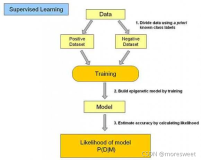
介绍一些深度学习中CV方面的一些常用的数据集:
(一)mnist手写字体数据集:
mnist数据是由Google实验室的Corinna Cortes和纽约大学柯朗研究所的YannLeCun建立的一个手写字体数据集,其中训练集包含60000训练的手写数字图片,测试集包含10000张图片,一个训练集的标签集,一个测试集的标签集。
官方地址:
http://yann.lecun.com/exdb/mnist/
数据集中图片为单通道,大小为28X28像素
训练集train-images.idx3-ubyte,文件大小47040016B,47040016=60000X28X28+16,
测试集t10k-images.idx3-ubyte,文件大小7840016B,7840016=10000X28X28+16,
其中图片数据集多出16字节为:
magic number = 0x00000803
Imagenumber = 0x0000ea60/60000 0x00002710/10000
Imageheight = 28
Imagewidth=28
标签文件中多出8个字节为magic number = 0x00000801 和image_number
这个数据集基本上已经被用烂了,基本上每一个学习的框架都会带有含mnist数据集的example,基本上正确率都能达到98%+,适合初学者上手。
2cifar-10数据集
cifar-10的姊妹数据集cifar-100
cifar-·10数据集由Alex Krizhevsky,Vinod Nair和Geoffrey Hinton收集,数据集包含6万张32X32的彩色图片,共分为10中类型,包含了5万张训练图片和1万张测试图片,10类图片分别为ariplane,automobile,bird,cat,deer,dog,frog,horse,ship,truck,其中不同的对象类间完全互斥。汽车和卡车类没有重叠。“Automobile”只包含sedans,SUVs等等。“Truck”只包含大卡车。两者都不包含皮卡车。
官方地址:
http://www.cs.toronto.edu/~kriz/cifar.html
cifar-100数据集是cifar-10数据集的升级版本,由60000张大小为32X32的三通道彩色图像组成,分为20大类;每个大类又包含5个小类,总共100个小类,每个小类包含600张图像,其中500张用于训练,100张用于测试。
3ImageNet数据集
ImageNet数据集中有1400万幅图像,涵盖了2万多个类别;其中有超过百万的图片有明确的类别标注和图像中物体位置的标注,具体信息如下:
1)Total number of non-empty synsets: 21841
2)Total number of images: 14,197,122
3)Number of images with bounding box annotations: 1,034,908
4)Number of synsets with SIFT features: 1000
5)Number of images with SIFT features: 1.2 million
与Imagenet数据集对应的是一个国际性的比赛——ImageNet国际计算机视觉挑战赛(ILSVRC,ImageNet Large Scale Visual Recognition Competition)
数据集大小:~1TB(ILSVRC2016比赛全部数据)
下载地址:
http://www.image-net.org/about-stats
其中有个1000类的分类问题,训练数据集有126万张图像,验证集5万张,测试集10万张,评价标准采用top-5错误率,即对一张图像进行5个类别的预测,只要其中一个和人工标注的类别相同则就算对了,否则算错。
4COCO数据集
COCO(Common Objects in Context)是一个新的图像识别、分割和图像语义数据集,包含以下特点:
1)Object segmentation
2)Recognition in Context
3)Multiple objects per image
4)More than 300,000 images
5)More than 2 Million instances
6)80 object categories
7)5 captions per image
8)Keypoints on 100,000 people
这个数据集以scene understanding为目标,主要从复杂的日常场景中截取,图像中的目标通过精确的segmentation进行位置的标定。图像包括91类目标,328,000图像和2,500,000个label。
一共有20G左右的图片和500M左右的标签文件
官网:
http://cocodataset.org/
关于COCO数据集的paper:
http://arxiv.org/abs/1405.0312
5 PASCAL VOC
PASCAL VOC挑战赛是视觉对象的分类识别和检测的一个基准测试,提供了检测算法和学习性能的标准图像注释数据集和标准的评估系统。PASCAL VOC图片集包括20个目录:人类;动物(鸟、猫、牛、狗、马、羊);交通工具(飞机、自行车、船、公共汽车、小轿车、摩托车、火车);室内(瓶子、椅子、餐桌、盆栽植物、沙发、电视)。PASCAL VOC挑战赛在2012年后便不再举办,但其数据集图像质量好,标注完备,非常适合用来测试算法性能。
其中:
所有的标注图片都有Detection需要的label, 但只有部分数据有Segmentation Label。
VOC2007中包含9963张标注过的图片, 由train/val/test三部分组成, 共标注出24,640个物体。
VOC2007的test数据label已经公布, 之后的没有公布(只有图片,没有label)。
对于检测任务,VOC2012的trainval/test包含08-11年的所有对应图片。 trainval有11540张图片共27450个物体。
对于分割任务, VOC2012的trainval包含07-11年的所有对应图片, test只包含08-11。trainval有 2913张图片共6929个物体。
PASCAL VOC数据集下载:
https://pjreddie.com/projects/pascal-voc-dataset-mirror/

6OpenImage数据集
OpenImage,由谷歌实验室出品,包含900 万张的链接图像(基本来自 flickr),横跨了大约 6000 个类别,这些标签比 ImageNet(1000 类) 包含更多贴近实际生活的实体。这么大量的图像数据,足够保证从头训练一个深度网络模型。
数据集的 Github 地址为:https://github.com/openimages/dataset
博客对数据集进行了详细的介绍:
http://blog.csdn.net/u010167269/article/details/52717394
7行人数据集:
MIT数据集:
该数据库为较早公开的行人数据库,共924张行人图片(ppm格式,宽高为64x128),肩到脚的距离约80象素。该数据库只含正面和背面两个视角,无负样本,未区分训练集和测试集。Dalal等采用“HOG+SVM”,在该数据库上的检测准确率接近100%。