下面以SQLServer2000和Analysis Service为例,并结合以前的项目经验,把相关的知识和大家一起分享探讨!在公司时用英文写的,懒得做翻译了!
Data Warehouse Concept
A data warehouse is a subject-oriented, integrated, nonvolatile, time-variant collection of data designed to support management DSS needs.
1、Subject-Oriented
Subject-Oriented data is organized around major subject areas of an enterprise and is useful for an enterprise-wide understanding of those subjects. For Example, a banking operational system maintains independent records of customer savings, loans, and other transactions. A warehouse pulls this independent data together to provide financial information.
The data from diverse sources is transformed so that it is consistent and meaningful for the warehouse.
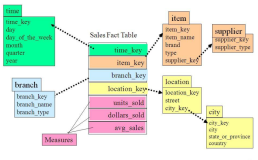
So the main work is around the fact table.
1.1 Original data from data source
1.2 Dimension
1.3 Measurement
1.4 dimension granularity
1.5 Star model or snowflake model
1.6 OLAP model
The data from diverse sources is transformed so that it is consistent and meaningful for the warehouse.
So the main work is around the fact table.
1.1 Original data from data source
1.2 Dimension
1.3 Measurement
1.4 dimension granularity
1.5 Star model or snowflake model
1.6 OLAP model
2、Integrated
Data on a given subject is integrated.
In many organizations, data resides in diverse independent systems, making it difficult to integrate the information into a single set of meaningful data from analysis. A key characteristic of a warehouse is that data is completely consolidated or integrated. Data is structured in a globally accepted manner, even when the underlying source data is structured differently (conforming dimension). Integration and transformation processes can be time-consuming and costly. It requires commitment from every part of the organization, particularly top-level managers who make the decisions and allocate resources and funds.
So the main work may be like :
2.1 Universal dimension from different department.
2.2 Dimension design include NULL value or violate constraint
2.3 Define mid-exchange table 2.4 But we didn’t control the data quality caused by man-made
In many organizations, data resides in diverse independent systems, making it difficult to integrate the information into a single set of meaningful data from analysis. A key characteristic of a warehouse is that data is completely consolidated or integrated. Data is structured in a globally accepted manner, even when the underlying source data is structured differently (conforming dimension). Integration and transformation processes can be time-consuming and costly. It requires commitment from every part of the organization, particularly top-level managers who make the decisions and allocate resources and funds.
So the main work may be like :
2.1 Universal dimension from different department.
2.2 Dimension design include NULL value or violate constraint
2.3 Define mid-exchange table 2.4 But we didn’t control the data quality caused by man-made
3、Nonvolatile
Typically, data in the data warehouse is read-only (less volatile than operational systems). Data is loaded into the data warehouse for the first-time load, and then refreshed regularly. Warehouse data is accessed by business users. Warehouse operations typically involve:
Loading the initial set of warehouse data (often called the first-time load)
Refreshing the data regularly (called the refresh cycle)
So the main work is around:
3.1 DTS design and schedule
3.2 The dimension data is incremental, it is to say that they can be inserted and updated, but can’t be deleted. And dimension data must be unique.
3.3 The original or fact data is incremental, but according to requirement, it can be updated or deleted under the control. The full process is danger and impossible when the data volume is too huge.
Loading the initial set of warehouse data (often called the first-time load)
Refreshing the data regularly (called the refresh cycle)
So the main work is around:
3.1 DTS design and schedule
3.2 The dimension data is incremental, it is to say that they can be inserted and updated, but can’t be deleted. And dimension data must be unique.
3.3 The original or fact data is incremental, but according to requirement, it can be updated or deleted under the control. The full process is danger and impossible when the data volume is too huge.
4、Time-Variant
Warehouse data is by nature historical; data is retained for a long time, from two to ten years, compared with one to three months of data for a typical operational system. The data allows for analysis of past and present trends, and for forecasting, using what-if scenarios.
Base the Time-Variant and data volume, we must consider :
4.1 The design about the database 4.2 The design about the table
4.3 The OLAP increment
Base the Time-Variant and data volume, we must consider :
4.1 The design about the database 4.2 The design about the table
4.3 The OLAP increment
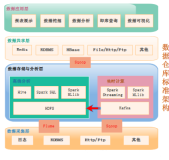
数据库设计,主要针对SQLServer2000而言,包括以下方面:
数据库设计
文件组设计
历史数据表和当前数据表设计
分区表设计
数据库链接使用
日志表
增量数据抽取
维度数据抽取
原始数据抽取
日结数据处理
OLAP的增量处理和分区
数据库调优
文件组设计
历史数据表和当前数据表设计
分区表设计
数据库链接使用
日志表
增量数据抽取
维度数据抽取
原始数据抽取
日结数据处理
OLAP的增量处理和分区
数据库调优
数据库设计
数据库一般的分类方式有:
按照业务来分(财务系统和销售系统)
按照处理阶段来分(原始数据和日结数据)
按照数据存储时间来分(当前数据和历史数据)
按照业务来分(财务系统和销售系统)
按照处理阶段来分(原始数据和日结数据)
按照数据存储时间来分(当前数据和历史数据)
当然这些分类标准不是一成不变的也可以交叉分类,而且不同的关系数据库也不一致,如Oracle可以使用不同数据块大小的表空间存储不同数据,SQLServer和Sybase则采用不同的数据库实现对数据的存储。
建议数据库的分类按照不同的处理阶段进行数据存储,可以方便的进行数据库的备份和管理工作。如
dataware_org 存储ODS层数据,保留一定期限的原始数据
dataware_fact 存储日结数据,可以较长时间的保留系统数据。
dataware_dim 存储维度基础数据。
建议数据库的分类按照不同的处理阶段进行数据存储,可以方便的进行数据库的备份和管理工作。如
dataware_org 存储ODS层数据,保留一定期限的原始数据
dataware_fact 存储日结数据,可以较长时间的保留系统数据。
dataware_dim 存储维度基础数据。
待续........
关于文件组的设计
数据库可以按照以下几种情况进行文件组设计 ( 其实同上,关键如何分类更加合理 ) :
1 、按照业务数据来源分类
2 、按照 ETL 处理过程分类
3 、按照数据的存储周期分类 ( 历史数据还是临时数据 )
4 、按照数据的物理存储类型分类 ( 即索引还是数据 )
1 、按照业务数据来源分类
2 、按照 ETL 处理过程分类
3 、按照数据的存储周期分类 ( 历史数据还是临时数据 )
4 、按照数据的物理存储类型分类 ( 即索引还是数据 )
个人建议,采用按照物理存储类型和数据存储周期进行分库,如
历史数据文件组
临时表数据文件组
索引文件组
历史数据文件组
临时表数据文件组
索引文件组
关于历史数据和临时数据的分开处理
众所周知,对于大数据量的数据存储任何数据库都与遭遇性能瓶颈。
因此建议对于大数据量的表采取分表处理:即将数据区分为临时数据和历史数据分开存储
因此建议对于大数据量的表采取分表处理:即将数据区分为临时数据和历史数据分开存储
尽管可能会带来一些维护和处理上的不便,但是显而易见可以提升系统的性能。临时表中少量的数据可以有效地进行日结等处理,临时表数据需要进行定期地进行数据的转移工作。
还有一个更大的好处是,临时表和历史表放在不同的文件组或者数据库中,可以减少系统的 IO 冲突和备份周期的制定 .
还有一个更大的好处是,临时表和历史表放在不同的文件组或者数据库中,可以减少系统的 IO 冲突和备份周期的制定 .
关于分月表的问题
首先 SQLServer 在数据处理中存在性能问题,当一张表数据超过 1000 万以上时,其查询更新删除的效率显著降低,因此每个数据表的数据量要控制在一 定范围内;其次 SQLServer 不支持分区处理。但是 SQLServer2000 提供了一种类似分区的解决办法,采用分月表形式 ( 当然也可以按照其他分 类 )
即采用 UNION 的形式将各个相同表结构的表合并起来,作为一个完整的表来使用。当然这种视图仍存在一定的性能问题和限制 ( 以后会逐步发散开来 )
例如:
create view v_fact_table as
select * from t_fact_table_200601 union all
select * from t_fact_table_200602 union all
select * from t_fact_table_200603
每个月自动产生一张 t_fact_table_YYYYMM 数据表,然后动态更新 v_fact_table 视图。
例如:
create view v_fact_table as
select * from t_fact_table_200601 union all
select * from t_fact_table_200602 union all
select * from t_fact_table_200603
每个月自动产生一张 t_fact_table_YYYYMM 数据表,然后动态更新 v_fact_table 视图。
数据库链接
链接服务器配置允许 Microsoft® SQL Server™ 对其它服务器上的 OLE DB 数据源执行命令。链接服务器具有以下优点:
远程服务器访问。
对整个企业内的异类数据源执行分布式查询、更新、命令和事务的能力。
能够以相似的方式确定不同的数据源。
链接服务器有以下两种形式:
SELECT * FROM LinkedDatabase..usename.table
SELECT * FROM OPENQUERY(LinkedDatabase, 'SELECT * FROM table')
两种各有优缺点
第一种写法更加清晰,但有时候受限制比较多
第二种写法更加通用一些,甚至可以执行远程存储过程
链接服务器配置允许 Microsoft® SQL Server™ 对其它服务器上的 OLE DB 数据源执行命令。链接服务器具有以下优点:
远程服务器访问。
对整个企业内的异类数据源执行分布式查询、更新、命令和事务的能力。
能够以相似的方式确定不同的数据源。
链接服务器有以下两种形式:
SELECT * FROM LinkedDatabase..usename.table
SELECT * FROM OPENQUERY(LinkedDatabase, 'SELECT * FROM table')
两种各有优缺点
第一种写法更加清晰,但有时候受限制比较多
第二种写法更加通用一些,甚至可以执行远程存储过程
关于控制表和日志表
1 、监控维度数据的抽取和完成状态
2 、监控原始业务数据的抽取和完成状态 ( 包括时间点增量幅度的控制 )
3 、监控事实数据的运行和处理状态 ( 包括时间点增量幅度的控制 )
4 、监控 OLAP 增量处理的状态和时间点
ETL 部分 —— 关于维度抽取
1 、监控维度数据的抽取和完成状态
2 、监控原始业务数据的抽取和完成状态 ( 包括时间点增量幅度的控制 )
3 、监控事实数据的运行和处理状态 ( 包括时间点增量幅度的控制 )
4 、监控 OLAP 增量处理的状态和时间点
ETL 部分 —— 关于维度抽取
1 、普通维度的抽取和处理
2 、父子维度的抽取和处理
3 、雪花维度的抽取和处理
2 、父子维度的抽取和处理
3 、雪花维度的抽取和处理
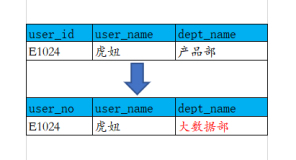
关于维度的处理方式,主要包括三种方法
1 、完全覆盖法,即只保留最后一次更新的记录
2 、全历史记录法,即采用替代键的方式对每次发生变更的记录进行记录,同时对此次业务数据的相应维度进行替换。
3 、记录最新纪录及上一次历史,即只保留当前和上次的更新记录,前两种的这种策略。
1 、完全覆盖法,即只保留最后一次更新的记录
2 、全历史记录法,即采用替代键的方式对每次发生变更的记录进行记录,同时对此次业务数据的相应维度进行替换。
3 、记录最新纪录及上一次历史,即只保留当前和上次的更新记录,前两种的这种策略。
通常情况下,对于维度不敏感的情况下采用第一种方式比较简单易行
第二种方法则相对比较复杂,对于系统处理的要求也比较高
第二种方法则相对比较复杂,对于系统处理的要求也比较高
ETL 部分 —— 关于原始业务数据抽取
主要是采取增量抽取的方式,此外还要考虑抽取对原业务系统的性能影响
通常的处理原则
减少每次数据抽取的时间和事务的大小,减轻数据抽取时对业务系统的性能影响。
减少每次数据抽取的时间和事务的大小,减轻数据抽取时对业务系统的性能影响。
ETL 部分 —— 关于数据日结的处理
主要是采取增量处理的方式,此外还要考虑处理时对系统性能的影响
通常的处理原则
First get begin time from fact table or original table
Then get end time from original table, it need to be under the control by loglimit
Loop between the begin time and end time
Modify the log table status
First get begin time from fact table or original table
Then get end time from original table, it need to be under the control by loglimit
Loop between the begin time and end time
Modify the log table status
OLAP 的设计和处理
通常情况下对于大数据量的 CUBE 采用分区形式
对于 CUBE 处理而言,通常情况采用脚本形式,以方便数据的增量处理和 CUBE 分区的融合
对于 CUBE 处理而言,通常情况采用脚本形式,以方便数据的增量处理和 CUBE 分区的融合
分区和增量的主要原因
全量数据刷新对系统性能影响很大
可以对分区进行局部处理,而不影响整个 CUBE
全量数据刷新对系统性能影响很大
可以对分区进行局部处理,而不影响整个 CUBE
关于数据仓库性能的优化主要包括:
1 、定期进行数据的转移和清除工作
2 、定期实现对数据库日志的收缩,尤其是大事务的处理之后
3 、定期进行数据库索引的重建工作。
2 、定期实现对数据库日志的收缩,尤其是大事务的处理之后
3 、定期进行数据库索引的重建工作。
监控:
定期通过 Performance 性能监视器收集数据库服务器的 CPU ,内存,硬盘统计信息
定期分析 DTS 的日志信息
定期分析 Windows 的日志信息
定期通过 Performance 性能监视器收集数据库服务器的 CPU ,内存,硬盘统计信息
定期分析 DTS 的日志信息
定期分析 Windows 的日志信息
关于备份
OLAP 的备份
OLAP 是采用独占式处理方式的,备份时不允许 CUBE 的处理,因此要合理的进行 OLAP 的备份和数据处理的关系。
OLAP 是采用独占式处理方式的,备份时不允许 CUBE 的处理,因此要合理的进行 OLAP 的备份和数据处理的关系。
脚本:
@echo off
rem save database,
rem switch to the path of backup command
e:
cd e:Microsoft Analysis ServicesBin
msmdarch /a 机器名 "c:MSSQLCUBE" "BIOLAP" "F:BIBACKUPCUBEBIOLAP.CAB"
备份工作由 Windows 操作系统进行调度或者 SQLServer 均可
@echo off
rem save database,
rem switch to the path of backup command
e:
cd e:Microsoft Analysis ServicesBin
msmdarch /a 机器名 "c:MSSQLCUBE" "BIOLAP" "F:BIBACKUPCUBEBIOLAP.CAB"
备份工作由 Windows 操作系统进行调度或者 SQLServer 均可
关于数据库的备份
数据库的备份也会影响系统的正常运行,因此也需要进行合理的调度工作任务
备份的策略建议是
1 、 2 、 3 、 4 、 5 、 6 采用增量备份
7 采用全量备份
数据库的备份也会影响系统的正常运行,因此也需要进行合理的调度工作任务
备份的策略建议是
1 、 2 、 3 、 4 、 5 、 6 采用增量备份
7 采用全量备份
没心事好好整理,其实可以扩展的东西很多......
本文转自baoqiangwang51CTO博客,原文链接:http://blog.51cto.com/baoqiangwang/310386
,如需转载请自行联系原作者