1.概述
Kafka Streams 是一个用来处理流式数据的库,属于Java类库,它并不是一个流处理框架,和Storm,Spark Streaming这类流处理框架是明显不一样的。那这样一个库是做什么的,能应用到哪些场合,如何使用。笔者今天就给大家来一一剖析这些内容。
2.内容
首先,我们研究这样一个库,需要知道它是做什么的。Kafka Streams是一个用来构建流处理应用的库,和Java的那些内置库一样,以一种分布式的容错方式来处理一些事情。当前,业界用于流处理的计算框架包含有:Flink,Spark,Storm等等。Kafka Streams处理完后的结果可以回写到Topic中,也可以外接其他系统进行落地。包含以下特性:
- 事件区分:记录数据发生的时刻
- 时间处理:记录数据被流处理应用开始处理的时刻,如记录被消费的时刻
- 开窗
- 状态管理:本身应用不需要管理状态,如若需要处理复杂的流处理应用(分组,聚合,连接等)
Kafka Streams使用是很简单的,这一点通过阅读官方的示例代码就能发现,另外它利用Kafka的并发模型来完成负载均衡。
2.1 优势
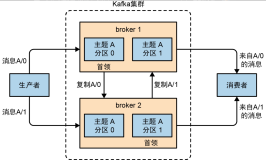
在Kafka集群上,能够很便捷的使用,亮点如下图所示:

- 能够设计一些轻量级的Client类库,和现有的Java程序整合
- 不需要额外的Kafka集群,利用现有的Kafka集群的分区实现水平扩展
- 容错率,高可用性
- 多平台部署,支持Mac,Linux和Windows系统
- 权限安全控制
2.2 Sample
Kafka Streams是直接构建与Kafka的基础之上的,没有了额外的流处理集群,Table和一些有状态的处理完全整合到了流处理本身。其核心代码非常的简介。简而言之,就和你写Consumer或Producer一样,但是Kafka Streams更加的简洁。
2.3 属性
| 名称 | 描述 | 类型 | 默认值 | 级别 |
| application.id | 流处理标识,对应一个应用需要保持一致,用作消费的group.id | string | 高 | |
| bootstrap.servers | 用来发现Kafka的集群节点,不需要配置所有的Broker | list | 高 | |
| replication.factor | 复制因子 | int | 1 | 高 |
| state.dir | 本地状态存储目录 | string | /tmp/kafka-streams | 高 |
| cache.max.bytes.buffering | 所有线程的最大缓冲内存 | long | 10485760 | 中 |
| client.id | 客户端逻辑名称,用于标识请求位置 | string | "" | 中 |
| default.key.serde | 对Key序列化或反序列化类,实现于Serde接口 | class | org.apache.kafka.common.serialization.Serdes$ByteArraySerde | 中 |
| default.value.serde | 对Value序列化或反序列化类,实现与Serde接口 | class | org.apache.kafka.common.serialization.Serdes$ByteArraySerde | 中 |
| ... | ... | ... | ... | ... |
这里只是列举了部分Kafka Streams的属性值,更多的详情可参考Kafka Streams Configs。
3.示例
下面,我们可以通过一个示例代码,来熟悉Kafka Streams的运行流程,如下所示:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
import
org.apache.kafka.common.serialization.Serdes;
import
org.apache.kafka.streams.KafkaStreams;
import
org.apache.kafka.streams.StreamsConfig;
import
org.apache.kafka.streams.kstream.KStream;
import
org.apache.kafka.streams.kstream.KStreamBuilder;
import
org.apache.kafka.streams.kstream.KTable;
import
java.util.Arrays;
import
java.util.Properties;
public
class
WordCountApplication {
public
static
void
main(
final
String[] args)
throws
Exception {
Properties config =
new
Properties();
config.put(StreamsConfig.APPLICATION_ID_CONFIG,
"wordcount_topic_appid"
);
config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,
"kafka1:9092,kafka2:9092,kafka3:9092"
);
config.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
config.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
KStreamBuilder builder =
new
KStreamBuilder();
KStream<String, String> textLines = builder.stream(
"TextLinesTopic"
);
KTable<String, Long> wordCounts = textLines
.flatMapValues(textLine -> Arrays.asList(textLine.toLowerCase().split(
"\\W+"
)))
.groupBy((key, word) -> word)
.count(
"Counts"
);
wordCounts.to(Serdes.String(), Serdes.Long(),
"WordsWithCountsTopic"
);
KafkaStreams streams =
new
KafkaStreams(builder, config);
streams.start();
}
}
|
从代码中,我们可以看出Kafka Streams为上层流定义了两种基本抽象:
- KStream:可以从一个或者多个Topic源来创建
- KTable:从一个Topic源来创建
这两者的区别是,前者比较像传统意义上的流,可以把每一个K/V看成独立的,后者的思想更加接近与Map的概念。同一个Key输入多次,后者是会覆盖前者的。而且,KStream和KTable都提供了一系列的转换操作,每个操作可以产生一个或者多个KStream和KTable对象,所有这些转换的方法连接在一起,就形成了一个复杂的Topology。由于KStream和KTable是强类型,这些转换都被定义为通用函数,这样在使用的时候让用户指定输入和输出数据类型。
另外,无状态的转换不依赖于处理的状态,因此不需要状态仓库。有状态的转换则需要进行存储相应的状态用于处理和生成结果。例如,在进行聚合操作的时候,一个窗口状态用于保存当前预定义收到的值,然后转换获取累计的值,再做计算。
在处理完后,对于结果集用户可以持续的将结果回写到Topic,也可以通过KStream.to() 或者 KTable.to() 方法来实现。
4.总结
通过对Kafka Streams的研究,它的优势可以总结为以下几点。首先,它提供了轻量级并且易用的API来有效的降低流数据的开发成本,之前要实现这类处理,需要使用Spark Streaming,Storm,Flink,或者自己编写Consumer。其次,它开发的应用程序可以支持在YARN,Mesos这类资源调度中,使用方式灵活。而对于异步操作,不是很友好,需要谨慎处理;另外,对SQL语法的支持有限,需要额外开发。
5.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉。