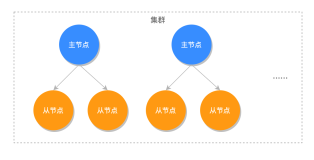
什么是 Redis 集群
分布式(distributed)
容错(fault-tolerant)
是普通单机 Redis 所能使用的功能的一个子集(subset)。
集群的容错功能:
主节点和从节点使用完全相同的服务器实现, 它们的功能(functionally)也完全一样, 但从节点通常仅用于替换失效的主节点。
如果不需要保证“先写入,后读取”操作的一致性(read-after-write consistency), 那么可以使用从节点来执行只读查询。
Redis 集群实现的功能子集
Redis 集群支持所有处理单个数据库键的命令。
不支持多个数据库键的复杂计算操作, 比如集合的并集操作、合集操作。
Redis 集群不支持多数据库功能,只是用默认 0 号数据库。
不能使用 SELECT 命令。
Redis 集群协议中的客户端和服务器
Redis 集群中的节点包含如下功能:
持有键值对数据。
记录集群的状态,包括键到正确节点的映射(mapping keys to right nodes)。
自动发现其他节点,识别工作不正常的节点,并在有需要时,在从节点中选举出新的主节点。
节点间通过 TCP 连接建立联系,使用二进制协议进行通讯。
节点之间使用 Gossip 协议来进行通信:
传播(propagate)关于集群的信息,以此来发现新的节点。
向其他节点发送 PING 数据包,以此来检查目标节点是否正常运作。
在特定事件发生时,发送集群信息。
title: ASK转向和MOVED转向
客户端->node1:发送处理命令
node1->客户端:failover,返回 `-MOVED` 或者 `-ASK` 转向(redirection)错误
客户端->node2:发送处理命令(如果返回命令指定发送节点,则发送到指定节点)
理论上来说, 客户端是无须保存集群状态信息的
客户端可以将键和节点之间的映射信息保存起来,可以有效地减少可能出现的转向次数,以提升命令执行的效率。
键分布模型
Redis 集群的键空间被分割为 16384 个槽(slot)
集群的最大节点数量也是 16384 个。
推荐的最大节点数量为 1000 个左右。
将键映射到slot的算法:
HASH_SLOT = CRC16(key) mod 16384
集群节点属性
节点ID是一个十六进制表示的 160 位随机数,第一次启动时由操作系统 /dev/urandom 生成。
节点所使用的 IP 地址和 TCP 端口号。
节点的标志(flags)。
节点负责处理的哈希slot。
节点最近一次使用集群连接发送 PING 数据包(packet)的时间。
节点最近一次在回复中接收到 PONG 数据包的时间。
集群将该节点标记为下线的时间。
该节点的从节点数量。
如果该节点是从节点的话,那么它会记录主节点的节点 ID 。 如果这是一个主节点的话,那么主节点 ID 这一栏的值为 0000000 。
节点握手
节点总是应答(accept)来自集群连接端口的连接请求, 并对接收到的 PING 数据包进行回复
所有 PING 数据包都会接收并回复,不管 PING 命令是否来自集群节点内部;非集群节点 PING 数据包则会拒绝。
是否同属于一个节点的判断方法:
1、节点在收到管理员显式地向它发送 CLUSTER MEET ip port 命令时,向另一个节点发送 MEET 信息,来强制让接收信息的节点承认发送信息的节点为集群中的一员。
2、 如果一个可信节点向另一个节点传播第三者节点的信息,那么接收信息的那个节点也会将第三者节点识别为集群中的一员。
MOVED 转向
如果在处理某个命令时查找到key所属的槽不是由该节点处理的话,节点将查看自身内部所保存的哈希slot到节点 ID 的映射记录, 并向客户端回复一个 MOVED 错误。
注意, 当集群处于稳定状态时:
所有客户端最终都会保存有一个哈希slot至节点的映射记录(map of hash slots to nodes),使得集群非常高效:
客户端可以直接向正确的节点发送命令请求, 无须转向、代理或者其他任何可能发生单点故障(single point failure)的实体(entiy)。
集群在线重配置(live reconfiguration)
Redis 集群支持在集群运行的过程中添加或者移除节点。
节点的添加操作和节点的删除操作类似,都是将哈希slot从一个节点移动到另一个节点。
命理负责管理集群节点的slot转换表(slots translation table)。
CLUSTER 命令可用的子命令:
指派节点: CLUSTER ADDSLOTS slot1 [slot2] ... [slotN]
删除节点: CLUSTER DELSLOTS slot1 [slot2] ... [slotN]
将指定的slot指派给node节点: CLUSTER SETSLOT slot NODE node
将给定节点node中的slot迁移出节点:CLUSTER SETSLOT slot MIGRATING node
将给定slot导入到节点node: CLUSTER SETSLOT slot IMPORTING node
title: ASK转向和MOVED转向
客户端->node1
node1->node1:MIGRATING,迁出状态
客户端->node1:当节点是MIGRATING状态时,仍然会接收命令
node1->node1:MIGRATING,slot仍在该节点则处理
node1->node1:MIGRATING,slot已经迁移
node1->客户端:返回一个 `-ASK` 转向(redirection)错误
客户端->node2:IMPORTING,导入状态
客户端->node2:发送命令,会拒绝
node2->客户端:拒绝
node2->node2:收到 `ASKING` 命令后
客户端->node2:才会接受关于这个槽的命令请求。
node2->node2:处理请求
node2->客户端:返回结果
node1->node1:迁移完成
客户端->node1:发送命令
node1->客户端:发送MOVE转向命令,完成长期转向
客户端->node2:后续命令均会发送到新的节点中
注意事项:尽管 MIGRATE 非常高效, 对一个键非常多、并且键的数据量非常大的集群来说, 集群重配置还是会占用大量的时间, 可能会导致集群没办法适应那些对于响应时间有严格要求的应用程序。
ASK 转向
ASK转向和MOVE转向的区别:
ASK 转向仅仅在下一个命令请求中转向至另一个节点。
MOVE 转向则是长期转向另一个节点。
操作步骤见 MOVE 转向
容错
节点失效检查办法
一个节点要将另一个节点标记为失效, 必须先询问其他节点的意见, 并且得到大部分主节点的同意才行。
title:节点失效检查办法
node1->node2:发送PING命令
node1->node1:超时未收到回复
node1->node1:将node2标记为`PFAIL`
node1->nodeN:随机地广播三个已知节点
nodeN->node1:返回节点状态报告,node2 FAIL
node1->node1:大部分节点标记 node2 FAIL
node1->nodeOther:集群广播该节点失效
nodeOther->nodeOther:node2失效
移除节点的 FAIL 状态:
如果被标记为 FAIL 的是从节点, 那么当这个节点重新上线时, FAIL 标记就会被移除。
如果一个主节点被打上 FAIL 标记之后, 经过了节点超时时限的四倍时间, 再加上十秒钟之后, 针对这个主节点的槽的故障转移操作仍未完成, 并且这个主节点已经重新上线的话, 那么移除对这个节点的 FAIL 标记。
当节点不可用或者某个slot不能正常使用,整个集群会停止处理任何命令。
集群进入FAIL状态的两种情况:
至少有一个哈希槽不可用,因为负责处理这个槽的节点进入了FAIL状态。
集群中的大部分主节点都进入下线状态。当大部分主节点都进入PFAIL状态时,集群也会进入 FAIL 状态。
从节点选举
一个从节点要提升为主节点需要满足如下条件:
这个节点是已下线主节点的从节点。
已下线主节点负责处理的槽数量非空。
从节点的数据被认为是可靠的, 也即是, 主从节点之间的复制连接(replication link)的断线时长不能超过节点超时时限(node timeout)乘以 REDIS_CLUSTER_SLAVE_VALIDITY_MULT 常量的积。
title:节点选举
nodeMaster1->nodeMaster1: 下线
nodeMaster1->nodeMaster1: slot数量非空
nodeMaster1->nodeSlave1:
nodeSlave1->nodeSlave1: 断线时长不能超过节点超时时限(node timeout)乘以\n REDIS_CLUSTER_SLAVE_VALIDITY_MULT 的积。
nodeSlave1->nodeOtherMaster: 是否允许升级为新的主节点
nodeOtherMaster->nodeOtherMaster: nodeSlave1 是一个从节点,\n并且它所属的主节点处于FAIL状态
nodeOtherMaster->nodeOtherMaster: nodeSlave1 从节点的节点ID所在主节点下\n所有从节点中最小的
nodeOtherMaster->nodeOtherMaster: nodeSlave1 状态正常
nodeOtherMaster->nodeSlave1: 大部分节点授权 nodeSlave1 成为主节点
nodeSlave1->nodeSlave1: 执行故障转移
nodeSlave1->nodeOtherMaster: 通过 PONG 数据包(packet)告知其他节点,\n这个节点现在是主节点了。
nodeSlave1->nodeOtherMaster: 通过 PONG 数据包告知其他节点,\n这个节点是一个已升级的从节点(promoted slave)。
nodeSlave1->nodeSlave1: 接管 nodeMaster1 下线的所有slot
nodeSlave1->nodeOtherMaster: 显式地向所有节点广播一个 PONG 数据包
nodeSlave1->nodeSlave1: 该主节点下所有 slot 均会被更新,
nodeSlave1->nodeSlaveOther: 所有从节点会察觉到 PROMOTED 标志,\n并开始对新的主节点(nodeSlave1)进行复制。
nodeSlave1->nodeMaster1: 上线,则将自身调整为现任主节点的从节点。
本文转自秋楓博客园博客,原文链接:http://www.cnblogs.com/rwxwsblog/p/7449801.html,如需转载请自行联系原作者