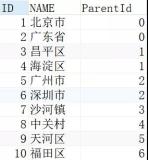
用COUNT来查询一个表的记录多少,小的时候无所谓,记录多的时候速度就是个问题。
那天在PGSQL版里看到这个。总结一下。
此刻表引擎为MyISAM.
mysql> desc content;
+ ---------+------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+ ---------+------------+------+-----+---------+-------+
| cid | int(11) | NO | | 0 | |
| aid | int(11) | YES | | NULL | |
| content | mediumtext | YES | | NULL | |
+ ---------+------------+------+-----+---------+-------+
3 rows in set (0.02 sec)
mysql> select count(*) from content;
+ ----------+
| count(*) |
+ ----------+
| 208081 |
+ ----------+
1 row in set (0.05 sec)
更新为INNODB.
mysql> alter table content engine innodb;
Query OK, 208081 rows affected (2 min 19.80 sec)
Records: 208081 Duplicates: 0 Warnings: 0
mysql> select count(*) from content;
+ ----------+
| count(*) |
+ ----------+
| 208081 |
+ ----------+
1 row in set (33.99 sec)
新建立一个表专门存储记录的多少。如果要存放多个表的记录数目,以后增加相应的字段就可以了。
create table t_count (count_content int not null default 0);
insert into t_count(count_content) select count(*) from content;
DELIMITER $$
CREATE TRIGGER `tr_count_insert` AFTER INSERT on `content`
FOR EACH ROW BEGIN
update t_count set count_content = count_content + 1;
END$$
DELIMITER ;
DELIMITER $$
CREATE TRIGGER `tr_count_delete` AFTER DELETE on `content`
FOR EACH ROW BEGIN
update t_count set count_content = count_content - 1;
END$$
DELIMITER ;
这样虽然对数据更新操作有性能上的影响,不过查询速度就非常快了。因为这个表无论如何只有一条记录。
mysql> delete from content limit 1;
Query OK, 1 row affected (0.06 sec)
mysql> select count(*) from content;
+ ----------+
| count(*) |
+ ----------+
| 208080 |
+ ----------+
1 row in set (37.79 sec)
mysql> select count_content from t_count;
+ ---------------+
| count_content |
+ ---------------+
| 208080 |
+ ---------------+
那天在PGSQL版里看到这个。总结一下。
此刻表引擎为MyISAM.
mysql> desc content;
+ ---------+------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+ ---------+------------+------+-----+---------+-------+
| cid | int(11) | NO | | 0 | |
| aid | int(11) | YES | | NULL | |
| content | mediumtext | YES | | NULL | |
+ ---------+------------+------+-----+---------+-------+
3 rows in set (0.02 sec)
mysql> select count(*) from content;
+ ----------+
| count(*) |
+ ----------+
| 208081 |
+ ----------+
1 row in set (0.05 sec)
更新为INNODB.
mysql> alter table content engine innodb;
Query OK, 208081 rows affected (2 min 19.80 sec)
Records: 208081 Duplicates: 0 Warnings: 0
mysql> select count(*) from content;
+ ----------+
| count(*) |
+ ----------+
| 208081 |
+ ----------+
1 row in set (33.99 sec)
新建立一个表专门存储记录的多少。如果要存放多个表的记录数目,以后增加相应的字段就可以了。
create table t_count (count_content int not null default 0);
insert into t_count(count_content) select count(*) from content;
DELIMITER $$
CREATE TRIGGER `tr_count_insert` AFTER INSERT on `content`
FOR EACH ROW BEGIN
update t_count set count_content = count_content + 1;
END$$
DELIMITER ;
DELIMITER $$
CREATE TRIGGER `tr_count_delete` AFTER DELETE on `content`
FOR EACH ROW BEGIN
update t_count set count_content = count_content - 1;
END$$
DELIMITER ;
这样虽然对数据更新操作有性能上的影响,不过查询速度就非常快了。因为这个表无论如何只有一条记录。
mysql> delete from content limit 1;
Query OK, 1 row affected (0.06 sec)
mysql> select count(*) from content;
+ ----------+
| count(*) |
+ ----------+
| 208080 |
+ ----------+
1 row in set (37.79 sec)
mysql> select count_content from t_count;
+ ---------------+
| count_content |
+ ---------------+
| 208080 |
+ ---------------+
1 row in set (0.01 sec)
本文转自 david_yeung 51CTO博客,原文链接:http://blog.51cto.com/yueliangdao0608/81266,如需转载请自行联系原作者