1.概述
在接触了第一代MapReduce和第二代MapReduce之后,或许会有这样的疑惑,我们从一些书籍和博客当中获取MapReduce的一些原理和算法,在第一代当中会有JobTrack,TaskTrack之类的术语,在第二代会有ResourceManager,NodeManager,ApplicationMaster等等术语。然又有Shuffle、Partitioner、Sort、Combiner等关键字,如何区分它们,理顺其之间的联系。
在Hadoop2.x大行其道的年代,其优秀的资源管理框架(系统),高可用的分布式存储系统,备受企业青睐。然因上述之惑,往往不能尽得其中之深意。此篇博客笔者为大家一一解惑。
2.计算模型
在阅读和研究第一代MapReduce和第二代MapReduce之后,我们可以发现MapReduce其实由两部分组成,一者为其计算模型,二者为其运行环境。到这里,就不难解释为何在第一代MapReduce里面由Shuffle、Sort等内容,而在第二代MapReduce中也同样存在其相关内容。原因很简单,在Hadoop2.x中,MapReduce的变化,只有其运行环境变化了,然其计算模型依旧不变。
在MapReduce的计算模型当中,对方法进行了高阶抽象,其精华为Map Task和Reduce Task,在Map阶段完成对应的map函数的逻辑实现,与之相对的在Reduce阶段完成对应的reduce函数的逻辑实现,即可编写好整个核心的MapReduce的处理过程,在Main函数入口之处,申请对应的Job,指定相应的Mapper和Reducer继承类,以及其输入输出类型等相关信息,即可运行一个完整的MapReduce任务。
虽说我们能够编写一个完成MapReduce程序,并运行它。然其运行的细节,我们却未必清楚,往往初学者在编写一个MapReduce作业时,遇到错误而不去研究分析其错误之根本,转而求助于搜索引擎,在搜索无望之下,会让自己瞬间懵逼,不知所措。
这里,我们去剖析其计算模型的执行细节,虽不敢说剖析之后能解决所有的疑难杂症,但起码能让我们知晓错误原因,能够找到解决问题的方向,继而解决我们所遇之难题。下面为大家剖析MapReduce的计算模型。
Map阶段,简言之:
- Read:该步骤是去读取我们的数据源,将数据进行filter成一个个的K/V
- Map:在map函数中,处理解析的K/V,并产生新的K/V
- Collect:输出结果,存于环形内缓冲区
- Spill:内存区满,数据写到本地磁盘,并生产临时文件
- Combine:合并临时文件,确保生产一个数据文件
Reduce阶段,简言之:
- Shuffle:Copy阶段,Reduce Task到各个Map Task远程复制一分数据,针对某一份数据,若其大小超过一定阀值,则写磁盘;否则放到内存
- Merge:合并内存和磁盘上的文件,防止内存占用过多或磁盘文件过多
- Sort:Map Task阶段进行局部排序,Reduce Task阶段进行一次归并排序
- Reduce:将数据给reduce函数
- Write:reduce函数将其计算的结果写到HDFS上
上述为其计算模型的执行过程,需有几点要额外注意。这里有些阶段,我们在编写相关应用时,需有谨慎。
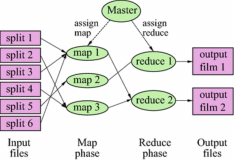
这里有一个Combine阶段,这个阶段的使用有助与我们对MapReduce的性能进行优化,为何这么说?细细剖析该过程便可明白。在map函数时,它只管处理数据,并不负责统计处理数据的结果,也就是说并没有Combine阶段,那么,问题来了,在reduce过程当中,因为每个map函数处理后的数据没有统计,它除了要统计所有map的汇总数量,还要统计单个map下的处理数。也许,这里有点绕,大家可以参照下图来理解这层意思,如下图所示:

然而,这样是不行的,所以Reduce为了减轻压力,每个map都必须统计自己旗下任务处理结果,即:Combine。这样,Reduce所做的事情就是统计每个map统计之后的结果,这样子就会轻松许多。因而,Combine在map所做的事情,减轻了Reduce的事情,省略了上图中的步骤1。
具体代码细节,可在Job的属性方法中设置对应的参数,如下所示:
job.setCombinerClass(DefReducer.class);
另外,我们也有必要理解Partition相关职责,它是分割map节点的结果,按照Key分别映射给不同的Reduce,这里我们可以理解为归类,对一些复杂的数据进行归类。在Job属性中设置对应的分区类,那么你的分区函数就生效了,如下所示:
job.setPartitionerClass(DefPartition.class);
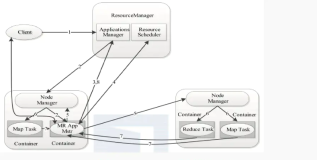
3.运行环境
在Hadoop2.x中,由于有了YARN来做资源管理,因而第二代MapReduce的运行环境,对比第一代MapReduce有了些许的改变。具体改变细节,可参考我写的另一篇博客:《MapReduce运行环境剖析》。
4.总结
本篇博客给大家剖析了MapReduce的计算模型和运行环境,其中计算模型不变,变者乃其运行环境。所变内容,简言之:RM下包含AM和NM,NM会RM申请Container(其可理解为一个运行时的JVM),NM与RM的通信属于“Pull模型”,即NM主动上报状态信息,RM被动接受上报信息。
5.结束语
这篇文章就和大家分享到这里,如果大家在研究和学习的过程中有什么疑问,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!