转自:https://ayende.com/blog/171745/code-reading-wukong-full-text-search-engine
I like reading code, and recently I was mostly busy with moving our offices, worrying about insurance, lease contracts and all sort of other stuff that are required, but not much fun. So I decided to spend a few hours just going through random code bases and see what I’ll find.
I decided to go with Go projects, because that is a language that I can easily read, and I headed out to this page. Then I basically scanned the listing for any projects that took my fancy. The current one is Wukong, which is a full text search engine. I’m always interested in those, since Lucene is a core part of RavenDB, and knowing how others are implementing this gives you more options.
This isn’t going to be a full review, merely a record of my exploration into the code base. There is one problem with the codebase, as you can see here:

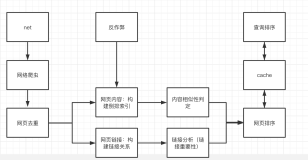
All the text is in Chinese, which I know absolutely nothing about, so comments aren’t going to help here. But so far, the code looks solid. I’ll start from the high level overview:

We can see that we have a searcher (of type Engine), and we add documents to it, then we flush the index, and then we can search it.
Inside the engine.Init, the first interesting thing is this:

This is interesting because we see sharding from the get go. By default, there are two shards. I’m sure what the indexers are, or what they are for yet.
Note that there is an Indexer and a Ranker for each shard. Then we have a bunch of initialization routines that looks like so:

So we create two arrays of channels (the core Go synchronization primitive), and initialize them with a channel per shard. That is a pretty standard Go behavior, and usually there is a go routine that is spinning on each of those channels. That means that we have (by default) two “threads” for adding documents, and two for doing lookups. No idea what either one of those are yet.
There is a lot more like this, for ranking, removing ranks, search ranks, etc, but that is just more of the same, and I’ll ignore it for now. Finally, we see some actions when we start producing threads to do actual works:

As you can see, spin off go routines (which will communicate with the channels we already saw) to do the actual work. Note that per shard, we’ll have as many index lookup and rank workers as we have CPUs.
There is an option to persist to disk, using the kv package, this looks like this:

On the one hand, I really like the “let us just import a package from github” option that go has, on the other hand. Versioning control has got to be a major issue here for big projects.
Anyway, let us get back to the actual hot path I’m interested in, indexing documents. This is done by this function:
 a
a
Note that we have to supply the docId externally, instead of creating it ourselves. Then we just hash the docId and the actual content and send the data to the segmenter to do work. Currently I think that the work of the segmenter is similar to the work of the analyzer in Lucene. To break apart the content to discrete terms. Let us check…

this certainly seems to be the case here, yep. This code run on as many cores as the machine has, each one handling a single segmentation request. Once that work is done, it is sent to another thread to actually do the indexing:

Note that the indexerRequest is basically an array of all the distinct tokens, their frequencies and the start positions in the original document. There is also handling for ranking, but for now I don’t care about this, so I’ll ignore this.
Sending to the indexing channel will end up invoking this code:

And the actual indexing work is done inside AddDocument. A simplified version of it is show here:

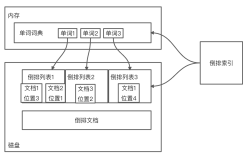
An indexer is protected by a read/write mutex (which explains why we want to have sharding, it gives us better concurrency, without having to go to concurrent data structures and it drastically simplify the code.
So, what is going on in here? For each of the keywords we found on the document, we create a new entry in the table’s dictionary. With a value that contains the matching document ids. If there are already documents for this keyword, we’ll search for the appropriate position in the index (using simple binary search), then place the document in the appropriate location. Basically, the KeywordIndices is (simplified) Dictionary<Term : string , SortedList<DocId : long>>.
So that pretty much explains how this works. Let us look at how searches are working now…
The first interesting thing that we do when we get a search request is tokenize it (segmentize it, in Wukong terminology):

Then we call this code:

This is a fairly typical Go code. We create a bounded channel (that has a capacity as the same number of the shards), and we send it to all the shards. We’ll get the reply from all of the shards, then do something with the results from all the shards.
I like this type of interaction because it is easy to model concurrent interactions with it, and it is pervasive in Go. Seems simpler than the comparable strategies in .NET, for example.
Here is a simple example of how this is used:

This is the variant without the timeout. And we are just getting the results from all the shards, note that we don’t have any ordering here, we just add all the documents into one big array. I’m not sure how/if Wukong support sorting, there was a lot of stuff about ranking earlier in the codebase, but that doesn’t seem to be apparent in what I saw so far, I’ll look at it later. For now, let us see how a single shard is handling a search lookup request.
What I find most interesting is that there is rank options there, and document ids, which I’m not sure what they are used for. We’ll look at that later, for now, the first part of looking up a search term is here:

We take a read lock, then look at the table. We need to find entries for all the keywords that we have in the query to get a result back.
This indicates that a query to Wukong has an implicit AND between all the terms in the query. The result of this is an array with all the indices for each keyword. It then continues to perform set intersection between all the matching keywords, to find all the documents that appear in all of them. Following that, it will compute the BM25 (a TF-IDF function that is used to compute ranking). After looking at the code, I found where it is actual compute the ranking. It is doing that after getting the results from all the shards, and then it is going to sort them according to their overall scores.
So that was clear enough, and it makes a lot of sense. Now, the last thing that I want to figure out before we are done, is how does Wukong handles deletions?
It turns out that I actually missed part in the search process. The indexer will just find the matching documents, but their BM25 score. It is the ranker (which is sent from the indexer, and then replying to the engine) that will actually sort them. This gives the user the chance to add their own scoring mechanism. Deletion is actually handled as a case where you have nothing to score with, and it gets filtered along the way as an uninteresting value. That means that the memory cost of having a document index cannot be alleviated by deleting it. The actual document data is still there and is kept.
It also means that there is no real facility to update a document. For example, if we have a document whose content used to say Ayende and we want to change it to Oren. We have no way of going to the Ayende keyword and removing it from there. We need to delete the document and create a new one, with a new document id.
Another thing to note is that this has very little actual functionality. There is no possibility of making complex queries, or using multiple fields. Another thing that is very different from how Lucene works is that is runs entirely in memory. While it has a persistent option, that option is actually just a log of documents being added and removed. On startup, it will need to go through the log and actually index all of them again. That means that for large systems, it is going to be a prohibitly expensive startup cost.
All in all, that is a nice codebase, and it is certainly simple enough to grasp without too much complexity. But one need to be aware of the tradeoffs associated with actually using it. I expect it to be fast, although the numbers mentioned in the benchmark page (if I understand the translated Chinese correctly) are drastically below what I would expect to see. Just to give you some idea, 1,400 requests a second are a very small number for an in memory index. I would expect something like 50,000 or so, assuming that you can get all cores to participate. But maybe they are counting this through the network ?
本文转自张昺华-sky博客园博客,原文链接:http://www.cnblogs.com/bonelee/p/6288946.html,如需转载请自行联系原作者