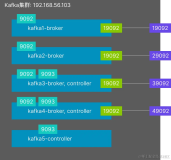
浏览器访问
C5([H1BQQ0ZN`TLC.png")
三、测试
对Kafka进行测试。分别创建topic,producer,consumer,最好是在不同的节点上创建。在producer的控制台上输入信息,观察consumer控制台是否能够接收到。
3.1 创建topic
./kafka-topics.sh --create --zookeeper 172.17.10.207:2181,172.17.10.208:2181,172.17.10.209:2181 --replication-factor 3 --partitions 3 --topic xuel
--replication-factor 指定partition的replicas数,建议设置为2;
--partitions 指定分区数,这个参数需要根据broker数和数据量决定,正常情况下,每个broker上两个partition最好;
--topic xuel 主题为xuel
3.2 查看topic
./kafka-topics.sh --describe --zookeeper 172.17.10.207:2181,172.17.10.208:2181,172.17.10.209:2181 --topic xuel
通过web界面创建topic-{1-4}
3$O_U07`7[L4EL8B.png")
3.3 删除topic
./kafka-topics.sh --delete --zookeeper 172.17.10.207:2181,172.17.10.208:2181,172.17.10.209:2181 --topic xuel
3.4 创建发布者
在一台服务器上创建一个发布者(发布者发送消息)
创建broker
./kafka-console-producer.sh --broker-list 172.17.10.173:9092,172.17.10.172:9092,172.17.10.171:9092,172.17.10.170:9092 --topic xuel

3.5 创建消费者
在一台服务器上创建一个订阅者(订阅者接受消息)
./kafka-console-consumer.sh --zookeeper 172.17.10.173:2181,172.17.10.172:2181,172.17.10.171:2181,172.17.10.170:2181 --from-beginning --topic xuel
J(}~S)ZJOFK.png")
3.6 通过web界面查看
AUUA)(%FOD~IZE@X7XEO.png")
1.png")
KRSCWLHMNC.png")