Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。也可以把它当作是分布式提交日志的发布-订阅消息,事实上Kafka官网上也是这么说明的。
关于Kafk你必须知道的几个关键术语
topics:Kafka接收的各种各样的消息
producers:发送消息到Kafka
consumers:从Kafka接收消息的订阅者
broker:一个或多个服务器组成的Kakfa集群
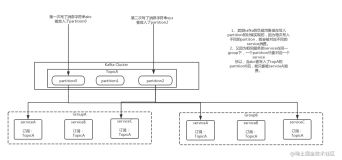
下图是一个生产者通过kafka集群发送给消费者的示例


Topics和Logs
一个Topic就是将发布的消息归类的过程,对于每一个topic,Kafka集群都会维护一个分区日志,如下图

每个分区都是有编号的,而且每个分区的消息也会根据提交的日志进行编号。分区中的消息会被分配一个唯一的编号,这个术语叫做offset,用以识别分区中的消息。
Kafka集群会保存所有的发布消息,无论这些消息在固定的时间内是否被消费者所消费。比如,消息日志设置的保存期间是2天,在消息发布的2天内,消费者可以消费,然后丢弃该条消息来释放空间。Kafka的性能跟数据空间无关,因此保存大量数据对于Kafka来说不是问题。
实际上,在日志中保存每个消费者位置的元数据才是“offset”。offset是由消费者控制的:一般来说,当消费者一行行读取消息时,offset才起作用。但实际上,消费者可以以任意他们想要的方式读取消息,因为消费者可以重置已存在的offset。
这种机制表明Kafka消费者是非常容易处理的-消息的处理对于集群或其它消费者来说几乎没有什么影响。比如,我们可以在命令行工具中使用“tail”topic来处理消息而不用改变已经存在的消费者。
日志分区有几种不同的目的。首先,能够避免一台服务器上的日志文件过大。每个独立的分区肯定位于同一台服务器上,并且在同一台服务器上处理,但是一个topic可能有多个分区,这样能够保证处理大量的数据。其次,分区可以作为并行处理的单元。
分布式
日志分布在Kafka集群中的不同分区上,每个服务器处理数据并请求共享分区。每个分区都是可以通过配置服务器的容错机制进行复制的。
每个分区都有一个服务器作为“leader(主节点)”,有0个或多个服务器作为“followers(从节点)”,主节点可以从分区中读写数据,但是从节点只能复制主节点的消息。如果主节点宕机,其中的一个从服务器会自动成为新的主服务器。主服务器处理一些分区的数据,从服务器处理其它服务器的数据,这样保存集群的平衡。
生产者(Producers)
生产者可以决定将消息发送到哪些topic,而且生产者可以选择将topic内的消息发送到哪个分区。这种简单的循环负载均衡方式能够在语义分区时完成。这种分区通常在1秒内完成。
消费者(Consumers)
传统的消息队列有两种处理方式:顺序处理和发布/订阅处理。在顺序处理方式时,消费者是按照消息进入消息队列的顺序进行读取的。发布/订阅方式则是将消息广播给所有的消费者。Kafka提供了一种抽象的方式-消费者分组(consumer group)来满足消息的以上两种处理方式。
每个消费者都有一个组名,只有订阅的消费者在对应的组中时,发布到topic中的消息才会传递给消费者对象。消费者对象可以在不同的进程或主机中存在。
如果所有的消费者对象的组名都相同,这就好比是传统的顺序队列,消费者平均分配这些消息。
如果所有的消费者对象的组名都不相同,这就好比是发布/订阅模式,消费者只接受订阅的消息。
通常来说,订阅某一主题(topic)的消费者在同一组的有多个,这是为了系统的稳定和容错。下图是一个具体的示例。

Kafka比传统的消息队列拥有更高的排序可靠性。
传统的消息队列在顺序保存消息到服务器时,如果有多个消费者从队列中读取消息,服务器会顺序发送消息。但是,尽管服务器是顺序发送消息的,但是消费者是异步接收消息的,因此消费者接收到的消息可能并不是顺序的,但消费者并不知道消息是乱序的。为避免这种情况,传统的消息队列通常只允许一个进程读取消息,这也就意味着消息的处理是单向的,而不是并行的。
Kafka在这方面有更好的处理方式,它通过在主题中使用分区完成了并行处理。Kafka既保证了顺序输出又实现了消费者之间的平衡。通过给主题分配分区,将消息分给同组内的消费者,确保每一分区内的消费者是唯一的,并且是顺序读取消息。由于是通过分区来实现多个消费者对象的负载均衡,所以同一消费者组的消费者是不能超过分区的。
Kafka仅仅实现了消息在一个分区内的排序,而不是同一主题不同分区内的排序。对于大多数应用而言,数据分区和分区内数据排序就足够了。如果你想要所有的消息都是顺序排列的,那就只能有一个分区,这意味着只能有一个消费者在一个消费者组内。这种情况下,消息的处理就不是并行的。
可靠性
消息会以生产者发送的顺序追加到主题的分区。例如,一个生产者发送同一个消息两次分别称为M1,M2,M1先发,那么M1将会有一个更小的偏移量,并且也会比M2早出现在日志中。
消费者以存储在日志中的顺序看见消息。
对于复制N倍的主题,即便N-1台服务器出错,都不会使已经提交到日志的消息丢失
使用场景
消息代理
Kafka可以替代一些传统的消息代理。消息代理有很多使用场景,比如与数据处理程序解耦,缓存未处理的消息等等。和大多数消息处理系统相比,Kafka有更好的吞吐量,内建的分区,复制和容错能力,这使得Kafka能够很好的处理大规模消息应用。
活动追踪
Kafka最初用来提供实时追踪网站用户行为的相关数据的能力,例如统计PV,UV等。
监控统计
Kafka经常被用来操作监控数据,比如从分布式的应用中汇总统计数据。
日志收集
我们的服务通常部署在多台计算机上,服务器的运行日志也会分散打在各个机器上。Kafka通常被用来从各个服务器上收集日志,然后统一打到HDFS或者其他离线存储系统,比如Facebook的Scribe在收集日志时就是用了Kafka。
流处理
很多用户完成原始数据的阶段性汇总,加工等处理后,将操作结果转换为新的topic写入Kafka来进行更深入的处理。 比如,文章推荐程序完首先是用爬虫从RSS中爬取用户订阅的文本内容,然后把这些内容发布到articles topic下。接下来的处理程序,将articles topic下的内容格式化后,发布到format topic下。最终的处理程序尝试将这些格式化的内容推荐给合适的用户。Storm和Samze是处理这种业务的流行框架。
事件采集
业务状态的变化被按照时间顺序记录下来,这种程序设计方式被成为事件采集。Kafka支持大规模的日志数据存储,这使得Kafka成为事件采集程序理想的后端模块。