在看“多元线性回归”(multivariate linear regression)的时候又碰到了矩阵求导,决心把矩阵求导学一学了,网上搜了一些,也看了一下维基,简单整理一下,以后再碰到矩阵求导就方便查看了d=====( ̄▽ ̄*)b
矩阵求导,没什么可怕的,无非就是 一个矩阵里的元素对另一个矩阵里的元素进行求导,只是符合一些规则而已。
和朋友的白水东城博客链接-矩阵求导总结
先从简单的来说(⊙ ▽ ⊙)
向量(矩阵的特例)对一个标量进行求导,就是向量的每个元素对这个标量进行求导,结果可以定为行向量也可定为列向量(这个牵扯到后文要提到的分布)
标量对一个向量求导,就是标量分别对这个向量的每个元素求导,结果也一样,可以为行向量也可以为列向量。
维基上提到了一个布局(layout)的定义,大概意思是这样的:
分子布局(Numerator layout):分子为y或者分母为xT(即分子为列向量或者分母为行向量)
分母布局(Denominator layout):分子为yT或者分母为x(即分子为行向量或者分母为列向量)
注:对于矩阵也是一样的,可以这样理解,(列)矩阵和(行)矩阵分别对应着列向量和行向量(如果现在这句话不能理解,不妨完下文的分布记法再来想想这句话的意思)。
用一个例子来解释一下这两个布局的区别和作用:
用∂→y∂→x为例,假设→x和→y都是列向量,那么分子布局的意思就是∂→y∂→xT,分母布局就是∂→yT∂→x。这样就有明显的区分了,分子布局可以看做是求偏导的分子项保持不变,而分母项则需要转置,而分母布局正好相反。
再举个例子:
向量→y=(y1y2⋯ym)T对标量x的偏导,如下:
∂→y∂x=(∂y1∂x∂y2∂x⋯∂ym∂x)T
标量y对向量→x=(x1x2⋯xn)T求偏导,如下:
∂y∂→x=(∂y∂x1∂y∂x2⋯∂y∂xn)
第一个例子,结果还是列向量,但在第二个例子中结果却变成了行向量。注意这些都是分子布局的形式,如果换成是分母布局,那就要将上面的结果都转置过来才行(这也是之前所说的为什么有些资料上会把矩阵对标量的求导需要转置的原因)。同理,分子布局中向量→y=(y1y2⋯ym)T对向量→x=(x1x2⋯xn)T求偏导的结果:∂→y∂→x=[∂y1∂x1∂y1∂x2⋯∂y1∂xn∂y2∂x1∂y2∂x2⋯∂y2∂xn⋮⋮⋱⋮∂ym∂x1∂ym∂x2⋯∂ym∂xn]
这就是著名的雅可比(Jacobian)矩阵。同样的,如果在分母布局中结果就是雅可比矩阵的转置。
又比如,对于分子布局一个m×n行的矩阵Y对于标量x求导的结果: ∂Y∂x=[∂y11∂x∂y12∂x⋯∂y1n∂x∂y21∂x∂y22∂x⋯∂y2n∂x⋮⋮⋱⋮∂ym1∂x∂ym2∂x⋯∂ymn∂x]
而标量y对矩阵X的求导结果:∂y∂X=[∂y∂x11∂y∂x21⋯∂y∂xm1∂y∂x12∂y∂x22⋯∂y∂xm2⋮⋮⋱⋮∂y∂x1n∂y∂x2n⋯∂y∂xmn]
我们根据经验(虽然这里不是列向量和行向量,但可以这么记忆),分母布局就是 上述结果的转置形式。
可能会疑惑,为啥要这样区分呢?
由于我们一般将向量默许为行向量或列向量,而这两种形式都客观存在,也没有孰优孰劣。
所以在看一些数学公式 的推导中,比如求矩阵对标量的倒数,直觉上是觉得是矩阵的每个元素对标量求导,但却有时候要进行转置,原因就是因为矩阵求导的两种分布了。
下面整理了一些维基上这两个分布的各自记法以及求导的参照表格。
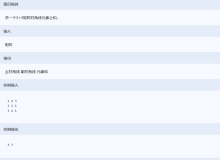
维基上的矩阵求导参照表格
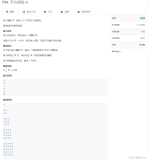
分子布局记法(Numerator-layout notation)
- 标量/行向量:

- 列向量/标量:

- 列向量/行向量:

- 标量/矩阵:

下面是分子布局中的特例:
- 矩阵/标量:

- 对矩阵(X)每个元素求导:

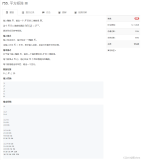
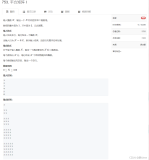
分母布局标记(Denominator-layout notation)
- 标量/列向量:

- 行向量/标量:

- 行向量/列向量:

- 标量/矩阵:

好了,知道啥叫分子布局和分母布局了,然后对于要求导的式子,就可以对照着快速查阅下面的表格了= ̄ω ̄=
1.向量—向量 Vector-by-vector identities
所谓的向量的计算,就是矩阵计算中最简单的一种,是把矩阵的行向量设为1的情况.
2.标量—向量 Scalar-by-vector identities
其实只要在上面的“向量—向量”运算中把分子或分母中的向量该称标量就得到“标量—向量”了。

3.向量—标量 Vector-by-scalar identities
4.标量—矩阵 Scalar-by-matrix identities
5.矩阵—标量 Matrix-by-scalar identities
6.标量—标量 Scalar-by-scalar identities
就当复习

其实,这些求导的表格需要记忆,只要在遇到求导的地方对照着查阅一下就OK了。
最后,来解决我遇到的矩阵求导:∂(y−Xw)T(y−Xw)∂w
注:ω是(d+1)×1的列向量,X是m×(d+1)的矩阵,y是m×1的列向量.
首先,将式子展开:∂(yTy−yTXw−wTXTy+wTXTXw)∂w ⇒ ∂yTy∂w−∂yTXw∂w−∂wTXTy∂w+∂wTXTXw∂w
分别对每一项求导:
- ∂yTy∂w:∂yTy∂w=0
解释:分子为标量,分母为向量。找到上文2.标量—向量表格中的第一行

又因为分母是列向量,所以是分母布局,结果为0.
- ∂yTXw∂w:∂yTXw∂w=XTy
解释:分子为标量,分母为列向量。找到2.标量—向量表格中第11行

又因为分母是列向量,所以结果对应为分母布局,应该是第二个XTy.
- ∂wTXTy∂w:∂wTXTy∂w=∂(wTXTy)T∂w=∂yTXw∂w=XTy
解释:分子为标量,分母为向量。因为ωTXTy是标量,而标量的转置还是等于本身,所以进行转置后再查表,和上一条一样。(为啥要转置?因为表格中没有一模一样的啊(o_ _)ノ)
- ∂wTXTXw∂w:∂wTXTXw∂w=2XTXw
解释:分子为标量,分母为向量。在2.标量—向量表格中第13行找到
注:(行向量(1×(d+1))×矩阵((d+1)×(m))× 矩阵(m×(d+1))×列向量((d+1)×1=标量)
又因为分母为列向量,所以符合分母布局,选第二个,结果为2XTXw.
最终,我们得到结果:∂yTy∂w−∂yTXw∂w−∂wTXTy∂w+∂wTXTXw∂w=0−XTy−XTy+2XTXw=2XT(Xw−y)
令上式结果为零,不考虑矩阵逆的计算等,简单的可以得到:ω=(XTX)−1XTy
哈哈哈,以后再也不怕矩阵求导了( •̀ ω •́ )y