cpu_relax()-----对自选循环等待(spin-wait loops)操作的优化
转自:http://www.doc100.net/bugs/t/173547/index.html
在lock_timer_base()函数中看到在for循环操作中调用了cpu_relax(),本来以为是要让出CPU,调度其他进程运行,但是看代码之后发现完全不是这么回事。cpu_relax()中只有一条调用语句,调用的是rep_nop函数。rep_nop()函数如下:
static inline void rep_nop(void)
{
asm volatile("rep; nop" ::: "memory");
}
只有一条简单的汇编语句,原来在论坛里看到过这条汇编语句,不是重复执行nop指令,"rep; nop"指令会被翻译成pause指令,到底是不是这样呢?反汇编一下看看,c代码如下:
#include <stdio.h>
static inline void rep_nop(void)
{
asm volatile("rep; nop" ::: "memory");
}
int main(void)
{
rep_nop();
return 0;
}
文件名保存在nop.c,使用gcc编译成目标文件nop.o,命令如下:
gcc -c nop.c
使用objdump来反汇编,命令如下:
objdump -s -d nop.o
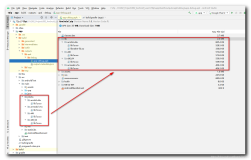
反汇编的结果如下图所示:

从图中可以看出"rep; nop"指令被翻译成pause指令,因此实际上rep_nop()函数执行了一次pause指令。关于这条指令,intel的指令手册《Instruction Set Reference, M-Z》中讲的比较详细,这里总结一下。
pause指令的作用是:
1)提升spin-wait loops(自旋循环等待)的性能。在执行一个 spin-wait loops时,Pentium4处理会遇到严重的性能损失,因为在循环退出时,处理器会检测到一个可能的内存顺序冲突。pause指令会向处理器提供一种提示,告诉处理器当前所执行的代码序列是一个spin-wait loop操作。大多数情况下,处理器会根据这个提示避开内存序列冲突,从而提高处理器的性能。正是基于此,建议在spin-wait loop中使用pause指令。
2)pause指令的另外一个功能是让Pentium4处理器在执行spin-wait loop时可以减少电源的消耗。在等待资源而执行自旋等待时,Pentium4处理器以极快的速度执行自旋等待操作时,将会消耗很多电能,但使用pause指令则可以极大地减少处理器的电源消耗。
PAUSE 指令在 Pentium4 处理器中引入,但它也是向前兼容的。在早先的 IA-32 处理器里,PAUSE 指令实际上就相当于 NOP 指令。Pentium4 处理器以一种 预延迟(pre-defined delay)的技术来实现 PAUSE 指令。这种延迟也是有限度的,并且在一些处理器上是零延迟。该指令不会改变处理器的处理器的状态。
上面还提到一个概念就是内存顺序冲突(Memory order violation)。内存顺序冲突一般是由假共享引起,假共享是指多个CPU同时修改同一个缓存行的不同部分而引起的一个CPU的操作无效,当出现这个内存顺序冲突时,CPU必须清空流水线。
参考资料:
聊聊并发(五)——原子操作的实现原理
http://www.groad.net/bbs/read.php?tid-3373.html
本文转自张昺华-sky博客园博客,原文链接:http://www.cnblogs.com/sky-heaven/p/5433830.html,如需转载请自行联系原作者