在不同的公司的不同项目场景下,绝大多数情况下都需要维护一些基本的维度信息(也称为字典信息,下面全部使用维度信息代替描述),比如旅游相关的网站,可能会维护:
- 货币类型:美元,人民币,港币等
- 航程类型:单程,双程等
- 产品线:机票、酒店、度假等
诸如此类的维度信息。而且往往这些维度信息可能不同的业务部门都需要使用全部或者其中的某些的某些。因此随着时间的推移,这些维度类型可能会新增,修改,删除某些项。导致不同部门维护的维度信息不同,但是往往公司中的部门不是独立存在的,往往都需要互相交互。因此会涉及到维度信息的转换。
我们都知道统一维度的重要性,这一点怎么强调都不为过。但是往往现实是存在太多的维度不统一的场景了,在维度已经不统一的情况下,我们应该如何去逐步改善这些场景。
因此本文主要着眼于我在实际工作中遇到过的问题,做一个总结,希望对大家有帮助。
维度信息的使用
一般我们是如何使用维度信息的呢?比较通用的解决办法往往是:
- 数据库中创建字典表
- 代码中创建对应的ENUM
我想绝大多数项目应该都是这样来解决维度信息的存储和使用问题的。但是有以下的一些注意点:
维度信息维护面临的数据一致性问题
这种使用方式往往会存在什么问题呢?假设有3中类型的维度信息:A、B、C:
第一个问题:系统1仅仅使用了维度A,而系统2使用了维度A和维度B,系统3使用了维度B和维度C。
而系统1、系统2、系统3都有自己的数据库。请问这个使用,这些维度信息的字典表建立在哪个系统的数据库中?还是说每个系统都建立一份字典表?
第二个问题:结合第一个问题,同样,往往每个系统都会有对应一个或者若干个工程项目,这些维度信息是哪些系统用到了就创建对应的枚举,还是统一维护一个工程,把所有的维度枚举都写在里面,统一维护?
上面的2个问题,其实是同一个问题,就是数据的一致性问题。当同一类信息存在的地方越多,一致性的问题越显著。也越需要迫切的解决。因为如果不及时有效的解决的话,系统中会存在各种各样的Adapter来进行维度信息的转换工作。
我们的解决办法:
- 每个系统使用那些维度信息,就会有一张对应的维度字典表
- 专门有一个工程或者说jar包,将部门内部所有的维度信息的枚举类收集在一起
- 考虑到之前的一些历史项目的维度信息和现在的标准的维度信息不统一,因此在上面的jar中统一提高了维度转换适配器。
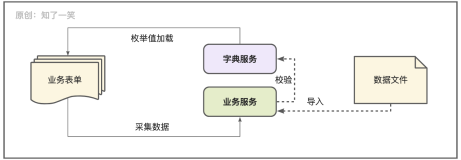
- 同时会有一个专门的维度维护系统,对应一个数据库数据库:里面记录着所有的维度字典表。同时记录了哪些系统的数据库中有哪些维度表,同时这个系统提供了维护界面。
- 然后后续新增的维度直接和平台的维度一一对应。接着逐步修正之前的维度数据。
这样当新增,或者修改维度信息的时候,我们会在「维度维护系统」的界面上进行维度信息的新增、修改操作。然后根据上面第四条描述的,根据维度系统的数据库中记录的“哪些系有哪些维度表”的对应关系,然后程序自动新增、修改这些周边系统的维度字典表数据。
当然当新增一种之前不存在的维度信息的时候,一开始只会在「维度维护系统」的数据库中创建,然后哪些系统需要使用,就同步哪些系统。
数据库维护以后,然后更新升级我们的jar包就可以了。
通过这种方式我们在很大的程度上解决了维度信息的不一致问题。
维度字典表的设计问题
为了方便开发人员统计每个系统有哪些字典表,我们在设计字典表的表名称的时候,统一采用了:_dict结尾。比如产品线字典表的表名为:product_line_dict
为了方便程序处理,我们也统一了表的格式:
use test;
set names utf8mb4;
create table product_line_dict(
id int(10) unsigned not null auto_increment comment '维度序号',
code varchar(32) not null comment '维度编号',
name varchar(32) not null comment '维度名称',
primary key(id),
unique key uniq_idx_code(code)
)engine=innodb default charset=utf8mb4 comment '产品线维度表';比如对于上面提到的product_line_dict表:
id code name
1 flight 机票其中id为表的主键,code列加唯一索引。另外系统说明的是表级别的comment注释都是必须要写清楚的。这样方便新人阅读数据库表。
比起字典表只有:id、name这两列来说,这样的好处是:
- 将枚举中的code和数据库中的code统一起来
- 和部门外系统交互的时候,接口中只给code就好了,比只给id更加清洗