LSTM入门学习
摘自:http://blog.csdn.net/hjimce/article/details/51234311
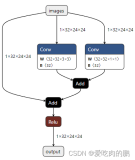
下面先给出LSTM的网络结构图:

看到网络结构图好像很复杂的样子,其实不然,LSTM的网络结构图无非是为了显示其高大上而已,这其实也是一个稍微比RNN难那么一丁点的算法。为了简单起见,下面我将直接先采用公式进行讲解LSTM,省得看见LSTM网络结构图就头晕。
(1)RNN回顾
先简单回顾一下RNN隐层神经元计算公式为:

其中U、W是网络模型的参数,f(.)表示激活函数。RNN隐层神经元的计算由t时刻输入xt,t-1时刻隐层神经元激活值st-1作为输入。总之说白了RNN的核心计算公式就只有上面这么简简单单的公式,所以说会者不难,难者不会,对于已经懂得RNN的人来说,RNN是一个非常简单的网络模型。
(2)LSTM前向传导
相比于RNN来说,LSTM隐层神经元的计算公式稍微复杂一点,LSTM隐藏层前向传导由下面六个计算公式组成,而且其中前4个公式跟上面RNN公式都非常相似:

首先需要先记住上面五个公式中输入变量的含义:
(1)输入变量:x(t)表示t时刻网络的输入数据,S(t-1)表示t-1时刻隐藏层神经元的激活值、C是一个记忆单元
(2)网络参数:U、W都是网络LSTM模型的参数,或者称之为权值矩阵
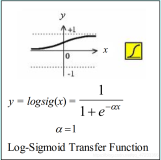
(3)σ表示sigmoid激活函数
(4)另外s(t)是t时刻,LSTM隐藏层的激活值
从上面的公式我们可以看出LSTM在t时刻的输入包含:X(t)、S(t-1)、C(t-1),输出就是t时刻隐层神经元激活值S(t)。LSTM前四个公式和RNN非常相似,模型都是:

这四个公式的输入都是x(t),s(t-1),每个公式各有各自的参数U、W。前面三个公式的激活函数选择s型函数,大牛门给它们起了一个非常装逼的名词,i、f、o分别称之为输入门、遗忘门、输出门;第4个公式选用tanh激活函数。
1、输入门
输入门可以控制你的输入是否影响你的记忆当中的内容。因变量为i,自变量为:输入数据x(t)、上一时刻隐藏层神经元激活值s(t-1),其采用S激活函数,输出的数值在0~1之间。如果从业余的角度来讲,可以把它看成是一个权值;当i为0的时候,表示当前时刻x(t)的信息被屏蔽,没有存储到记忆中。
2、遗忘门
遗忘门是来看你的记忆是否自我更新保持下去。因变量为f,自变量依旧为:
3、输出门
输出门是影响你的记忆是否被输出出来影响将来这三个们有一个特点:它们的输入数据都是x(t),上一时刻隐藏层的激活值s(t-1),另外这三个们
这种方式使你的记忆得到灵活的保持,而控制记忆如何保持的这些门本身是通过学习得到的,通过不同的任务学习如何去控制这些门。
三、源码实现
https://github.com/fchollet/keras/blob/master/keras/layers/recurrent.py
-
- x_i = K.dot(x * B_W[0], self.W_i) + self.b_i
- x_f = K.dot(x * B_W[1], self.W_f) + self.b_f
- x_c = K.dot(x * B_W[2], self.W_c) + self.b_c
- x_o = K.dot(x * B_W[3], self.W_o) + self.b_o
- i = self.inner_activation(x_i + K.dot(h_tm1 * B_U[0], self.U_i))
- f = self.inner_activation(x_f + K.dot(h_tm1 * B_U[1], self.U_f))
- c = f * c_tm1 + i * self.activation(x_c + K.dot(h_tm1 * B_U[2], self.U_c))
- o = self.inner_activation(x_o + K.dot(h_tm1 * B_U[3], self.U_o))
- h = o * self.activation(c)