本文提出一种基于注意力机制的用户异构行为序列的建模框架,并将其应用到推荐场景中。我们将不同种类的用户行为序列进行分组编码,并映射到不同子空间中。我们利用self-attention对行为间的互相影响进行建模。最终我们得到用户的行为表征,下游任务就可以使用基本的注意力模型进行有更具指向性的决策。我们尝试用同一种模型同时预测多种类型的用户行为,使其达到多个单独模型预测单类型行为的效果。另外,由于我们的方法中没有使用RNN,CNN等方法,因此在提高效果的同时,该方法能够有更快的训练速度。
研究背景
一个人是由其所表现出的行为所定义。而对用户精准、深入的研究也往往是很多商业问题的核心。从长期来看,随着人们可被记录的行为种类越来越多,平台方需要有能力通过融合各类不同的用户行为,更好的去理解用户,从而提供更好的个性化服务。
对于阿里巴巴来说,以消费者运营为核心理念的全域营销正是一个结合用户全生态行为数据来帮助品牌实现新营销的数据&技术驱动的解决方案。因此,对用户行为的研究就成为了一个非常核心的问题。其中,很大的挑战来自于能否对用户的异构行为数据进行更精细的处理。
在这样的背景下,本文提出一个通用的用户表征框架,试图融合不同类型的用户行为序列,并以此框架在推荐任务中进行了效果验证。另外,我们还通过多任务学习的方式,期望能够利用该用户表征实现不同的下游任务。
相关工作
异构行为建模:通常通过手动特征工程来表示用户特征。这些手工特征以聚合类特征或无时序的id特征集合为主。
单行为序列建模:用户序列的建模通常会用RNN(LSTM/GRU)或者CNN + Pooling的方式。RNN难以并行,训练和预测时间较长,且LSTM中的Internal Memory无法记住特定的行为记录。CNN也无法保留特定行为特征,且需要较深的层次来建立任意行为间的影响。
异构数据表征学习:参考知识图谱和Multi-modal的表征研究工作,但通常都有非常明显的映射监督。而在我们的任务中,异构的行为之间并没有像image caption这种任务那样明显的映射关系。
本文的主要贡献如下:
- 尝试设计和实现了一种能够融合用户多种时序行为数据的方法,较为创新的想法在于提出了一种同时考虑异构行为和时序的解决方案,并给出较为简洁的实现方式。
- 使用类似Google的self-attention机制去除CNN、LSTM的限制,让网络训练和预测速度变快的同时,效果还可以略有提升。
- 此框架便于扩展。可以允许更多不同类型的行为数据接入,同时提供多任务学习的机会,来弥补行为稀疏性。
ATRank方案介绍
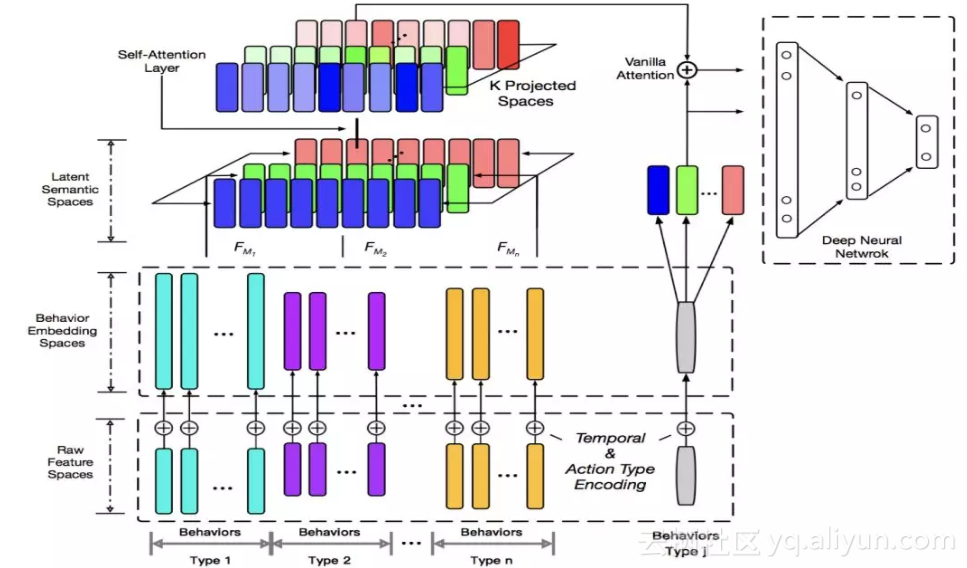
整个用户表征的框架包括原始特征层,语义映射层,Self-Attention层和目标网络。
语义映射层能让不同的行为可以在不同的语义空间下进行比较和相互作用。Self-Attention层让单个的行为本身变成考虑到其他行为影响的记录。目标网络则通过Vanilla Attention可以准确的找到相关的用户行为进行预测任务。通过Time Encoding + Self Attention的思路,我们的实验表明其的确可以替代CNN/RNN来描述序列信息,能使模型的训练和预测速度更快。
1. 行为分组
某个用户的行为序列可以用一个三元组来描述(动作类型,目标,时间)。我们先将用户不同的行为按照目标实体进行分组,如图中最下方不同颜色group。例如商品行为,优惠券行为,关键字行为等等。动作类型可以是点击/收藏/加购、领取/使用等等。
每个实体都有自己不同的属性,包括实值特征和离散id类特征。动作类型是id类,我们也将时间离散化。三部分相加得到下一层的向量组。
即,某行为的编码 = 自定义目标编码 + lookup(离散化时间) + lookup(动作类型)。
由于实体的信息量不同,因此每一组行为编码的向量长度不一,其实也代表行为所含的信息量有所不同。另外,不同行为之间可能会共享一些参数,例如店铺id,类目id这类特征的lookup table,这样做能减少一定的稀疏性,同时降低参数总量。
分组的主要目的除了说明起来比较方便,还与实现有关。因为变长、异构的处理很难高效的在不分组的情况下实现。并且在后面还可以看到我们的方法实际上并不强制依赖于行为按时间排序。
2. 语义空间映射
这一层通过将异构行为线性映射到多个语义空间,来实现异构行为之间的同语义交流。例如框架图中想表达的空间是红绿蓝(RGB)构成的原子语义空间,下面的复合色彩(不同类型的用户行为)会投影到各个原子语义空间。在相同语义空间下,这些异构行为的相同语义成分才有了可比性。
类似的思路其实也在knowledge graph representation里也有出现。而在NLP领域,今年也有一些研究表明多语义空间的attention机制可以提升效果。个人认为的一点解释是说,如果不分多语义空间,会发生所谓语义中和的问题。简单的理解是,两个不同种类的行为a,b可能只在某种领域上有相关性,然而当attention score是一个全局的标量时, a,b在不那么相关的领域上会增大互相影响,而在高度相关的领域上这种影响则会减弱。
尽管从实现的角度上来说,这一层就是所有行为编码向一个统一的空间进行映射,映射方法线性非线性都可以,但实际上,对于后面的网络层来说,我们可以看作是将一个大的空间划分为多语义空间,并在每个子空间里进行self-attention操作。因此从解释上来说,我们简单的把这个映射直接描述成对多个子语义空间进行投影。
3. Self Attention层
Self Attention层的目的实际上是想将用户的每一个行为从一个客观的表征,做成一个用户记忆中的表征。客观的表征是指,比如A,B做了同样一件事,这个行为本身的表征可能是相同的。但这个行为在A,B的记忆中,可能强度、清晰度是完全不一样的,这是因为A,B的其他行为不同。实际上,观察softmax函数可知,某种相似行为做的越多,他们的表征就越会被平均。而带来不一样体验的行为则会更容易保留自己的信息。因此self attention实际上模拟了一个行为被其他行为影响后的表征。
另外,Self Attention可以有多层。可以看到,一层Self-Attention对应着一阶的行为影响。多层则会考虑多阶的行为影响。这个网络结构借鉴的是google的self-attention框架。
具体计算方式如下:
记S是整个语义层拼接后的输出,Sk是第k个语义空间上的投影,则经过self-attention后第k个语义空间的表征计算公式为:
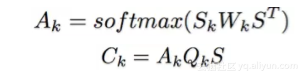
这里的attention function可以看做是一种bilinear的attention函数。最后的输出则是这些空间向量拼接后再加入一个前馈网络。
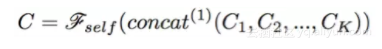
4. 目标网络
目标网络会随着下游任务的不同而定制。本文所涉及的任务是用户行为预测及推荐场景的点击预测的任务,采用的是point-wise的方式进行训练和预测。
框架图中灰色的bar代表待预测的任意种类的行为。我们将该行为也通过embedding、projection等转换,然后和用户表征产出的行为向量做vanilla attention。最后Attention向量和目标向量将被送入一个Ranking Network。其他场景强相关的特征可以放在这里。这个网络可以是任意的,可以是wide & deep,deep FM,pnn都行。我们在论文的实验中就是简单的dnn。
离线实验
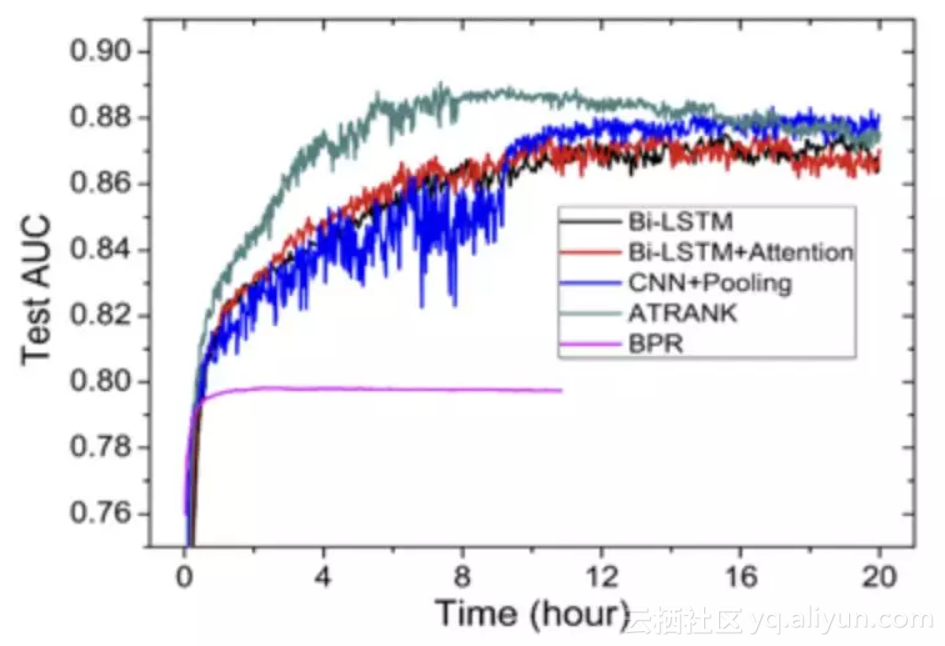
为了比较框架在单行为预测时的效果,我们在amazon购买行为的公开数据集上的实验。
训练收敛结果如下图:
用户平均AUC如下图:
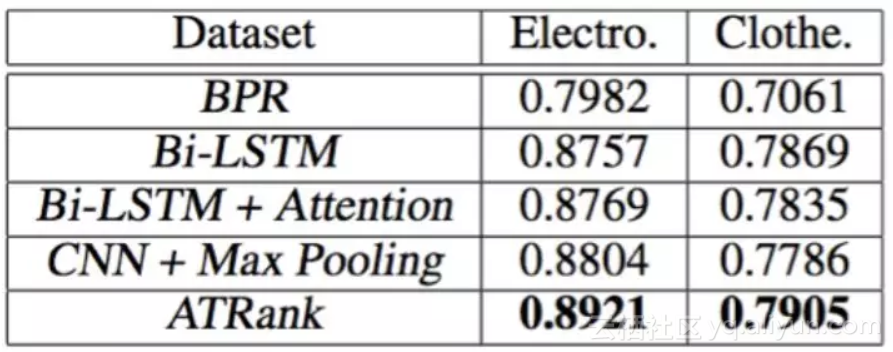
实验结论:在行为预测或推荐任务中,self-attention + time encoding也能较好的替代cnn+pooling或lstm的编码方式。训练时间上能较cnn/lstm快4倍。效果上也能比其他方法略好一些。
Case Study
为了深究Self-Attention在多空间内的意义,我们在amazon dataset上做了一个简单的case study。如下图:
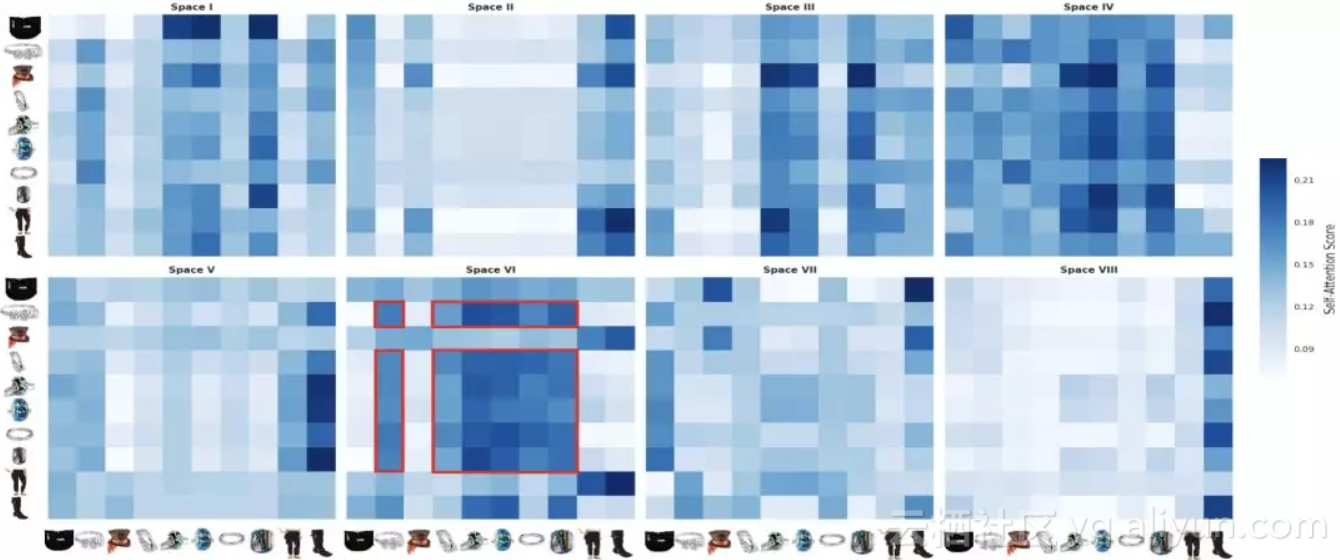
从图中我们可以看到,不同的空间所关注的重点很不一样。例如空间I, II, III, VIII中每一行的attention分的趋势类似。这可能是主要体现不同行为总体的影响。另一些空间,例如VII,高分attention趋向于形成稠密的正方形,我们可以看到这其实是因为这些商品属于同样的类目。
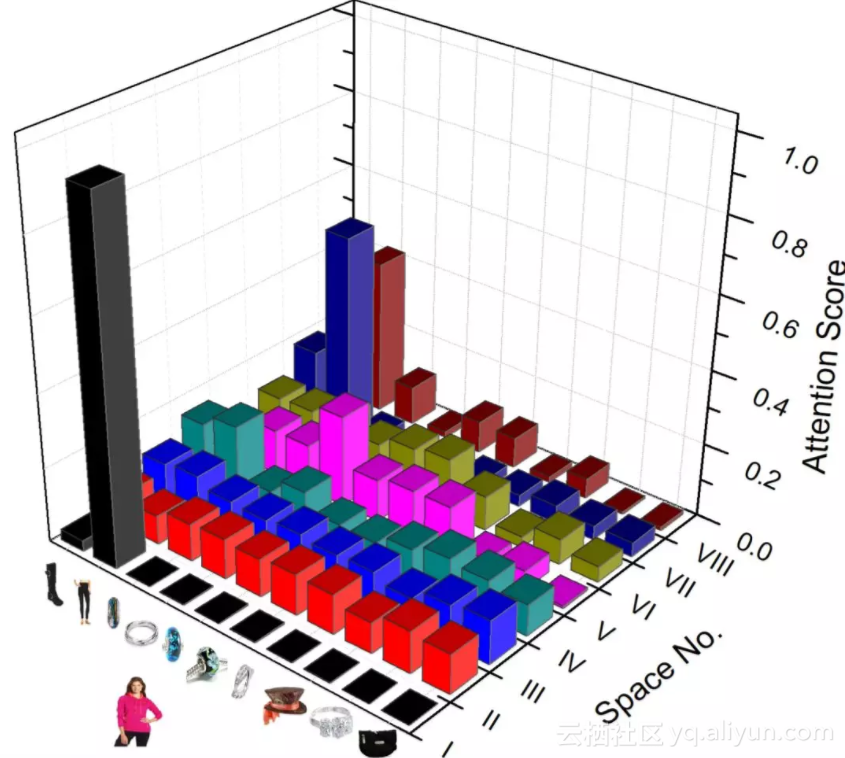
下图则是vanilla attention在不同语义空间下的得分情况。
多任务学习
论文中,我们离线收集了阿里电商用户对商品的购买点击收藏加购、优惠券领取、关键字搜索三种行为进行训练,同样的也对这三种不同的行为同时进行预测。其中,用户商品行为记录是全网的,但最终要预测的商品点击行为是店铺内某推荐场景的真实曝光、点击记录。优惠券、关键字的训练和预测都是全网行为。
我们分别构造了7种训练模式进行对比。分别是单行为样本预测同类行为(3种),全行为多模型预测单行为(3种),全行为单模型预测全行为(1种)。在最后一种实验设置下,我们将三种预测任务各自切成mini-batch,然后统一进行shuffle并训练。
实验结果如下表:
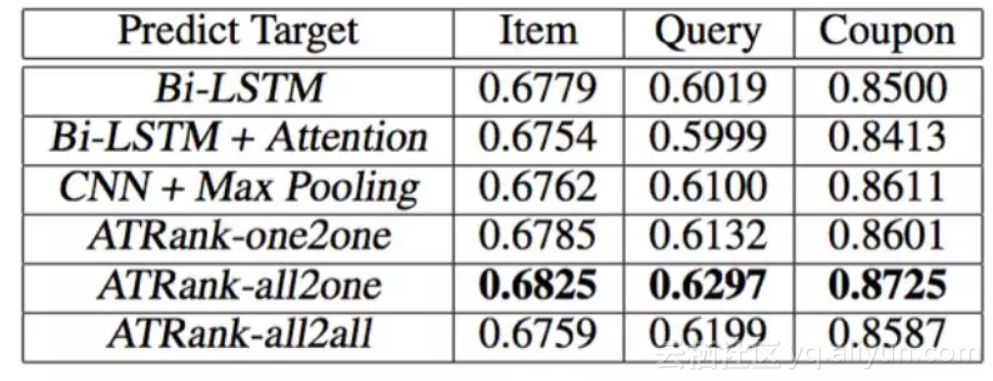
all2one是三个模型分别预测三个任务,all2all是单模型预测三个任务,即三个任务共享所有参数,而没有各自独占的部分。因此all2all与all2one相比稍低可以理解。我们训练多任务all2all时,将三种不同的预测任务各自batch后进行充分随机的shuffle。文中的多任务训练方式还是有很多可以提升的地方,前沿也出现了一些很好的可借鉴的方法,是我们目前正在尝试的方向之一。
实验表明,我们的框架可以通过融入更多的行为数据来达到更好的推荐/行为预测的效果。
总结
本文提出一个通用的用户表征框架,来融合不同类型的用户行为序列,并在推荐任务中得到验证。
未来,我们希望能结合更多实际的商业场景和更丰富的数据沉淀出灵活、可扩展的用户表征体系,从而更好的理解用户,提供更优质的个性化服务,输出更全面的数据能力。
原文发布时间为:2018-01-25
本文作者:周畅,白金泽,宋军帅,刘效飞,赵争超,陈修司,高军
本文来自云栖社区合作伙伴新智元,了解相关信息可以关注“AI_era”微信公众号


