Mahout中实现的推荐算法是协同过滤,而无论是UserCF还是ItemCF都依赖于user相似度或item相似度。本文是对mahout中的一些相似度算法的解读。
Mahout相似度相关类关系如下:
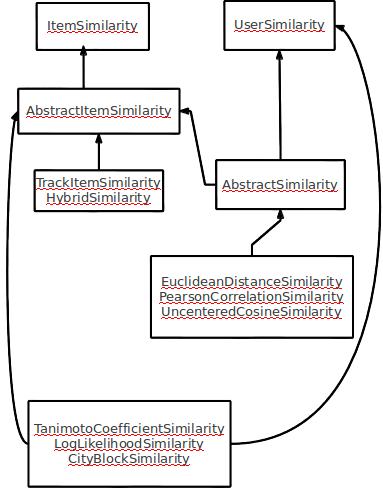 有点乱(^.^)
有点乱(^.^)
从上图可看出,Mahout主要针对用户相似度和物品相似度的计算,并且除了HybridSimilarity之外全都能够用于计算user和item两者的相似度,只有HybridSimilarity只能计算item相似度。接来下分三部分进行分析:继承AbstractSimilarity的,没有集成AbstractSimilarity但是也可以用于user、item相似度计算的,只继承AbstractItemSimilarity的。
继承AbstractSimilarity的实现类
以下这些类用于无偏好值的用户行为数据。
在介绍EuclideanDistanceSimilarity、PearsonCorrelationSimilarity、UncenteredCosineSimilarity之前,让我们先了解一下AbstractSimilarity。其实AbstractSimilarity才是这一部分的核心,三个重要方法:userSimilarity()、itemSimilarity()、computeResult(),其中computeResult()是抽象方法,是供给子类去实现的,userSimilarity()、itemSimilarity()中会在计算好相应变量之后调用子类实现的computeResult(),得到的结果在经过处理之后就是相似度。
在userSimilarity()中,会先计算
user1对物品X偏好值的和sumX以及平方和sumX2、user2对物品Y的偏好值的和sumY以及平方和sumY2、user1与user2的物品的偏好值的乘积sumXY、user1(item1)与user2(item2)的偏好值的平方差sumXYdiff2。代码如下:
sumXY += x * y;
sumX += x;
sumX2 += x * x;
sumY += y;
sumY2 += y * y;
double diff = x - y;
sumXYdiff2 += diff * diff;
count++;
其中如果一个user没有对某个item的偏好而另一个user有对这个item的偏好,那么会使用PreferenceInferrer实现类对进行推测,代码如下:
// Only one user expressed a preference, but infer the other one's preference and tally
// as if the other user expressed that preference
if (compare < 0) {
// X has a value; infer Y's
x = hasPrefTransform
? prefTransform.getTransformedValue(xPrefs.get(xPrefIndex))
: xPrefs.getValue(xPrefIndex);
y = inferrer.inferPreference(userID2, xIndex);
} else {
// compare > 0
// Y has a value; infer X's
x = inferrer.inferPreference(userID1, yIndex);
y = hasPrefTransform
? prefTransform.getTransformedValue(yPrefs.get(yPrefIndex))
: yPrefs.getValue(yPrefIndex);
}
然后会调用computeResult()方法,代码如下:
// "Center" the data. If my math is correct, this'll do it.
double result;
if (centerData) {
double meanX = sumX / count;
double meanY = sumY / count;
// double centeredSumXY = sumXY - meanY * sumX - meanX * sumY + n * meanX * meanY;
double centeredSumXY = sumXY - meanY * sumX;
// double centeredSumX2 = sumX2 - 2.0 * meanX * sumX + n * meanX * meanX;
double centeredSumX2 = sumX2 - meanX * sumX;
// double centeredSumY2 = sumY2 - 2.0 * meanY * sumY + n * meanY * meanY;
double centeredSumY2 = sumY2 - meanY * sumY;
result = computeResult(count, centeredSumXY, centeredSumX2, centeredSumY2, sumXYdiff2);
} else {
result = computeResult(count, sumXY, sumX2, sumY2, sumXYdiff2);
}
最后,在经过SimilarityTransform和normalizeWeightResult()两步处理,result就是求得的user1与user2的相似度数值。代码如下:
if (similarityTransform != null) {
result = similarityTransform.transformSimilarity(itemID1, itemID2, result);
}
if (!Double.isNaN(result)) {
result = normalizeWeightResult(result, count, cachedNumUsers);
}
1.PearsonCorrelationSimilarity
基于皮尔森相关性的相似度计算:sumXY / sqrt(sumX2 * sumY2),代码如下:
@Override
double computeResult(int n, double sumXY, double sumX2, double sumY2, double sumXYdiff2) {
if (n == 0) {
return Double.NaN;
}
// Note that sum of X and sum of Y don't appear here since they are assumed to be 0;
// the data is assumed to be centered.
double denominator = Math.sqrt(sumX2) * Math.sqrt(sumY2);
if (denominator == 0.0) {
// One or both parties has -all- the same ratings;
// can't really say much similarity under this measure
return Double.NaN;
}
return sumXY / denominator;
}
2.EuclideanDistanceSimilarity
基于欧几里德距离的相似度计算:1 / (1 + distance),代码如下:
@Override
double computeResult(int n, double sumXY, double sumX2, double sumY2, double sumXYdiff2) {
return 1.0 / (1.0 + Math.sqrt(sumXYdiff2) / Math.sqrt(n));
}
3.UncenteredCosineSimilarity
基于余弦的相似度计算,代码如下:
@Override
double computeResult(int n, double sumXY, double sumX2, double sumY2, double sumXYdiff2) {
if (n == 0) {
return Double.NaN;
}
double denominator = Math.sqrt(sumX2) * Math.sqrt(sumY2);
if (denominator == 0.0) {
// One or both parties has -all- the same ratings;
// can't really say much similarity under this measure
return Double.NaN;
}
return sumXY / denominator;
}
继承AbstractItemSimilarity并实现AbstractItemSimilarity的类
以下这些类用于无偏好值的用户行为数据。
1.TanimotoCoefficientSimilarity
基于谷本系数的相似度:userID1的偏好物品与userID2的偏好物品的交集size/并集size(item与其类似),代码如下:
public double userSimilarity(long userID1, long userID2) throws TasteException {
DataModel dataModel = getDataModel();
FastIDSet xPrefs = dataModel.getItemIDsFromUser(userID1);
FastIDSet yPrefs = dataModel.getItemIDsFromUser(userID2);
int xPrefsSize = xPrefs.size();
int yPrefsSize = yPrefs.size();
if (xPrefsSize == 0 && yPrefsSize == 0) {
return Double.NaN;
}
if (xPrefsSize == 0 || yPrefsSize == 0) {
return 0.0;
}
//计算交集的size
int intersectionSize =
xPrefsSize < yPrefsSize ? yPrefs.intersectionSize(xPrefs) : xPrefs.intersectionSize(yPrefs);
if (intersectionSize == 0) {
return Double.NaN;
}
//计算并集size
int unionSize = xPrefsSize + yPrefsSize - intersectionSize;
return (double) intersectionSize / (double) unionSize;
}
2.LogLikelihoodSimilarity
基于对数似然的相似度:基于谷本系数的相似度的升级版,代码如下:
public double userSimilarity(long userID1, long userID2) throws TasteException {
DataModel dataModel = getDataModel();
FastIDSet prefs1 = dataModel.getItemIDsFromUser(userID1);
FastIDSet prefs2 = dataModel.getItemIDsFromUser(userID2);
long prefs1Size = prefs1.size();
long prefs2Size = prefs2.size();
//计算交集size
long intersectionSize =
prefs1Size < prefs2Size ? prefs2.intersectionSize(prefs1) : prefs1.intersectionSize(prefs2);
if (intersectionSize == 0) {
return Double.NaN;
}
long numItems = dataModel.getNumItems();
double logLikelihood =
LogLikelihood.logLikelihoodRatio(intersectionSize,
prefs2Size - intersectionSize,
prefs1Size - intersectionSize,
numItems - prefs1Size - prefs2Size + intersectionSize);
return 1.0 - 1.0 / (1.0 + logLikelihood);
}
3.CityBlockSimilarity
基于街区距离的相似度,代码如下:
public double userSimilarity(long userID1, long userID2) throws TasteException {
DataModel dataModel = getDataModel();
FastIDSet prefs1 = dataModel.getItemIDsFromUser(userID1);
FastIDSet prefs2 = dataModel.getItemIDsFromUser(userID2);
int prefs1Size = prefs1.size();
int prefs2Size = prefs2.size();
int intersectionSize = prefs1Size < prefs2Size ? prefs2.intersectionSize(prefs1) : prefs1.intersectionSize(prefs2);
return doSimilarity(prefs1Size, prefs2Size, intersectionSize);
}
//Calculate City Block Distance from total non-zero values and intersections and map to a similarity value.
private static double doSimilarity(int pref1, int pref2, int intersection) {
int distance = pref1 + pref2 - 2 * intersection;
return 1.0 / (1.0 + distance);
}
只继承AbstractItemSimilarity的实现类
1.TrackItemSimilarity
代码如下:
public double itemSimilarity(long itemID1, long itemID2) {
if (itemID1 == itemID2) {
return 1.0;
}
TrackData data1 = trackData.get(itemID1);
TrackData data2 = trackData.get(itemID2);
if (data1 == null || data2 == null) {
return 0.0;
}
// Arbitrarily decide that same album means "very similar"
if (data1.getAlbumID() != TrackData.NO_VALUE_ID && data1.getAlbumID() == data2.getAlbumID()) {
return 0.9;
}
// ... and same artist means "fairly similar"
if (data1.getArtistID() != TrackData.NO_VALUE_ID && data1.getArtistID() == data2.getArtistID()) {
return 0.7;
}
// Tanimoto coefficient similarity based on genre, but maximum value of 0.25
FastIDSet genres1 = data1.getGenreIDs();
FastIDSet genres2 = data2.getGenreIDs();
if (genres1 == null || genres2 == null) {
return 0.0;
}
int intersectionSize = genres1.intersectionSize(genres2);
if (intersectionSize == 0) {
return 0.0;
}
int unionSize = genres1.size() + genres2.size() - intersectionSize;
return (double) intersectionSize / (4.0 * unionSize);
}
2.HybridSimilarity
基于混合的相似度计算:LogLikelihoodSimilarity*TrackItemSimilarity。代码如下:
HybridSimilarity(DataModel dataModel, File dataFileDirectory) throws IOException {
super(dataModel);
cfSimilarity = new LogLikelihoodSimilarity(dataModel);
contentSimilarity = new TrackItemSimilarity(dataFileDirectory);
}
public double itemSimilarity(long itemID1, long itemID2) throws TasteException {
return contentSimilarity.itemSimilarity(itemID1, itemID2) * cfSimilarity.itemSimilarity(itemID1, itemID2);
}