上一篇:SQL Server2005杂谈(3):四个排名函数(row_number、rank、dense_rank和ntile)的比较
最近做一个项目,遇到一个在分组的情况下,将某一列的字段值(varchar类型)连接起来的问题,类似于sum函数对int型字段值求和。 如有一个表t_table,结构和数据如图1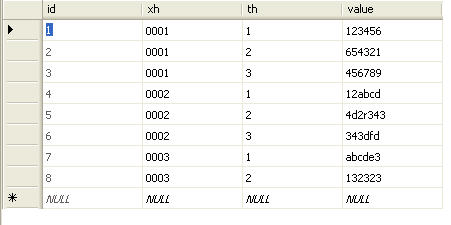
图1
其中要按着xh字段分组,并且将每一组name字段值连接起来。最终结果希望如图2所示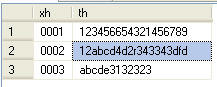
图2
表中的th字段值对于每一个xh值是唯一的,也是有限的,也就是说,对于一个xh值,th的值不会太多,如最多是10个(从1至10)。
以上需求最终想了三种方法来解决这个问题。
一、修改表结构
如果是新的项目,可以考虑修改一下表的结构。如果t_table的结构修改如下:
xh value1 value2 value3 value4 .... .... value10
0001 123456 654321 456789
0002 12abcd 4d2r343 343dfd
0003 abcde3 132323
这种方法将value的值纵向改为横向,也就是说,按每一个xh值,将value字段的值按逆时针旋转了90度。 但这种方法要有一个前提,就是假设xh的每一个值所对应的value值不会太多,如上面不超过10个,这样才有可能建立有限个字段。如果按着上面的字段结构,只需要将这些字段加一起就可以了,也不用分组。如下所示:
 +
value10)
as
value
from
t_table
+
value10)
as
value
from
t_table
但这种方法至少有如下三个缺陷:
1. 需要修改表结构,这对于已经进行很长时间或是已经上线的项目产不适用
2. 对每一个xh字段的value取值数有限制,如果太多,就得建立很多字段。这样性能会降低。
3. 这样做虽然查询容易,但如果需要对每一个xh的不同值频繁修改或加入新的值时,如果把它们都放到一行,容易因为行锁而降低性能。
二、动态生成select语句让我们先看三条 SQL 语句:
select xh,value as th2 from t_table where th = 2
select xh,value as th3 from t_table where th = 3
这三条语句分别使用 th 字段按着所有 th 可能的值来查询 t_table ,这三条 SQL 语句所查询出来的记录如图 3 所示。
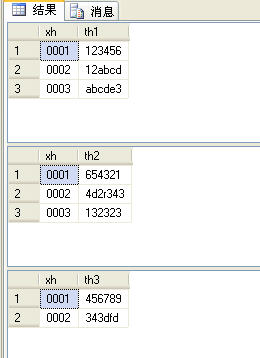
图 3
然后再使用下面的语句按着xh分组:
得到的结果如图 4 所示。
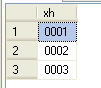
图4
然后使用left join,以图4所示的表为最左边的表,进行连接,SQL语句如下:

( select xh from t_table group by xh) a
left join
( select xh,value as th1 from t_table where th = 1 ) b on a.xh = b.xh
left join
( select xh,value as th2 from t_table where th = 2 ) c on a.xh = c.xh
left join
( select xh,value as th3 from t_table where th = 3 ) d on a.xh = d.xh
之所以使用 left join ,是因为按着 th 查询后,有的表的某些 xh 值可以没有,如图 3 中的第三个表,就没有 0003 。如果使用内连接, 0003 就无法在记录集中体现。这面的 SQL 的查询结果如图 5 所示。
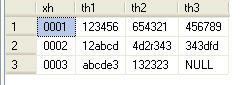
图5
然后我们就可以使用如下的语句来连接 th1 、 th2 和 th3 了。
myview表示将上面用left join的语句保存成的视图。
下面可以将这个过程写成一条 SQL 语句:
(
select a.xh, ( case when b.th1 is null then '' else b.th1 end ) as th1,
( case when c.th2 is null then '' else c.th2 end ) as th2,
( case when d.th3 is null then '' else d.th3 end ) as th3
from
( select xh from t_table group by xh) a
left join
( select xh,value as th1 from t_table where th = 1 ) b on a.xh = b.xh
left join
( select xh,value as th2 from t_table where th = 2 ) c on a.xh = c.xh
left join
( select xh,value as th3 from t_table where th = 3 ) d on a.xh = d.xh
) x
由于null加上任何字符串都为null,因此,使用case语句来将null转换为空串。上面的SQL就会得到图2所示的查询结果。也许有的读者会问,如果th的可能取值可变呢!如xh为0001的th值四个:1至4。 那上面的SQL不是要再加一个left join吗?这样不是很不通用。 要解决这个问题也很容易。可以使用程序(如C#、Java等)自动生成上述的SQL,然后由程序提交给数据库,再执行。 当然,这需要程序事先知道th值对于当前程序最多有几个值,然后才可以自动生成上述的SQL语句。
这种方法几乎适合于所有的数据库,不过如果 th 的取值比较多的话,可能 SQL 语句会很长,但是如果用程序自动生成的话,就不会管这些了。三、使用C#实现SQL Server2005的扩展聚合函数(当然,也可以用VB.NET)
这一种方法笔者认为是最“酷”的方法。因为每一个人都只想写如下的 SQL 语句就可以达到目录。
其中joinstr是一个聚合函数,功能是将每一组的某个字符串列的值首尾连接。上面的SQL也可以查询图2所示的结果。但遗憾的是,sql server2005并未提供可以连接字符串的聚合函数。下面我们就来使用C#来实现一个扩展聚合函数。
首先用 VS2008/VS2005 建立一个 SQL Server 项目,如图 6 所示。
图6
点击“确定”按钮后, SQL Server 项目会要求连接一个数据库,我们可以选择一个数据库,如图 7 所示。

图7
然后在工程中加入一个聚合类( joinstr.cs ),如图 8 所示。

图8
joinstr.cs 中的最终代码如下:
using System.Data;
using Microsoft.SqlServer.Server;
using System.Data.SqlTypes;
using System.IO;
using System.Text;
[Serializable]
[SqlUserDefinedAggregate(
Format.UserDefined, // use custom serialization to serialize the intermediate result
IsInvariantToNulls = true , // optimizer property
IsInvariantToDuplicates = false , // optimizer property
IsInvariantToOrder = false , // optimizer property
MaxByteSize = 8000 ) // maximum size in bytes of persisted value
]
public struct joinstr :IBinarySerialize
{
private System.Text.StringBuilder intermediateResult;
public void Init()
{
// 在此处放置代码
intermediateResult = new System.Text.StringBuilder();
}
public void Accumulate(SqlString Value)
{
intermediateResult.Append(Value.Value);
}
public void Merge(joinstr Group)
{
intermediateResult.Append(Group.intermediateResult);
}
public SqlString Terminate()
{
return new SqlString(intermediateResult.ToString());
}
public void Read(BinaryReader r)
{
intermediateResult = new StringBuilder(r.ReadString());
}
public void Write(BinaryWriter w)
{
w.Write( this .intermediateResult.ToString());
}
}
由于本例需要聚合字符串,而不是已经被序列化的类型,如int等,因此,需要实现IBinarySerialize接口来手动序列化。使用C#实现SQL Server聚合函数,也会受到字符串最大长度为8000的限制。
在编写完上述代码后,可以使用 Visual Studio 来部署(右向工程,在弹出菜单上选“部署”即可)。也可以使用 SQL 语句来部署。 假设上面的程序生成的 dll 为 MyAggregate.dll ,可以使用下面的 SQL 语句来部署:CREATE AGGREGATE joinstr ( @input nvarchar ( 200 )) RETURNS nvarchar ( max )
EXTERNAL NAME MyAgg.joinstr
要注意的是,字符串类型需要用nvarchar,而不能用varchar。
第一条SQL语句是装载dll,第二条SQL语句是注册joinstr聚合函数(每一个C#类就是一个聚合函数)
在执行上面的 SQL 语句之前,需要将 SQL Server2005 的 clr 功能打开。如图 9 所示。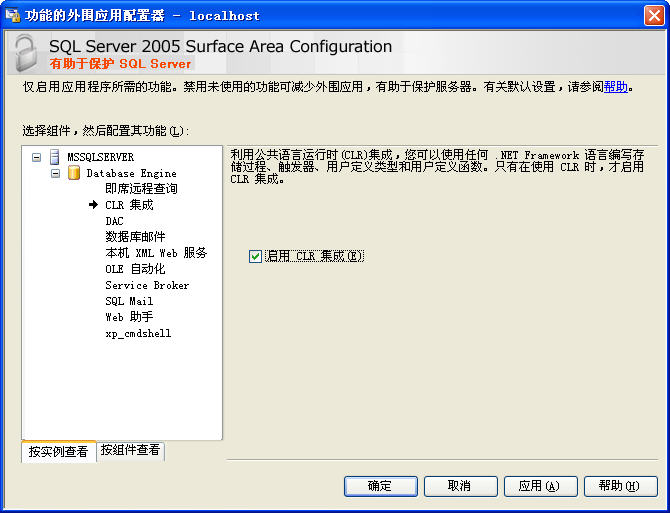
图9
如果想删除上面建立的聚合函数,可以使用如下的 SQL 语句:
在删除聚合函数后,可以将MyAggregate.dll卸载。
OK,现在可以使用joinstr来聚合字符串了。
这种方法虽然显示很“酷”,但却要求开发人员熟悉扩展聚合函数的开发方法,如果开发人员使有的不是微软的开发工具,如使用Java,恐怕这种方法就只能是空谈了(除非开发小组内有人会用微软的开发工具)。
当然,如果使用其他的数据库,如oracle、mysql,也是可以实现类似扩展函数的功能的,如oracle可以使用java来进行扩展。但这要求开发人员具有更高的素质。
以上介绍的三种方法仅供参考,至于采用哪种方法,可根据实际需要和具体情况而定。如果哪位读者有更好的方法,请跟贴!
下一篇:SQL Server2005杂谈(5):将聚合记录集逆时针和顺时针旋转90度
本文转自银河使者博客园博客,原文链接http://www.cnblogs.com/nokiaguy/archive/2008/06/25/1229594.html如需转载请自行联系原作者
银河使者
