1.哈希函数
(1)哈希函数即散列函数
哈希函数的输入域可以是非常大的范围,
但是输出域是固定范围。
(2)哈希函数的性质:
a.典型的哈希函数都有无线的输入值域
b.输入值相同时,返回值相同,返回值即哈希值
c.输入值不同时,返回值可能一样,也可能不一样
d.不同输入值得到的哈希值,整体均匀的分布在输出域s上。(重要)
前三点性质是哈希函数的基础,最后一点是评价一个哈希函数优劣的关键。
(3)无论哈希函数设计有多么精细,都会产生冲突现象,也就是2个关键字处理函数的结果映射在了同一位置上,因此,有一些方法可以避免冲突。
一个优秀的哈希函数可以使不同输入值得到的哈希值均匀分布,哈希值越均匀的分布在s上,该哈希函数越优秀。
这种均匀分布与输入值无关,比如"aaa1","aaa2","aaa3",虽然相似,但一个优秀的哈希函数计算出的哈希值应该差异巨大。
这样s(输出域)对%m后的结果,也会均匀的分布在0~m-1这个值域上。这一点在哈希函数的应用中是非常重要的。
2.介绍Map-Reduce
把大任务分成两个阶段的过程。
(1)Map阶段
通过哈希函数把任务分成若干的子任务,哈希函数会是系统自带的,或者用户指定的。
相同哈希值的任务会被分配到一个节点上进行处理。在分布式系统中,一个节点可以是一个计算节点,也可以是一台计算机。
(2)Reduce阶段
分开处理,然后合并结果的阶段。
(3)Map-Reduce的原理简单,但工程上的实现会遇到很多问题
a.备份的考虑,分布式存储的设计细节,以及容灾策略
b.任务分配策略与任务进度跟踪的细节设计,以及节点状态的呈现
c.分布式系统多用户权限的控制
3.用Map-Reduce方法统计一篇文章中每个单词出现的个数
(1)首先把文章进行预处理,最终目标是得到一个连续的单词字符串输入
比如去掉文章中的标点符号;对连字符"-"的处理,如pencil-box,和换行处的连字符;对于缩写的处理,如I’m、don’t等等;大小写的转换等
(2)现在输入是只包含单词的文本,进入map阶段
对每个单词都生成词频为1的记录。比如(dog,1)、(pig,1)等。
此时一个单词可能有多个词频为1的记录,比如说可能有多个(dog,1)的记录。
(3)然后通过哈希函数,得到每个单词的哈希值,并根据该值分成若干组任务
根据哈希函数的性质我们知道,单词相同的记录会被分配到一起。
(4)进入Reduce阶段。
在子任务中,同一种单词的词频进行合并,最后得到所有记录并统一合并。因为每个子任务都是并行处理的,所以效率会比较高。
4.常见海量数据处理题目解题关键
(1)分而治之。通过哈希函数将大任务分流到机器,
或分流成小文件,在每一个小部分上进行处理,然后再把结果合并起来
(2)常用hashmap、bitmap等数据结构
(3)难点其实是通讯、时间和空间的估算
5.bitmap解决大数据量文件排序
请对10亿个IPV4的ip地址进行排序,每个ip只会出现一次。每个ip只会出现一次。
IPv4中规定IP地址长度为32(按TCP/IP参考模型划分) ,即有2^32-1个地址。
IPv6协议的地址长度是128位,全部可分配地址数为2的128次方(2^128)个
(1)普通方法
IPV4的ip数量大概42亿,诸如172.18.24.40,每个ip地址可以转换为对应的无符号整数,
可以直接把这10亿个ip地址全部转换成数字,然后把这10亿个数字排序后再转换会ip地址即可。
1个ip地址占据32bit,也就是4Byte,也就是说存储着10亿个整数需要40亿字节空间,大概是
4(Gb),000(Mb),000(Kb),000(Byte),也就是需要4Gb内存,
在目前的机器上这个方法是可以执行的,但是通过bitmap可以有更优化的方法。
(2)bitmap方法
申请一个长度为2^32的bit类型的数组,每个位置上是一个bit,只可表示0或者1两种状态,空间大概为2^29字节,大约512Mb。
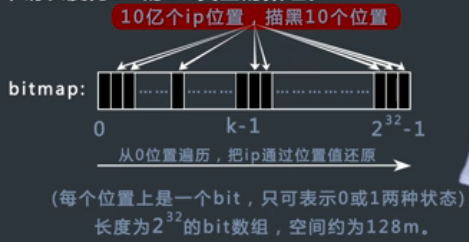
如果整数1出现,就把bitmap对应的位置从0变到1,这个数组可以表示任意一个(注意是一个)32位无符号整数是否出现过,
然后把10亿个ip地址全部转换成整数,相应的在bitmap中相应的位置描黑即可,
最后只要从bitmap的零位一直遍历到最后,然后提取出对应不为0位的整数,再转换成ip地址,就完成了从大到小的排序。
6.桶排序处理大数据
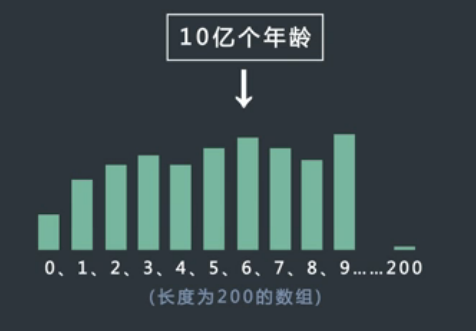
请对10亿的年龄进行排序。
年龄在0~200之间,然后用一个足够大的数组,对10亿个数据进行计数排序就可以了。
7.哈希函数分流加哈希表解决Top K问题
有一个包含20亿个全是32位整数的大文件,在其中找到出现次数最多的数。内存限制为2G。
(1)通常的方法
使用哈希表做词频统计,key记录具体某一个整数,value记录这个整数出现的次数,最后统计即可。
首先看一下哈希表结构如何设计,key就是32位整数,4字节
4字节,32位<——整型<——key——>具体某一个整数
假设极端情况一个整数出现了20亿次,那么value可能的最大值是20亿,
即2^31,也需要用4字节保存
4字节,31位<<——value——>这个整数出现的次数
所以哈希表每条记录占据8字节,20亿数据需要占据16G空间,一次性可能会超出内存限制,现在对这个方法进行改进。
(2)分而治之的方法
把包含20亿个数的大文件中的每一个数使用哈希函数分流,把大文件分成若干个小文件,假设有16个小文件。
同一种数不会被分流到不同文件,这是哈希函数的性质决定的,对不不同的数,每个文件中含有整数的种数几乎一样,这也是哈希函数的性质决定的。
然后用哈希表统计每个小文件中每种数出现的次数,此时肯定不会出现溢出,现在就得到了每个小文件中出现次数最多的数,然后把这每个小文件的出现最多的数进行比较,就可以得到结果。
大数据题目的一个特点是,通过哈希函数不断分流,来解决内存限制的问题。
8.分治+桶思想+bitmap解决大数据中元素是否出现问题
32 位无符号整数的范围是0~4294967295 。现在有一个正好包含40亿个无符号整数的文件,所以在整个范围中必然有没有出现过的数,可以使用最多10M的内存,只用找到一个没出现过的数即可,该如何找?
(1)使用哈希表
key——>具体某一个整数(32bit),value——>这个整数是否出现(1bit),
每条记录至少需要4字节,假设40亿条数据全部不相同,40亿条记录占据160亿字节,即需要16G内存,肯定不可以。
(2)使用bitmap
申请一个长度为2^32的bit类型的数组,这个数组需要2^29Byte,即512Mb空间,依然不符合要求
(3)桶排序思想,数字范围分成若干个桶
0~2^32-1范围分成64个区间,每个区间应该装下2^32/64的数,总共的范围为42亿,一共有40亿个数字,肯定有区间计数不足2^32/64,只要找到一个区间,在这个区间肯定有没出现过的数。假设这个区间为A,接下来在再对这个区间的范围构造bitmap,需要占用空间为512/64Mb,然后再遍历这40亿个数字,最后考察bitmap上哪个没出现即可。
首先根据内存限制,确定分成多少个空间,然后利用区间计数的方式,找到哪个区间计数不足,
对这个区间上的数利用bitmap即可。
9.哈希分流+哈希表词频统计+小根堆和外排序解决Top K问题
某搜索公司一天的用户搜索词汇是海量的,假设有百亿的数据量,请设计一种求出每天最热100词的可行办法。
10.一致性哈希,解决节点数量改变导致哈希函数分流手段失效的问题
11.算术运算的操作符
+ - * / %(模)
位运算的操作符
& 按位与
| 按位或
^ 按位异或
~ 取反
<< 左移右侧补0
>> 右移左侧补符号位
>>> 右移左侧补0
12.布隆过滤器
100亿个不安全的网页黑名单,每个网页的URL最多占用64字节,
现在想要实现一种网页过滤系统,可以根据网页的URL判断该网页是否在黑名单上,
要求该系统允许有万分之一以下的判断失误率,并且使用的额外空间不要超过30G。
如果把黑名单——>哈希表或者数据库
(1)如果遇到网页黑名单系统,垃圾邮件过滤系统,爬虫的网址判断重复系统,
又看到系统容忍一定的失误率,但是对空间有严格要求,
很可能是需要使用布隆过滤器的知识求解。
(2)布隆过滤器可以精确的代表一个集合,
可以精确判断某一元素是否在此集合中,精确程度由用户的具体设计决定,做到100%的精确即正确是不可能的。
13.考虑如何不用额外变量,交换两个整数的值?
使用位运算。
补充:2的幂表
| 2的幂 | 准确值 | 近似值 | 对应的字节(Byte)转换成MB/GB等 | 常见的场景 |
| 7 | 128 | |||
| 8 | 256 | |||
| 9 | 512 | |||
| 10 | 1024 | 一千 | 1K | |
| 16 | 6 5536 | 64K | ||
| 20 | 104 8576 | 一百万 | 1MB | |
| 30 | 10 7374 1824 | 1GB | ||
| 32 | 42 9496 7296 | 42亿多 | 4GB | IPV4地址长度 |
| 40 | 1 0995 1162 7776 | 一万亿 | 1TB |
本文转自邴越博客园博客,原文链接:http://www.cnblogs.com/binyue/p/5222710.html,如需转载请自行联系原作者
