目录
由于项目需要,我整理了网上一些跟在线翻译有关的资料,做了一个整合Google和百度翻译的Demo程序。大概工作就是将Google翻译和百度翻译的Web在线版本功能移植PC客户端,用的是它们提供的一些翻译API(非付费)。功能简单,原理也不复杂,记下来希望能够帮助一些人。以下是截图:
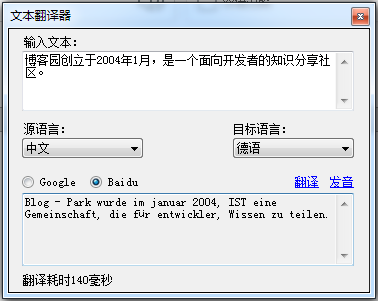
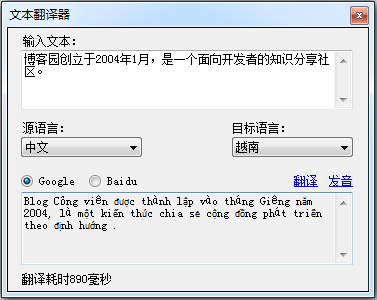
“麻雀虽小五脏俱全”,由于支持两种翻译方式,所以可以将一些共性抽象出来,放在一个独立的接口当中(假如以后扩展更多种翻译方式,也会方便很多)。我们定义一个“翻译接口”ITranslator,负责翻译的两个类分别为GoogleTranslator和BaiduTranslator。ITranslator接口代码如下:

1 /// <summary> 2 /// 翻译器接口 所有翻译器必须实现该接口 3 /// </summary> 4 interface ITranslator 5 { 6 /// <summary> 7 /// 翻译方法 8 /// </summary> 9 /// <param name="srcTxt"></param> 10 /// <param name="srcLanguage"></param> 11 /// <param name="desLanguage"></param> 12 /// <returns></returns> 13 string TranslateText(string srcTxt, string srcLanguage, string desLanguage); 14 /// <summary> 15 /// 翻译结果发音URL 16 /// </summary> 17 string TranslateSpeechURL 18 { 19 get; 20 } 21 /// <summary> 22 /// 所有支持的语言 23 /// </summary> 24 List<string> AllSupportedLanguages 25 { 26 get; 27 } 28 /// <summary> 29 /// 本次翻译耗时 30 /// </summary> 31 double TranslateTime 32 { 33 get; 34 } 35 }
两个翻译类(GoogleTranslator和BaiduTranslator)均实现该接口。UI界面直接依赖于ITranslator接口,不会直接依赖于两个具体的翻译类:
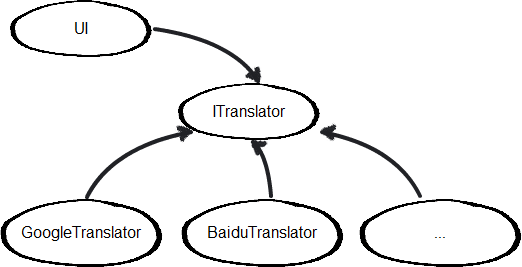
以上是“依赖倒置原则”最简单的应用场合。
使用很简单,定义一个ITranslator接口即可:
1 itranslator = new GoogleTranslator(); 2 //翻译 3 string translated_string = itranslator.TranslateText("我是一个地球人 ——来自Google的翻译", "中文", "英语"); 4 //翻译结果朗读URL 5 string speechURL = itranslator.TranslateSpeechURL; 6 //翻译耗时(毫秒) 7 int translate_time = (int)itranslator.TranslateTime; 8 9 itranslator = new BaiduTranslator(); 10 //翻译 11 translated_string = itranslator.TranslateText("我是一个地球人 ——来自百度的翻译", "中文", "德语"); 12 //翻译结果朗读URL 13 speechURL = itranslator.TranslateSpeechURL; 14 //翻译耗时(毫秒) 15 translate_time = (int)itranslator.TranslateTime;
后续如果有更多种翻译方式,可以参照GoogleTranslator和BaiduTranslator的实现。具体代码我就不贴了,源码中注释很详细。请求Web Server时用到了WebClient和WebRequest/WebResponse(前者较后者更高层、更抽象)。
- 由于有些词语并没有得到支持,所以翻译的朗读效果并不太好。
- 而且程序中是通过“http://tts.baidu.com/text2audio?lan=zh&ie=UTF-8&text=博客园”这种方式去加载音频文件的,如果语句太长,官方web版本中是分多次加载音频数据,但是程序中并没有做如此处理,所以可能抛出异常。
- 另外,音频是通过一个简单的WebBrowser控件加载的,在有些环境中,并不能直接朗读,需要打开系统自带的media palyer进行播放。
- 程序中在解析服务器返回来的Json数据时,并不严格(可以说是很随便)。建议实际使用过程中,可以采用专门的JSON解析工具。
作者:周见智
出处:http://www.cnblogs.com/xiaozhi_5638/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
分类:
.NET Framework
本文转自周见智博客博客园博客,原文链接:http://www.cnblogs.com/xiaozhi_5638/p/4514911.html,如需转载请自行联系原作者