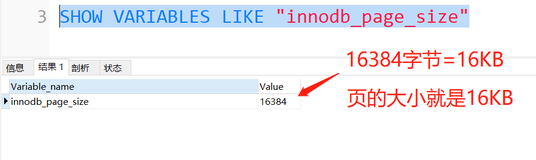
——————————————————–
ha_innobase::write_row是向innodb写入记录的函数,进入函数时自增列的值还没被设置(如何是NULL的话),会调用handler::update_auto_increment来获取并更新自增列,然后再调用row_insert_for_mysql来实际插入记录。我们的精力主要集中在update_auto_increment及其调用的函数上。
先了解下handler的几个跟自增列相关的成员变量(根据注释及gdb推测):
a. ulonglong next_insert_id;
下一个插入自增列的值,当一次插入多行记录时(例如,insert select 操作),第一个没有指定自增列值的记录会从get_auto_increment函数获取的值并赋值给next_insert_id,这样对于剩下的记录就可以直接使用next_insert_id(每次都修改该值)。
b. ulonglong insert_id_for_cur_row;
当前记录的insert id 。第一次成功插入后,这个值被存储到THD::first_successful_insert_id_in_cur_stmt
c. Discrete_interval auto_inc_interval_for_cur_row;
从get_auto_increment函数获取的insert id区间。
Discrete_interval 结构体又包含三个值
interval_min 区间的最小值
interval_values 区间内可用自增值的个数
interval_max 最大值
d. uint auto_inc_intervals_count;
当前插入语句保留的自增区间数
e. estimation_rows_to_insert
估计将要插入的记录数,在函数handler::ha_start_bulk_insert()中被设置,值为0表示未知。
//////////////////////////////////////////////////////////////////////////////////////////////////////
下面来分析下handler::update_auto_increment主要流程
1.首先判断自增列是否已经赋值,或者是否不可以为NULL&&sql_mode为MODE_NO_AUTO_VALUE_ON_ZERO时,不做处理
if ((nr= table->next_number_field->val_int()) != 0 ||
(table->auto_increment_field_not_null &&
thd->variables.sql_mode & MODE_NO_AUTO_VALUE_ON_ZERO)){
handler::adjust_next_insert_id_after_explicit_value // 根据nr和offset设置下一个自增值next_insert_id
insert_id_for_cur_row= 0;
DBUG_RETURN(0);
}
2.当预取的insert id区间用完时,需要取更多的insert id。
if ((nr= next_insert_id) >= auto_inc_interval_for_cur_row.maximum())
{
a.如果预取了下一个区间,则使用下一个区间的server id。
nr= forced->minimum();
nb_reserved_values= forced->values();
b.否则:
(1)确定需要自增值的数目(nb_desired_values)
当没有预留值,且估值大于0时(auto_inc_intervals_count == 0) && (estimation_rows_to_insert > 0),设置nb_desired_values=estimation_rows_to_insert
否则: (例如insert into t values (NULL,12),(98,51),(NULL,67),第3个记录会走到这个逻辑)
–auto_inc_intervals_count <= AUTO_INC_DEFAULT_NB_MAX_BITS时
nb_desired_values= AUTO_INC_DEFAULT_NB_ROWS *
(1 << auto_inc_intervals_count);
set_if_smaller(nb_desired_values, AUTO_INC_DEFAULT_NB_MAX);
nb_desired_values值为1*(1<< auto_inc_intervals_count)且不大于AUTO_INC_DEFAULT_NB_MAX(65535)
–auto_inc_intervals_count> AUTO_INC_DEFAULT_NB_MAX_BITS时
nb_desired_values值为最大值65535
实际上,对于innodb而言,请求的数量可能跟实际获得的自增值数量不同,这取决于trx->n_autoinc_rows
每写完一次记录后, trx->n_autoinc_rows 会被减1(在函数ha_innobase::write_row 中)
例如,对于SQL:INSERT INTO T VALUES (NULL,12),(98,51),(NULL,67),(120,44),(NULL,123);
假设当前值为90
第一次调用update_auto_increment时,请求保留5个值
trx->n_autoinc_rows=5,保留5个值
{interval_min = 90, interval_values = 5, interval_max = 95, next = 0x0}
第二次调用update_auto_increment时,使用98
trx->n_autoinc_rows=4
第三次调用update_auto_increment时,请求保留2个值
trx->n_autoinc_rows=3, 保留3个值
{interval_min = 99, interval_values = 3, interval_max = 102, next = 0x0}
prebuilt->trx->n_autoinc_rows
第四次调用update_auto_increment时,使用120
trx->n_autoinc_rows==2
第五次调用update_auto_increment时,请求保留4个值
trx->n_autoinc_rows=1,保留1个值
{interval_min = 121, interval_values = 1, interval_max = 122, next = 0x0}
(2)调用ha_innobase::get_auto_increment获取自增区间,更新table->autoinc (函数后续详解)
(3)nr= compute_next_insert_id(nr-1, variables); 根据offset等配置项计算nr
(4)当(table->s->next_number_keypart == 0时,设置append=true
}
3.table->next_number_field->store((longlong) nr, TRUE)
4.append为true时(为false表示使用的是之前预取的值,无需执行如下步骤)
设置当前auto_inc_interval_for_cur_row
auto_inc_intervals_count++
如果为statement模式,则记录该自增值到binlog
5.insert_id_for_cur_row= nr
6.set_next_insert_id(compute_next_insert_id(nr, variables)); 设置next_insert_id的值
///////////////////////////////////////////////////////////////////////////////////////////////////
ha_innobase::get_auto_increment是实际分配自增值的主要函数。流程如下:
1.调用函数innobase_get_autoinc
a.
ha_innobase::innobase_lock_autoinc
根据不同的autoinc_lock_mode选择加锁模式,我们的环境下这个值都是1,因此选择的case是AUTOINC_NEW_STYLE_LOCKING
注意,以load 或者 insert ..select的方式插入数据时会回退到AUTOINC_OLD_STYLE_LOCKING
dict_table_autoinc_lock->mutex_enter(&table->autoinc_mutex); //获取autoinc mutex
再判断是否有别的事务已经获取或在等待autoinc Lock,如果是的话,解除Mutex并回退到AUTOINC_OLD_STYLE_LOCKING,否则break,并返回。
在OLD STYLE LOCKING模式下,调用row_lock_table_autoinc_for_mysql加AUTO_INC LOCK(调用lock_table函数加LOCK_AUTO_INC锁),随后如果成功了,再调用dict_table_autoinc_lock(prebuilt->table)加autoinc mutex
在lock_table->lock_table_create函数里会对table->n_waiting_or_granted_auto_inc_locks++
b.
调用dict_table_autoinc_read(prebuilt->table)获取table->autoinc值
2.
如果tx->n_autoinc_row=0,设置该值为nb_desired_values或者1(如果nb_desired_values=0),然后set_if_bigger(*first_value, autoinc),将first_value设置为当前的table->autoinc值
如果prebuilt->autoinc_last_value == 0,也就是不在一次muti-insert的中间,也设置set_if_bigger(*first_value, autoinc)
*nb_reserved_values = trx->n_autoinc_rows;
3.当不是使用AUTOINC_OLD_STYLE_LOCKING时
a.计算当前值current和需要保留的区间长度need
b.调用next_value = innobase_next_autoinc函数计算保留区间的最后一个值 (bug#61209 fix点)
c.prebuilt->autoinc_last_value = next_value
d.更新table->autoinc的值(dict_table_autoinc_update_if_greater)
4.
prebuilt->autoinc_offset = offset;
prebuilt->autoinc_increment = increment;
dict_table_autoinc_unlock(prebuilt->table)->mutex_exit(&table->autoinc_mutex); //解除mutex