摘要:在2018年1月25日的数据库直播上由阿里云HBase team的玄陵带来了以“ApsaraDB-HBase双集群和稳定性”为主题的分享,通过对云HBase双集群方案存在的必要性、常见跨集群数据复制方案、云HBase跨集群数据复制(增量/全量)、云HBase双集群方案选择以及云HBase服务的稳定性进行了详细的介绍。
直播视频:https://yq.aliyun.com/video/play/1333
PPT下载:https://yq.aliyun.com/download/2460
以下内容为精彩视频整理:
云HBase双集群方案的必要性
介绍一下服务做双集群的必要性,双集群常见于一些在线服务,因为对于在线服务来说对服务可用性更敏感,且对数据可靠性要求更高,双集群的灾备或者说一个多活的方案为在线服务提供了更优的服务稳定性。当检测到Master集群不可用才可以把流量切换到备份集群,这就是一个灾备。同时也可以做主备的集群的流量分切等,把主备的资源都利用起来。在线集群如果由于主集群挂了或者部分时间不可用,如果有backup,那么可以瞬间流量切到备份,提高服务可用性。离线服务可能对可用性不是这么敏感,挂了一段时间再继续服务,可能离线服务根本不care。
常见跨集群数据复制方案
接下来先介绍一下数据复制这一模块,常见的解决方案以及它的原理。这一模块它会涉及到增量复制以及全量复制,先来介绍一下增量复制常见的一些解决方案,大概归纳为下面几个方面:
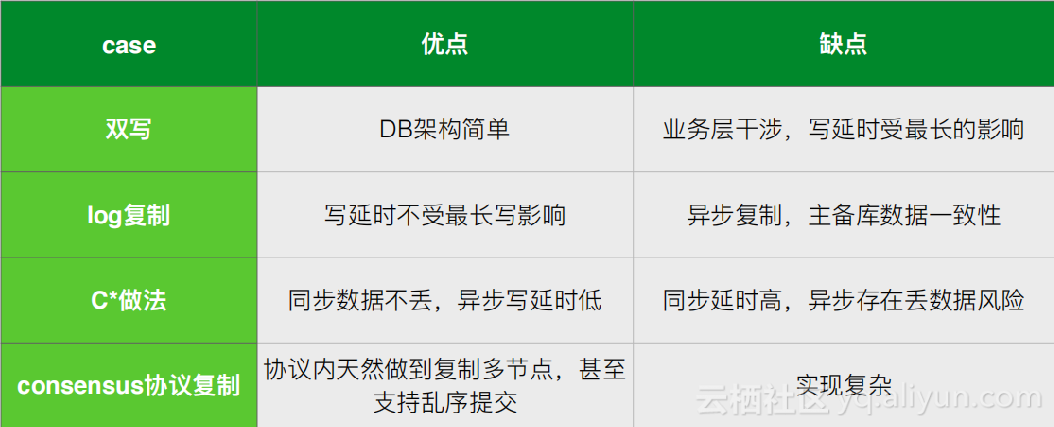
1.双写:现在有两个集群Master和Slave,在业务层做双写的服务,把流量在主集群写一份,备份集群写一份,任何一条写请求过来的话,可以保证在主集群Master上和备份集群Slave上都写成功后,这次写才是成功的。当发现主集群挂掉了,可以把流量倒到备份集群上;
2.复制log:在增量复制的时候要先复制log,比方一个主库一个备库,先把写流量打到主库,备库做解析。常见的有mysqul复制binlog、mongo复制oplog、HBase复制WALlog;
3.EACH_QUORUM/LOCAL_QUORUM:同过C*cross dc back up方案;
4.Consentsus协议复制:Consentsus是做内部的数据同步;
5.其它;
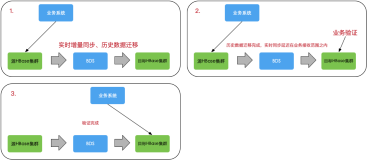
全量复制大概有下面几个方面:
(1)批量跑Map Reduce导数据(copytable);
(2)Copy file+bulkload,从文件级别copy到备份集群,bulkload是直接从数据文件把数据load起来,最终在内存里面以及在物理磁盘上可能会有新增的索引文件;
(3)数据库自身方案:云HBase有一套一键迁移工具和C*rebuild工具;
全面复制的特点如下:
云HBase一键迁移工具可以做到表级别的复制,使用起来比较快捷,可以做到容错和灾备,还可以在线的调整它的速度。
除此之外还有一个Distcp的功能,它就是copy file+bulkload,但单机bulkload资源消耗的比较严重,影响在线的备份速度。
Copy table是在源端做一个scan请求,对在线的源端大量的scan是影响它的内存、以及影响它的在线请求。
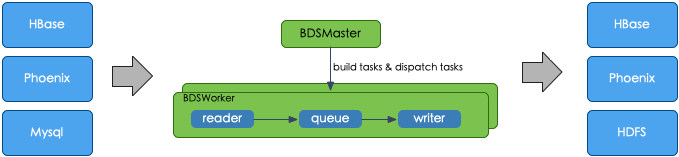
云HBase 跨集群数据增量复制
对云HBase 做replication我们也会提供异步复制,异步复制和社区相比会有一些优点,下面从这几方面介绍一下它的优点:
(1)提升源端发送效率:在复制HLog这一流程的时候,是对HLog进行的一个串行的读取。
让源端发送的过程进行多线程并发的操作,这样对发送的效率有所提高,进而对接收效率也进行提高;
(2)提升目标端Sink的效率:源端预合并HLog,目标端进行并行化消费;
(3)热点辅助:进行基于历史监控的负载均衡算法均衡请求,进行人工运维;
这是我们在原有异步复制上面的一个优化,除此之外我们还做了一个基于云HBase同步replication,因为原来的replication是异步的,所以就HBase这个版本除此之外它还有一个同步的replication分量复制。

同步复制是发一条请求在本地先写WALlog,同时并发在备份Cluster上写一条RemoteLog,在本地写memstore。同时在下面主备之间的Log复制逻辑用的是原来的异步复制逻辑。当我现主集群挂了,把流量切到备份集群,这时备份集群自己要做一个恢复,恢复的时候就需要在RemoteLog上做一个同步的恢复。RemoteLog并不会一直存在,当发现主集群的Log异步复制备份之后,就可以把RemoteLog删掉了。
下面总结一下云HBase在增量复制这一块的优点,
(1)支持强同步复制:保证主备集群写入强一致同步,一旦主集群挂掉了,可以在备份上读到最全的数据;
(2)对同步和异步做到了同存:同步复制表不影响异步复制表的读写;
(3)灵活切换模式:当主集群挂了或者异步集群挂了,同步复制可以一键切换为异步复制,不阻塞主集群写入;
(4)高性能复制:复制性能比社区是高一倍的,尽可能的并行化处理;
云HBase双集群方案选择
对于在线服务会有灾备的需求,也可能会有双活的需求常见的方案有业务层做一些切换以及重试、consensus协议保证、云HBase:DB层面做灾备/双活,业务无感知。
介绍一下之前做双集群方案的调研。
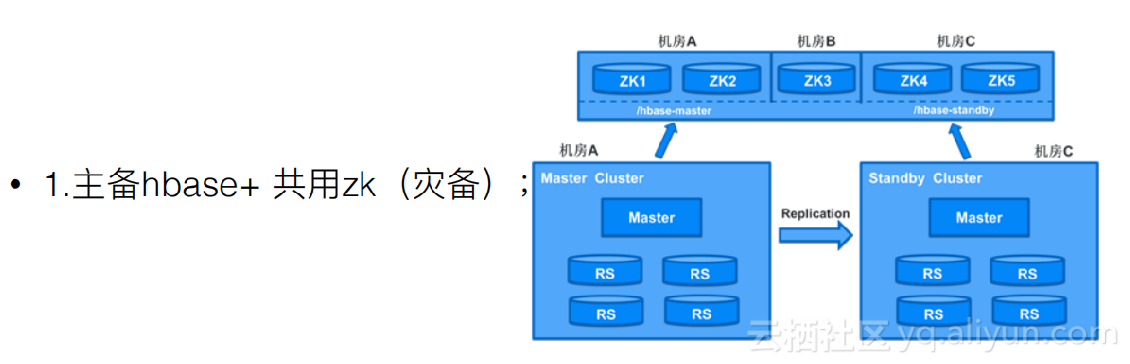
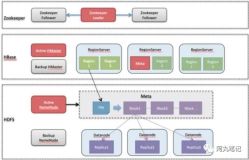
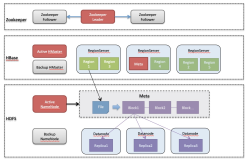
第一种是有主备的hbase,主备集群可以共用一套Zk,在Zk里面丢上主集群的地址和备集群的地址。当发现主集群是挂掉了,可以人工的在Zk里把地址做一个替换,请求就会直接访问备份集群不会访问主集群。它的优点是架构比较简单,缺点是一旦Zk挂掉之后,主备集群就会完全无法工作。
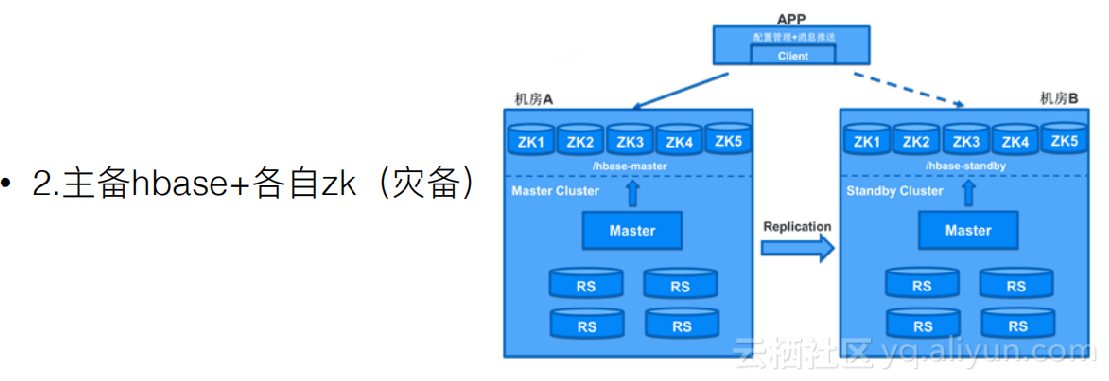
第二种方案是主备hbase和各自的Zk,这个的好处是不会依赖于共有的Zk,Zk不会成为致命点。但在配置管理+消息推送这会有一个配置管理的工具,它专门的去存储地址。

第三种就是我们自己的主备hbase+client retry,大部分逻辑是丢在client层面,在client上做一些判断。还有智能的不可服务的诊断系统,当发现主机不可服务后会在网络层面把这个事做一个锁定,Client层面感知到这个锁定后会把流量自动的切到备份。对于put/get/delete/batch多样化的复制,来一个put请求丢到主机里复制备份,当client层面发现主集群不可服务了,client自己会把流量切到备份。Client也有方毛刺抖动的预防功能和云HBase异步复制的功能。
我们之所以选择第三种方案,因为在云上的环境比较复杂,而方案一、二都需要依赖其他的组件,如果再在云上加一个组件整个流程是比较复杂的,所以我们选择了一个最简单的方案,后期还可以在client层面做一些策略的路由,这样可以支持后续多活的延续。
云HBase服务稳定性
双集群的稳定性,现在购买双集群实现的逻辑是在同region下,不同的Az和相同的Az都是可以支持服务的,这样可以防止区域性外界原因造成的服务不可用问题。出现单集群某些机器出现OOM问题可以把风险降到很低,不影响整体服务可用性。除此之外后续还会有一个双活的规划,后续支持可配策略的访问模式,主备异构。
本文由云栖志愿者小组陈欢整理,百见编辑。