引言
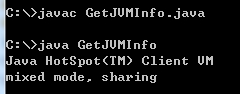
曾几何时,我也敲打过无数次这样的命令:

然而之前的我都只关心过版本号,也就是第一行的内容。今天,我们就来看看第3行输出的内容:JVM的类型和工作模式。
其实说Server和Client是JVM的两种工作模式是不准确的,因为它们就是不同的虚拟机,因此应该说有两种类型的JVM。
第三行的输出中可以看到:JVM的名字(HotSpot)、类型(Client)和build ID(24.79-b02) 。除此之外,我们还知道JVM以混合模式(mixed mode)在运行,这是HotSpot默认的运行模式,意味着JVM在运行时可以动态的把字节码编译为本地代码。我们也可以看到类数据共享(class data sharing)是开启(即第三行最后的sharing)的。类数据共享(class data sharing)是一种在只读缓存(在jsa文件中,”Java Shared Archive”)中存储JRE的系统类,被所有Java进程的类加载器用来当做共享资源,它可能在经常从jar文档中读所有的类数据的情况下显示出性能优势。
JVM的类型
通过百度搜索,只能搜到几篇被重复转载的文章。比如这一篇,这里面基本描述了两种类型的JVM的区别:
-Server VM启动时,速度较慢,但是一旦运行起来后,性能将会有很大的提升。
但我认为仅仅知道这些区别还不够。然而,我在百度的搜索结果中很少看见有描述的比较深入的关于JVM类型和模式区别的文章。不过我倒是找到了这一篇文章。 这篇文章中提到了如下内容:
当虚拟机运行在-client模式的时候,使用的是一个代号为C1的轻量级编译器, 而-server模式启动的虚拟机采用相对重量级,代号为C2的编译器. C2比C1编译器编译的相对彻底,,服务起来之后,性能更高.
对于这个结果,我觉得还是不够深入。于是FQ通过Google搜索,前几条即为我想要的结果。
两种类型JVM的区别
那么,Client JVM和Server JVM到底在哪些方面不同呢?Oracle官方网站的高频问题上这么解释的:
These two systems are different binaries. They are essentially two different compilers (JITs)interfacing to the same runtime system. The client system is optimal for applications which need fast startup times or small footprints, the server system is optimal for applications where the overall performance is most important. In general the client system is better suited for interactive applications such as GUIs. Some of the other differences include the compilation policy,heap defaults, and inlining policy.
大意是说,这两个JVM是使用的不同编译器。Client JVM适合需要快速启动和较小内存空间的应用,它适合交互性的应用,比如GUI;而Server JVM则是看重执行效率的应用的最佳选择。不同之处包括:编译策略、默认堆大小、内嵌策略。
根据《The Java HotSpot Performance Engine Architecture》:
The Client VM compiler does not try to execute many of the more complex optimizations performed by the compiler in the Server VM, but in exchange, it requires less time to analyze and compile a piece of code. This means the Client VM can start up faster and requires a smaller memory footprint.
Note: It seems that the main cause of the difference in performance is the amount of optimizations.
The Server VM contains an advanced adaptive compiler that supports many of the same types of optimizations performed by optimizing C++ compilers, as well as some optimizations that cannot be done by traditional compilers, such as aggressive inlining across virtual method invocations. This is a competitive and performance advantage over static compilers. Adaptive optimization technology is very flexible in its approach, and typically outperforms even advanced static analysis and compilation techniques.
Both solutions deliver extremely reliable, secure, and maintainable environments to meet the demands of today’s enterprise customers.
很明显,Client VM的编译器没有像Server VM一样执行许多复杂的优化算法,因此,它在分析和编译代码片段的时候更快。而Server VM则包含了一个高级的编译器,该编译器支持许多和在C++编译器上执行的一样的优化,同时还包括许多传统的编译器无法实现的优化。
官方文档是从编译策略和内嵌策略分析了二者的不同,下面的命令则从实际的情况体现了二者在默认堆大小上的差别:
对于Server JVM:
|
1
2
3
4
5
6
7
8
9
|
$ java -XX:+PrintFlagsFinal -version 2>&1 |
grep
-i -E
'heapsize|permsize|version'
uintx AdaptivePermSizeWeight = 20 {product}
uintx ErgoHeapSizeLimit = 0 {product}
uintx InitialHeapSize := 66328448 {product}
uintx LargePageHeapSizeThreshold = 134217728 {product}
uintx MaxHeapSize := 1063256064 {product}
uintx MaxPermSize = 67108864 {pd product}
uintx PermSize = 16777216 {pd product}
java version
"1.6.0_24"
|
对于Client JVM:
|
1
2
3
4
5
6
7
8
9
|
$ java -client -XX:+PrintFlagsFinal -version 2>&1 |
grep
-i -E
'heapsize|permsize|version'
uintx AdaptivePermSizeWeight = 20 {product}
uintx ErgoHeapSizeLimit = 0 {product}
uintx InitialHeapSize := 16777216 {product}
uintx LargePageHeapSizeThreshold = 134217728 {product}
uintx MaxHeapSize := 268435456 {product}
uintx MaxPermSize = 67108864 {pd product}
uintx PermSize = 12582912 {pd product}
java version
"1.6.0_24"
|
可以很清楚的看到,Server JVM的InitialHeapSize和MaxHeapSize明显比Client JVM大出许多来。
效率对比
下面是一个例子,它展示了二者执行的效率,该例子来自Onkar Joshi’s blog:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
public
class
LoopTest {
public
static
void
main(String[] args) {
long
start = System.currentTimeMillis();
spendTime();
long
end = System.currentTimeMillis();
System.out.println(end-start);
}
private
static
void
spendTime() {
for
(
int
i =
500000000
;i>
0
;i--) {
}
}
}
|
注意:这段代码只编译一次,只是运行这段代码的JVM不同而已。不要使用Eclipse中的Run As,因为它会将代码重新编译。这里,我们使用java命令来执行这段代码:

看到区别了吧?
自动检测Server-Class机器
以下内容引用自:http://docs.oracle.com/javase/6/docs/technotes/guides/vm/server-class.html
从J2SE 5.0开始,当一个应用启动的时候,加载器会尝试去检测应用是否运行在 "server-class" 的机器上,如果是,则使用Java HotSpot Server Virtual Machine (server VM)而不是 Java HotSpot Client Virtual Machine (client VM)。这样做的目的是提高执行效率,即使没有为应用显式配置VM。
注意: 从Java SE 6开始, server-class机器的定义是至少有2个CPU和至少2GB的物理内存
下面这张图展示了各个平台的默认的JVM(注意:—代表不提供该平台的JVM ):

-------------------------------引用内容结束--------------------------------------
JVM类型的切换
上面的运行结果中还提到了如何切换JVM的类型,我们就来看看为什么第一个截图里面输出的是:
|
1
|
Java HotSpot(TM) Client VM
|
这里需要注意的是,Oracle网站这样说:
Client and server systems are both downloaded with the 32-bit Solaris and Linux downloads. For 32-bit Windows, if you download the JRE, you get only the client, you'll need to download the SDK to get both systems.
因此,如果想要在windows平台下从Client JVM切换到Server JVM,需要下载JDK而非JRE。打开JDK安装目录(即%JAVA_HOME%):我们可以看到%JAVA_HOME%\jre\bin下有一个server和client文件夹,这里面各有一个jvm.dll,但是大小不同,这就说明了它们是不同的JVM的文件:

打开 %JAVA_HOME%\jre\lib\i386\jvm.cfg文件(正如第一幅图所见,我这里安装的是32JDK,其他版本的JDK可能不是i386文件夹)(注意是JDK文件夹下的jre,而非和JDK同级的jre6/7/8),会注意到以下内容(灰色选中部分):

再看看下方的配置,第一行就配置了使用client方式,因此首选使用client模式的JVM,这就是为什么一开始的java -version命令会输出Java HotSpot(TM) Client VM的原因了。现在将第33、34行配置交换一下,再在命令行中输入java -version,则会得到以下结果:

这就将JVM的工作模式切换到Server了,这个修改是全局的,以后使用到的这个JVM都是工作在Server模式的。
当然,如果你不想全局改动,也可以按照下面在java命令后加上-server或者-client来明确指定本次java命令需要JVM使用何种模式来工作,例如:

这个就是语句级的修改了。
注意,不管是全局修改还是语句级的修改,实际上会导致下次执行Java程序时会使用对应目录下的jvm.dll。如何证明?这里我将%JAVA_HOME%\jre\bin下面的server文件夹移动到其他位置,再次运行java -server -version命令,则会出现下面的错误:

JVM的工作模式
JVM的几种工作模式
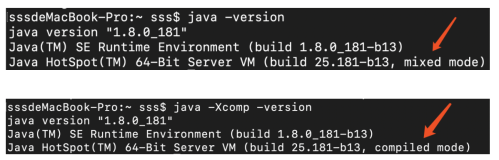
在命令行里输入java -X,你会看到以下结果:

其实这两个是JVM工作的模式。JVM有以下几种模式:-Xint, -Xcomp, 和 -Xmixed。从上图的输出结果中也可以看到,mixed是JVM的默认模式,其实在文章一开始的时候就提到了,因为在java -version命令中,输出了以下内容:
|
1
|
Java HotSpot(TM) Client VM (build
24.79
-b02, mixed mode, sharing)
|
中间的mixed mode就说明当前JVM是工作在mixed模式下的。-Xint和-Xcomp参数和我们的日常工作不是很相关,但是我非常有兴趣通过它来了解下JVM。
-Xint代表解释模式(interpreted mode),-Xint标记会强制JVM以解释方式执行所有的字节码,当然这会降低运行速度,通常低10倍或更多。现在通过刚才的例子(没有重新编译过)来验证一下:

可以看到,在都使用Client JVM的前提下,混合模式下,平均耗时150ms,然而在解释模式下,平均耗时超过1600ms,这基本上是10倍以上的差距。
-Xcomp代表编译模式(compiled mode),与它(-Xint)正好相反,JVM在第一次使用时会把所有的字节码编译成本地代码,从而带来最大程度的优化。这听起来不错,因为这完全绕开了缓慢的解释器。然而,很多应用在使用-Xcomp也会有一些性能损失,但是这比使用-Xint损失的少,原因是-Xcomp没有让JVM启用JIT编译器的全部功能。因此在上图中,我们并没有看到-Xcomp比-Xmixed快多少。
-Xmixed代表混合模式(mixed mode),前面也提到了,混合模式是JVM的默认工作模式。它会同时使用编译模式和解释模式。对于字节码中多次被调用的部分,JVM会将其编译成本地代码以提高执行效率;而被调用很少(甚至只有一次)的方法在解释模式下会继续执行,从而减少编译和优化成本。JIT编译器在运行时创建方法使用文件,然后一步一步的优化每一个方法,有时候会主动的优化应用的行为。这些优化技术,比如积极的分支预测(optimistic branch prediction),如果不先分析应用就不能有效的使用。这样将频繁调用的部分提取出来,编译成本地代码,也就是在应用中构建某种热点(即HotSpot,这也是HotSpot JVM名字的由来)。使用混合模式可以获得最好的执行效率。
切换JVM的工作模式
和切换JVM的类型一样,我们可以在命令行里显示指定使用JVM的何种模式,比如:

获取JVM的工作模式
在JVM运行时,我们可以通过下列代码检查JVM的类型和工作模式:
|
1
2
|
System.out.println(System.getProperty(
"java.vm.name"
));
//获取JVM名字和类型
System.out.println(System.getProperty(
"java.vm.info"
));
//获取JVM的工作模式
|
你可能得到以下结果: