《Windows Azure Platform 系列文章目录》
Azure SQL Database (19) Stretch Database 概览
Azure SQL Database (20) 使用SQL Server 2016 Upgrade Advisor
Azure SQL Database (21) 将整张表都迁移到Azure Stretch Database里
Azure SQL Database (22) 迁移部分数据到Azure Stretch Database
在之前的文档中,笔者介绍了如何迁移一张表的所有数据,到云端Stretch Database
Azure SQL Database (21) 将整张表都迁移到Azure Stretch Database里
在这里,笔者介绍如何将一张表里的部分数据,迁移到云端Stretch Database里。
更多的内容,请参考MSDN文章:https://msdn.microsoft.com/en-us/library/mt613432.aspx
准备工作:
1.如果你已经开始之前的练习,请删除之前在本地的Sample Database:AdventureWorks2016CTP3
2.登陆Azure China管理平台:https://manage.windowsazure.cn/,删除Stretch Database

3.重新还原AdventureWorks2016CTP3
基本定义:
我们可以在本地SQL Server 2016,创建以下方法Function
CREATE FUNCTION dbo.fn_stretchpredicate(@column1 datatype1, @column2 datatype2 [, ...n]) RETURNS TABLE WITH SCHEMABINDING AS RETURN SELECT 1 AS is_eligible WHERE <predicate>
返回值:
如果返回的值为非空(non-empty)的话,则这些返回结果会被迁移到云端Stretch Database。
剩下的值(即不在这些返回值中的内容),则会保留在本地SQL Server 2016
条件:
这里的条件,就是<predicate> 参数。
我们还是以数据库AdventureWorks2016CTP3,表Sales.OrderTracking为例。
1.首先打开本地计算机的SQL Server Management Studio(SSMS),运行以下脚本:
USE AdventureWorks2016CTP3 --Review the Data SELECT COUNT(*) FROM Sales.OrderTracking WHERE TrackingEventID <= 3 --Review the Data SELECT COUNT(*) FROM Sales.OrderTracking WHERE TrackingEventID > 3
可以看到,TrackingEventID <= 3的数据量为94364。TrackingEventID>3的数据量为94426。图略。
接下来的几个步骤,同之前的文档,主要作用是设置和打开归档功能。

--对本地SQL Server 2016,打开归档功能 EXEC sp_configure 'remote data archive' , '1'; RECONFIGURE; --对云端Azure SQL Database的用户名和密码,进行加密,加密的密码同SQL Database的密码: USE Adventureworks2016CTP3; CREATE MASTER KEY ENCRYPTION BY PASSWORD='Abc@123456' CREATE DATABASE SCOPED CREDENTIAL AzureDBCred WITH IDENTITY = 'sqladmin', SECRET = 'Abc@123456'; --将本地的SQL Server 2016的归档目标,指向到微软云SQL Database Server(l3cq1dckpd.database.chinacloudapi.cn) --这个l3cq1dckpd.database.chinacloudapi.cn,是我们在准备工作中,创建的新的服务器 ALTER DATABASE [AdventureWorks2016CTP3] SET REMOTE_DATA_ARCHIVE = ON (SERVER = 'l3cq1dckpd.database.chinacloudapi.cn', CREDENTIAL = AzureDBCred);
2.然后我们计划把TrackingEventID <= 3的值(一共94364行),都保存到云端Stretch Database。
3.我们在本机SSMS,执行以下T-SQL语句。创建FUNCTION
--Create Function CREATE FUNCTION dbo.fn_stretchpredicate(@status int) RETURNS TABLE WITH SCHEMABINDING AS RETURN SELECT 1 AS is_eligible WHERE @status <= 3;
4.开始迁移数据表中的部分数据
--Migrate Some Data to the Cloud ALTER TABLE Sales.OrderTracking SET (REMOTE_DATA_ARCHIVE = ON ( MIGRATION_STATE = OUTBOUND, FILTER_PREDICATE = dbo.fn_stretchpredicate(TrackingEventId)));
5.我们可以执行以下语句,查看归档数据迁移的进度
SELECT * from sys.dm_db_rda_migration_status
6.等待一段时间后,我们可以执行以下T-SQL语句
USE AdventureWorks2016CTP3 GO --显示本地数据行和数据容量 EXEC sp_spaceused 'Sales.OrderTracking', 'true', 'LOCAL_ONLY'; GO --显示云端Stretch Database的数据行和数据量 EXEC sp_spaceused 'Sales.OrderTracking', 'true', 'REMOTE_ONLY'; GO
执行结果:
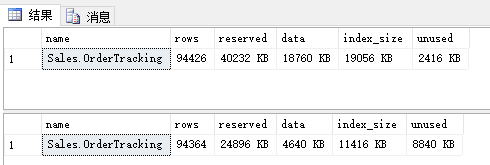
如上图所示:Sales.OrderTracking保存在本地的数据有94426行
Sales.OrderTracking保存在云端Stretch Database的数据有94364行
参考资料:https://msdn.microsoft.com/en-us/library/mt613432.aspx
本文转自Lei Zhang博客园博客,原文链接:http://www.cnblogs.com/threestone/p/5826450.html,如需转载请自行联系原作者

