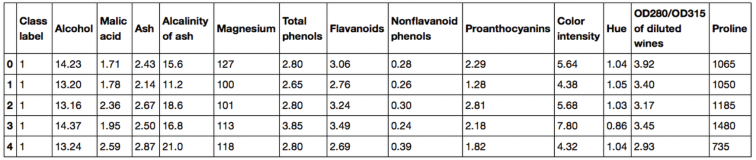
最近学习特征工程(Feature Enginnering)的相关技术,主要包含两块:特征选取(Feature Selection)和特征抓取(Feature Extraction)。这里记录一些要点,作为备忘。
特征选取
Algorithms for wrapping classifiers and search attribute subset space: best.first.search, backward.search, forward.search, hill.climbing.search
R中的FSelector包实现了一些特征选取的算法,主要分两大类:
Algorithms for filtering attributes: cfs, chi.squared, information.gain, gain.ratio, symmetrical.uncertainty, linear.correlation, rank.correlation, oneR, relief, consistency, random.forest.importance
属性过滤器:直接通过一些统计指标,计算变量与y的关系,然后根据一定规则选取理想的值。
Algorithms for wrapping classifiers and search attribute subset space: best.first.search, backward.search, forward.search, hill.climbing.search
分类器包装:通过包装特定的分类/回归算法,并使用一些通用的优化算法,选取具有最有效果的属性组合。
属性过滤器可能效率更高,但是效果不直接。而分类包装器可能效果更直接,但是计算开销大。
特征抓取
主要是重已有的数据中,创建新的数据。
Design Userful Features这篇文章,通过轴承的例子,从三个方面描述了特征抓取的方法,
- 领域知识:这点最好与领域专家一起讨论
- 统计量:无需领域知识,通用的统计量,如均值,中位数,分位数,最大最小值,偏度,峰度等
- 数据可视化:通过闪点图,分布度等方法,找到特殊的特殊性,创建feature。可视化之前需要预处理数据,如傅里叶变化,PCA,查看原始数据等。
参考
- R FSelector包说明文档
- R caret包,参考文章 Feature Selection
- 论文 An Introduction to Variable and Feature Selection, by Andre Elisseeff
- 使用快速傅里叶变化进行feature提取的例子
- 知乎:傅里叶变换掐死教材
声明:如有转载本博文章,请注明出处。您的支持是我的动力!文章部分内容来自互联网,本人不负任何法律责任。
本文转自bourneli博客园博客,原文链接:http://www.cnblogs.com/bourneli/p/4106605.html
,如需转载请自行联系原作者