内存中OLTP是关于内存中的一切。但那只是对了一半。在今天的文章里我想给你展示下,当你从内存读取数据时,即使内存中OLTP也会引起磁盘活动。这里的问题是执行计划里,不正确的统计信息与排序(sort)运算符的组合。
排序(sort)运算符问题
我们都知道,排序(sort)运算符需要所谓的内存授予(Memory Grant)来作它的运行。内存区域是用来进行执行计划里到来记录的排序。内存授予的大小是基于估计行数数量。在基数计算(Cadinality Estimation)期间查询优化器估计执行计划里每个运算符的预计行数。
我在今年6月写了篇文章,展示了当估计错误时,排序(sort)运算符如何能溢出到TempDb。在内存中OLTP里同样的事情会发生:当估计行数错误时,在执行计划里有排序(sort)运算符,排序(sort)运算符会溢出到TempDb!我们来重现这个情形。
内存中OLTP溢出到TempDb
我们新建一个有内存中OLTP文件组配置的新数据库。

1 -- Create new database 2 CREATE DATABASE HashCollisions 3 GO 4 5 -- Add MEMORY_OPTIMIZED_DATA filegroup to the database. 6 ALTER DATABASE HashCollisions 7 ADD FILEGROUP InMemoryOLTPFileGroup CONTAINS MEMORY_OPTIMIZED_DATA 8 GO 9 10 USE HashCollisions 11 GO 12 13 -- Add a new file to the previously created file group 14 ALTER DATABASE HashCollisions ADD FILE 15 ( 16 NAME = N'InMemoryOLTPContainer', 17 FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.SQL2014\MSSQL\DATA\InMemoryOLTPContainer' 18 ) 19 TO FILEGROUP [InMemoryOLTPFileGroup] 20 GO
下一步我创建新的内存优化表:
1 -- Create a test table 2 CREATE TABLE Table1 3 ( 4 Column1 INT IDENTITY, 5 Column2 INT 6 CONSTRAINT pk_Column1 PRIMARY KEY NONCLUSTERED HASH (Column1) WITH (BUCKET_COUNT = 1) 7 ) WITH 8 ( 9 MEMORY_OPTIMIZED = ON, 10 DURABILITY = SCHEMA_ONLY 11 ) 12 GO
从表定义可以看到,我在Column1列创建了1个哈希索引。因为它是个哈希索引,你也需要指定哈希表上你想拥有的哈希桶数。这里我指定了1个哈希桶,这是个非常,非常糟的做法。当你往表里插入记录时,因为只有1个哈希桶,你会得到巨大数量的哈希冲突(hash collisions)。一般来说,在你定义你的哈希索引的列上,哈希桶数应该和你列上的唯一值个数一致。下面代码往刚才创建的表里插入14001条记录。
1 -- Insert 14001 records 2 INSERT INTO Table1(Column2) VALUES (1) 3 4 SELECT TOP 14000 IDENTITY(INT, 1, 1) AS n INTO #Nums 5 FROM 6 master.dbo.syscolumns sc1 7 8 INSERT INTO Table1 (Column2) 9 SELECT 2 FROM #nums 10 DROP TABLE #nums 11 GO
你可以通过DMV sys.dm_db_xtp_hash_index_stats查看哈希冲突数。从这个DMV的输出可以看到,你有14001条记录在这个且唯一的哈希索引的哈希桶上。现在我们来运行执行计划里有排序(sort)运算符的SELECT语句。
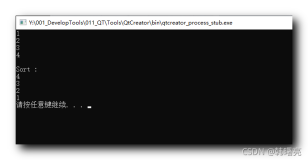
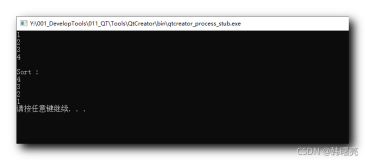
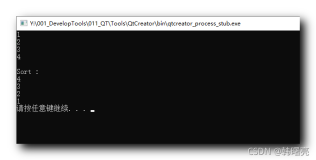
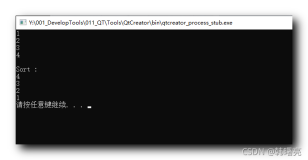
1 -- The sort operator in this execution plan spills over to TempDb! 2 SELECT * FROM Table1 3 ORDER BY Column1
现在当你查看执行计划时,你会看到排序运算符已经溢出到TempDb。

这是因为哈希索引上不正确的统计信息才发生的。当你查看执行计划里Index Scan (NonClusteredHash) 运算符属性时,你会看到查询优化器从我们的哈希索引上估计行数为1,实际我们返回了140001行。

Index Scan (NonClusteredHash) 运算符的估计总是基于哈希表里哈希桶数。查询优化器这里做出的假设是你没有哈希冲突(hash collisions)——这在这里是不正确的。因此对排序运算符的内存授予是根据那个不正确的估计作为标准,这就会溢出到TempDb。在我的系统里这个查询运行了近80毫秒,对于内存中技术来说这个算很长时间了。
你如何修正这个问题?删除你的表,在哈希索引里仔细计划哈希桶数。欢迎来到内存中OLTP的精彩世界……
小结
当你使用内存中OLTP的哈希索引时,你要对你的哈希所用仔细设计你的哈希桶数。当它们错误时,是伤及性能。我已经在1个月前,写了篇文章描述哈希冲突(hash collisions)如何伤及内存中OLTP的性能——即使没有溢出到TempDb!
从中我们可以看出:在哈希索引有哈希冲突的话,你用内存中OLTP的话不能期望得到惊艳的快速性能,因为它们带来巨大的负担且影响基数计算。
本文转自Woodytu博客园博客,原文链接:http://www.cnblogs.com/woodytu/p/4709730.html,如需转载请自行联系原作者