Hive支持很多关系型数据库都支持的基本数据类型,还支持少有关系型数据库 的三种集合数据类型。 一个相关的问题是,在文本文件中,这些数据类型是如何展现的,或者说如何描 述文本的存储。相较于 大多数数据库,Hive有一个特性,即它在文本中数据的编码方式上提供了极大的 灵活性。大多数据库对 于数据在硬盘上的存储以及数据的生命周期都是完全控制的。为了让你控制这些 ,Hive提供了各种工具 使得对数据的管理和处理变得更加简单。
基本数据类型
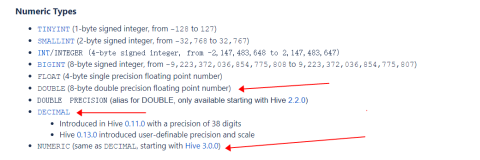
Hive支持各种长度的整型、浮点型、布尔型和任意长度的字符串类型。 Hive0.8.0添加了时间戳和二 进制类型。
表列出了Hive支持的基本数据类型

每一个类型都是在Java中执行的,所以数据类型的一些行为细节跟相应的Java 类型是一样的。例如, STRING是由Java String执行,FLOAT由 Java FLOAT执行,等等。
注意,跟其它SQL语言一样,Hive不支持最大长度限制的字符数组。关系型数 据库提供这个特点是为 了性能优化,因为固定长度的记录更容易查找、扫描等。而对于限制更为松散的 Hive,它可能不会包含 数据文件,并且对文件格式也相当灵活,Hive依赖于用于分割字段的分隔符。此 外,Hadoop和Hive都强 调优化硬盘的读写性能,所以相对而言,列值是否为固定长度就不那么重要了。
新数据类型TIMESTAMP的值可以是整型(从Unix纪元时间1970-01-01 00:00:00 开始计算秒数)、单精 度浮点型(从Unix纪元时间1970-01-01 00:00:00外加9位毫秒数开始计算秒数) 、字符串(根据JDBC日 期字符串格式约定YYYY-MM-DD hh:mm:ss.fffffffff被解释)。TIMESTAMP被解释 成UTC时间,为此,Hive 提供了转换时区的内置函数,to_utc_timestamp、from_utc_timestamp。
BINARY类型类似于其它关系型数据库中的VARBINARY类型,BINARY列示存储在 行中的,而不像BLOB (BINARYLARGEOBJECT)那样与行分开存储。BINARY的一个用途是,其在一行中包 含任意字节以防止Hive 将其分列成为数值或字符串等。
注意,如果你的目的是忽略每一行的结尾部分,那么你不需要BINARY。如果一 个表的表模式定义了3 个列,而数据文件的每一行包含5个值,Hive将会忽略最后两个值。
假设你现在运行这样一个查询:比较单精度浮点列和双精度浮点列,或比较两 种不同的整型。Hive隐 式的将一个整型转换成更大的整型,将FLOAT转换成DOUBLE,转换任意整型成 DOUBLE;
假设你现在运行这样一个查询:将字符串列翻译成数值类型。Hive可以进行显 式转换,例如,s是 STRING类型,转换成整型:cast(s AS INT)。
集合类型
Hive支持structs,maps,arrays这三种集合类型。
表列出了Hive支持的集合类型

因为使用集合类型会破坏范式,所以大多数关系型数据库不支持这样的集合类 型。例如,在传统的数 据模型中,struct可能会被多个具有外键关系的表存储。破坏范式的实际问题即 造成了数据冗余,以致 于耗费不必要的硬盘空间,且当数据发生改变的时候,将导致冗余数据存在潜在 的数据不一致。然而, 大数据系统,牺牲范式以获得更高的计算吞吐量。当处理TB、PB级的数据时,最 快的磁盘磁头寻道是必 要的,记录中嵌入的集合可以获得更短的寻道时间,而寻找外键关系需要花费更 多的寻道时间。
注:Hive没有各类“键”(指主外键等)的概念,可以通过 “索引”实现其功 能。
以下是一个表声明,描述了如何使用这些类型,假设employee表在虚构的HR应 用中:
CREATE TABLE employees(
name STRING,
salary FLOAT,
subordinates ARRAY<STRING>,
deductions MAP<STRING,FLOAT>,
address STRUCT<street:STRING,city:STRING,state:STRING,zip:INT>);
name是员工们的简单字符串,float类型对于工资大小足够了,subordinates 列表是一组字符串值, 表示其下属(这里起到的作用是将name作为主键,所以subordinates中的每一个 元素都引用到表中的另 一个记录,没有下级员工的记录处为空数组),在传统模型中,“关系 ”将会从员工到其经 理建立相应的外键。
deductions是包含一个键值对的映射类型,表示从工资中扣税的部分。键即扣 税名称,值即百分比值 或绝对数值。在传统模型中,则用多个表记录不同的扣税类型,这些表的行通常 都包含了扣税值和一个 指向相应员工记录的外键。
address是员工的家庭地址,用struct表示,其域有“街道”、 “城市”、 “州”、“邮政编码”,并分别有各自的数据类型。
集合类型遵循Java对于泛型的语法规定。例如,MAP<STRING,FLOAT>表 示映射中的每一个键都 是STRING类型,每一个值都是FLOAT类型。ARRAY<STRING>表示数组中的每 一个元素都是STRING类 型。STRUCT可以是包括各种类型,但是STRUCT中各位置上的数据类型必须与定义 的相同。
数据值的文本文件编码
下面通过最简单的文本文件来开始探寻Hive的文件格式。毫无疑问,你肯定很 熟悉以逗号(,)或者 制表符作为分隔符的文本文件,即所谓的CSV和TSV,Hive支持这些格式,但是此 两者的缺点在于,不用 于作为分隔符的逗号和制表符可能内嵌在文本中,因此,HIve默认使用了其它的 字符(这些字符基本很 少的出现在字符串值当中)。
查看本栏目更多精彩内容:http://www.bianceng.cn/database/extra/
表列出了Hive默认的分隔符

前面声明的employee表就是以^A作为行分隔符。类似于Emacs的文本编辑器将 会以如下形式表示分隔 符(由于文本的一行超过了这里一行的长度,所以这里以空白行作为行的标识):
John Doe^A100000.0^AMary Smith^BTodd Jones^AFederal Taxes^C.2^BState Taxes^C.05^BInsurance^C.1^A1 Michigan Ave.^BChicago^BIL^B60600
Mary Smith^A80000.0^ABill King^AFederal Taxes^C.2BState Taxes^C.05BInsurance^C.1^A100 Ontario St.^BChicago^BIL^B60601
Todd Jones^A70000.0^AFederal Taxes^C.15^BState Taxes^C.03^BInsurance^C.1^A200 Chicago Ave.^BOak Park^BIL^B60700
Bill King^A60000.0^AFederal Taxes^C.15^BState Taxes^C.03^BInsurance^C.1^A300 Obscure Dr.^BObscuria^BIL^B60100
这样的文本阅读起来挺麻烦的,但是可以让Hive去做这个事,接下来从第一行 入手来了解分隔符在文 本文件中的作用。首先,这种格式有点像如下的JSON (JavaScriptObjectNotation)格式:
{
“name”:”john Doe”,
“salary”:100000.0,
“subordinates”:["Mary Smith","Todd Jones"],
“deductions”:{
“Federal Taxes”:.2,
“State Taxes”: .05,
“Insurance”: .1
},
“address”:{
“street”:”1 Michigan Ave.”,
“city”:”Chicago”,
“state”: “IL”,
“zip”:60600
}
}
以下是文本第一行的拆分:
John Doe是名字
100000.0是工资
Mary Smith^BTodd Jones是下属Mary Smith和Todd Jones
Federal Taxes^C.2^BState Taxes^C.05^BInsurance^C.1是扣税, “Federal Taxes”扣 20%,“State Taxes”扣5%,“Insurance”扣10%
1 Michigan Ave.^BChicago^BIL^B60600是地址
你也可以重写默认分隔符,在某些应用程序写数据时使用了不同的分隔给定时 ,重写分隔符是非常必 要的。以下是相同的表定义,并且添加了默认分隔符的明确指定:
CREATE TABLE employees(
name STRING,
salary FLOAT,
subordinates ARRAY<STRING>,
deductions MAP<STRING,FLOAT>,
address STRUCT<street:STRING,city:STRING,state:STRING,zip:INT>
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘\001′
COLLECTION ITEMS TERMINATED BY ‘\002′
MAP KEYS TERMINATED BY ‘\003′
LINES TERMINATED BY ‘\n’
STORED AS TEXTFILE;
以上定义中,ROW FORMAT语句必须出现在其它语句之前,STORED AS…语句除 外。
字符’\001’是^A的八进制,ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\001’意即Hive使用^A分隔字段。
类似的,’\002’是^B的八进制,ROW FORMAT DELIMITEDCOLLECTION ITEMS TERMINATED BY ‘\002’意即Hive使用^B分隔集合元素。
最后,’\003’是^C的八进制,ROW FORMAT DELIMITEDMAP KEYS TERMINATED BY ‘\003’意即Hive使用^C分隔map的键和值。
LINES TERMINATED BY … STORED AS …语句标识行分隔符,其不要求前面 加上ROW FORMAT DELIMITED关键字。
事实上,Hive目前不支持除’\n’以外的任何字符作为行分隔符。
你可以重写字段、集合以及键和值的分隔符,也可以沿用Hive的默认分隔符, STORED AS TEXTFILE极 少用到,因为此书中,将默认使用TEXTFILE文件格式。有其他可选文件格式,这 将在第15章中讨论,其 中相关的如文件的压缩将在后续的第11章中讨论。
所以,在你明确声明所有的这些语句时,最好在大多数情况下使用默认分隔符 ,通常只需要提供需要 被重写的部分。这些声明只会影响到Hive在读数据文件时所扫描的内容。除非在 某些特殊限制情况下, 你最好以正确的格式写入数据。例如,以下是以逗号最为字段分隔符的表定义:
CREATE TABLE some_data(
first FLOAT,
second FLOAT,
third FLOAT,
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘,';
以制表符作为分隔符时用’\t’,这种强大的定制化特点,使得在使用 Hive结合其它创建文件的 工具以及各种ETL(Extract,Transform,Load)处理过程时更加容易和方便。
读模式
向传统数据库中写数据方式,有加载外数据、写入查询的结果,做更新等,数 据库在数据存储上有绝 对的控制权,数据库就像是一个守门员,这也就意味着数据库的控制是可以以 “数据已写入 ”的方式执行模式。
Hive在基本的存储上没有这样类似的控制权,有很多方式创建、修改甚至毁坏 Hive将要查询的数据数 据,因此,Hive只能以“读”的方式执行查询,这就是“读模式 ”。
这样一来,如果模式和文件内容不匹配怎么办?Hive会尽其所能的读取数据,如果 文件中的每一行没有足 够的字段匹配模式的话,Hive会将后面的字段补成
NULL。如果某些字段是数值类型,而Hive读到相应的位置为非数值的字符串,此 时,Hive将为这些字段 返回NULL,另外很重要的一点是,Hive
会尽可能的尝试从所有错误中进行恢复。